


? 作者:韩信子@ShowMeAI
? 深度学习实战系列:https://www.showmeai.tech/tutorials/42
? TensorFlow 实战系列:https://www.showmeai.tech/tutorials/43
? 本文地址:https://www.showmeai.tech/article-detail/315
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容

自 Transformers 出现以来,基于它的结构已经颠覆了自然语言处理和计算机视觉,带来各种非结构化数据业务场景和任务的巨大效果突破,接着大家把目光转向了结构化业务数据,它是否能在结构化表格数据上同样有惊人的效果表现呢?
答案是YES!亚马逊在论文中提出的 ?TabTransformer,是一种把结构调整后适应于结构化表格数据的网络结构,它更擅长于捕捉传统结构化表格数据中不同类型的数据信息,并将其结合以完成预估任务。下面ShowMeAI给大家讲解构建 TabTransformer 并将其应用于结构化数据上的过程。

? 环境设置
本篇使用到的深度学习框架为TensorFlow,大家需要安装2.7或更高版本, 我们还需要安装一下 ?TensorFlow插件addons,安装的过程大家可以通过下述命令完成:
pip install -U tensorflow tensorflow-addons

关于本篇代码实现中使用到的TensorFlow工具库,大家可以查看ShowMeAI制作的TensorFlow速查手册快学快用:
接下来我们导入工具库
import math
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_addons as tfa
import matplotlib.pyplot as plt
? 数据说明
ShowMeAI在本例中使用到的是 ?美国人口普查收入数据集,任务是根据人口基本信息预测其年收入是否可能超过 50,000 美元,是一个二分类问题。
数据集可以在以下地址下载:
? https://archive.ics.uci.edu/ml/datasets/Adult
? https://archive.ics.uci.edu/ml/machine-learning-databases/adult/
数据从美国1994年人口普查数据库抽取而来,可以用来预测居民收入是否超过50K/year。该数据集类变量为年收入是否超过50k,属性变量包含年龄、工种、学历、职业、人种等重要信息,值得一提的是,14个属性变量中有7个类别型变量。数据集各属性是:其中序号0~13是属性,14是类别。
| 字段序号 | 字段名 | 含义 | 类型 |
|---|---|---|---|
| 0 | age | 年龄 | Double |
| 1 | workclass | 工作类型* | string |
| 2 | fnlwgt | 序号 | string |
| 3 | education | 教育程度* | string |
| 4 | education_num | 受教育时间 | double |
| 5 | maritial_status | 婚姻状况* | string |
| 6 | occupation | 职业* | string |
| 7 | relationship | 关系* | string |
| 8 | race | 种族* | string |
| 9 | sex | 性别* | string |
| 10 | capital_gain | 资本收益 | string |
| 11 | capital_loss | 资本损失 | string |
| 12 | hours_per_week | 每周工作小时数 | double |
| 13 | native_country | 原籍* | string |
| 14(label) | income | 收入标签 | string |
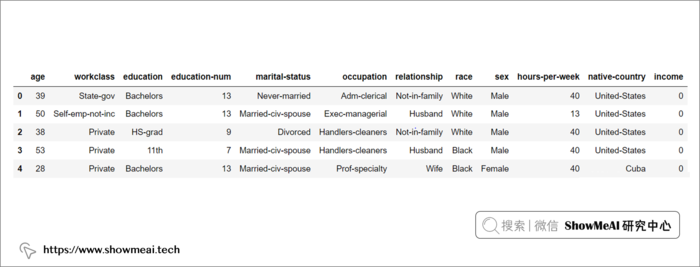
我们先用pandas读取数据到dataframe中:
CSV_HEADER = [
"age",
"workclass",
"fnlwgt",
"education",
"education_num",
"marital_status",
"occupation",
"relationship",
"race",
"gender",
"capital_gain",
"capital_loss",
"hours_per_week",
"native_country",
"income_bracket",
]
train_data_url = (
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
)
train_data = pd.read_csv(train_data_url, header=None, names=CSV_HEADER)
test_data_url = (
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test"
)
test_data = pd.read_csv(test_data_url, header=None, names=CSV_HEADER)
print(f"Train dataset shape: {train_data.shape}")
print(f"Test dataset shape: {test_data.shape}")
Train dataset shape: (32561, 15)
Test dataset shape: (16282, 15)
我们做点数据清洗,把测试集第一条记录剔除(它不是有效的数据示例),把类标签中的尾随的“点”去掉。
test_data = test_data[1:]
test_data.income_bracket = test_data.income_bracket.apply(
lambda value: value.replace(".", "")
)
再把训练集和测试集存回单独的 CSV 文件中。
train_data_file = "train_data.csv"
test_data_file = "test_data.csv"
train_data.to_csv(train_data_file, index=False, header=False)
test_data.to_csv(test_data_file, index=False, header=False)
? 模型原理
TabTransformer的模型架构如下所示:
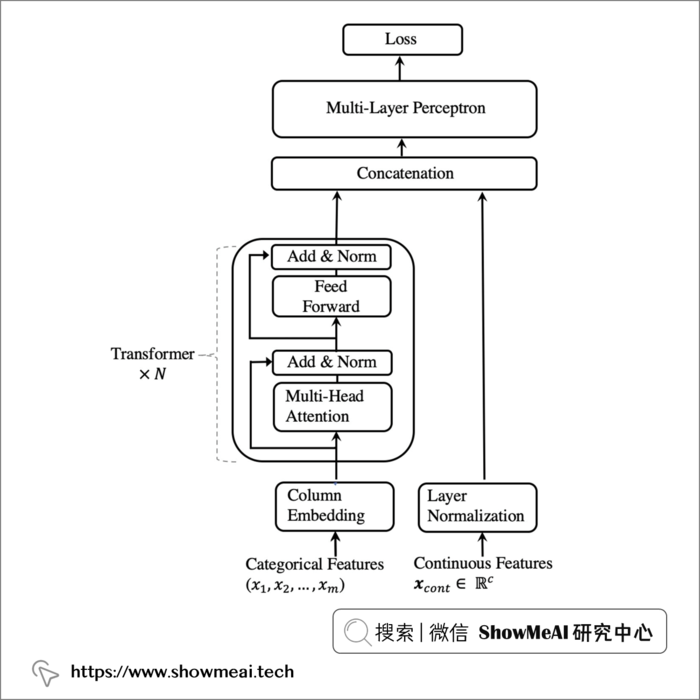
我们可以看到,类别型的特征,很适合在 embedding 后,送入 transformer 模块进行深度交叉组合与信息挖掘,得到的信息与右侧的连续值特征进行拼接,再送入全连接的 MLP 模块进行组合和完成最后的任务(分类或者回归)。
? 模型实现
? 定义数据集元数据
要实现模型,我们先对输入数据字段,区分不同的类型(数值型特征与类别型特征)。我们会对不同类型的特征,使用不同的方式进行处理和完成特征工程(例如数值型的特征进行幅度缩放,类别型的特征进行编码处理)。
## 数值特征字段
NUMERIC_FEATURE_NAMES = [
"age",
"education_num",
"capital_gain",
"capital_loss",
"hours_per_week",
]
## 类别型特征字段及其取值列表
CATEGORICAL_FEATURES_WITH_VOCABULARY = {
"workclass": sorted(list(train_data["workclass"].unique())),
"education": sorted(list(train_data["education"].unique())),
"marital_status": sorted(list(train_data["marital_status"].unique())),
"occupation": sorted(list(train_data["occupation"].unique())),
"relationship": sorted(list(train_data["relationship"].unique())),
"race": sorted(list(train_data["race"].unique())),
"gender": sorted(list(train_data["gender"].unique())),
"native_country": sorted(list(train_data["native_country"].unique())),
}
## 权重字段
WEIGHT_COLUMN_NAME = "fnlwgt"
## 类别型字段名称
CATEGORICAL_FEATURE_NAMES = list(CATEGORICAL_FEATURES_WITH_VOCABULARY.keys())
## 所有的输入特征
FEATURE_NAMES = NUMERIC_FEATURE_NAMES + CATEGORICAL_FEATURE_NAMES
## 默认填充的取值
COLUMN_DEFAULTS = [
[0.0] if feature_name in NUMERIC_FEATURE_NAMES + [WEIGHT_COLUMN_NAME] else ["NA"]
for feature_name in CSV_HEADER
]
## 目标字段
TARGET_FEATURE_NAME = "income_bracket"
## 目标字段取值
TARGET_LABELS = [" <=50K", " >50K"]
? 配置超参数
我们为神经网络的结构和训练过程的超参数进行设置,如下。
# 学习率
LEARNING_RATE = 0.001
# 学习率衰减
WEIGHT_DECAY = 0.0001
# 随机失活 概率参数
DROPOUT_RATE = 0.2
# 批数据大小
BATCH_SIZE = 265
# 总训练轮次数
NUM_EPOCHS = 15
# transformer块的数量
NUM_TRANSFORMER_BLOCKS = 3
# 注意力头的数量
NUM_HEADS = 4
# 类别型embedding嵌入的维度
EMBEDDING_DIMS = 16
# MLP隐层单元数量
MLP_HIDDEN_UNITS_FACTORS = [
2,
1,
]
# MLP块的数量
NUM_MLP_BLOCKS = 2
? 实现数据读取管道
下面我们定义一个输入函数,它负责读取和解析文件,并对特征和标签处理,放入 tf.data.Dataset,以便后续训练和评估。
target_label_lookup = layers.StringLookup(
vocabulary=TARGET_LABELS, mask_token=None, num_oov_indices=0
)
def prepare_example(features, target):
target_index = target_label_lookup(target)
weights = features.pop(WEIGHT_COLUMN_NAME)
return features, target_index, weights
# 从csv中读取数据
def get_dataset_from_csv(csv_file_path, batch_size=128, shuffle=False):
dataset = tf.data.experimental.make_csv_dataset(
csv_file_path,
batch_size=batch_size,
column_names=CSV_HEADER,
column_defaults=COLUMN_DEFAULTS,
label_name=TARGET_FEATURE_NAME,
num_epochs=1,
header=False,
na_value="?",
shuffle=shuffle,
).map(prepare_example, num_parallel_calls=tf.data.AUTOTUNE, deterministic=False)
return dataset.cache()
? 模型构建与评估
def run_experiment(
model,
train_data_file,
test_data_file,
num_epochs,
learning_rate,
weight_decay,
batch_size,
):
# 优化器
optimizer = tfa.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
)
# 模型编译
model.compile(
optimizer=optimizer,
loss=keras.losses.BinaryCrossentropy(),
metrics=[keras.metrics.BinaryAccuracy(name="accuracy")],
)
# 训练集与验证集
train_dataset = get_dataset_from_csv(train_data_file, batch_size, shuffle=True)
validation_dataset = get_dataset_from_csv(test_data_file, batch_size)
# 模型训练
print("Start training the model...")
history = model.fit(
train_dataset, epochs=num_epochs, validation_data=validation_dataset
)
print("Model training finished")
# 模型评估
_, accuracy = model.evaluate(validation_dataset, verbose=0)
print(f"Validation accuracy: {round(accuracy * 100, 2)}%")
return history
① 创建模型输入
基于 TensorFlow 的输入要求,我们将模型的输入定义为字典,其中『key/键』是特征名称,『value/值』为 keras.layers.Input具有相应特征形状的张量和数据类型。
def create_model_inputs():
inputs = {}
for feature_name in FEATURE_NAMES:
if feature_name in NUMERIC_FEATURE_NAMES:
inputs[feature_name] = layers.Input(
name=feature_name, shape=(), dtype=tf.float32
)
else:
inputs[feature_name] = layers.Input(
name=feature_name, shape=(), dtype=tf.string
)
return inputs
② 编码特征
我们定义一个encode_inputs函数,返回encoded_categorical_feature_list和 numerical_feature_list。我们将分类特征编码为嵌入,使用固定的embedding_dims对于所有功能, 无论他们的词汇量大小。 这是 Transformer 模型所必需的。
def encode_inputs(inputs, embedding_dims):
encoded_categorical_feature_list = []
numerical_feature_list = []
for feature_name in inputs:
if feature_name in CATEGORICAL_FEATURE_NAMES:
# 获取类别型特征的不同取值(vocabulary)
vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY[feature_name]
# 构建lookup table去构建 类别型取值 和 索引 的相互映射
lookup = layers.StringLookup(
vocabulary=vocabulary,
mask_token=None,
num_oov_indices=0,
output_mode="int",
)
# 类别型字符串取值 转为 整型索引
encoded_feature = lookup(inputs[feature_name])
# 构建embedding层
embedding = layers.Embedding(
input_dim=len(vocabulary), output_dim=embedding_dims
)
# 为索引构建embedding嵌入
encoded_categorical_feature = embedding(encoded_feature)
encoded_categorical_feature_list.append(encoded_categorical_feature)
else:
# 数值型特征
numerical_feature = tf.expand_dims(inputs[feature_name], -1)
numerical_feature_list.append(numerical_feature)
return encoded_categorical_feature_list, numerical_feature_list
③ MLP模块实现
网络中不可或缺的部分是 MLP 全连接板块,下面是它的简单实现:
def create_mlp(hidden_units, dropout_rate, activation, normalization_layer, name=None):
mlp_layers = []
for units in hidden_units:
mlp_layers.append(normalization_layer),
mlp_layers.append(layers.Dense(units, activation=activation))
mlp_layers.append(layers.Dropout(dropout_rate))
return keras.Sequential(mlp_layers, name=name)
④ 模型实现1:基线模型
为了对比效果,我们先简单使用MLP(多层前馈网络)进行建模,代码和注释如下。
def create_baseline_model(
embedding_dims, num_mlp_blocks, mlp_hidden_units_factors, dropout_rate
):
# 创建输入.
inputs = create_model_inputs()
# 特征编码
encoded_categorical_feature_list, numerical_feature_list = encode_inputs(
inputs, embedding_dims
)
# 拼接所有特征
features = layers.concatenate(
encoded_categorical_feature_list + numerical_feature_list
)
# 前向计算
feedforward_units = [features.shape[-1]]
# 构建全连接,并且添加跳跃连接(skip-connection)
for layer_idx in range(num_mlp_blocks):
features = create_mlp(
hidden_units=feedforward_units,
dropout_rate=dropout_rate,
activation=keras.activations.gelu,
normalization_layer=layers.LayerNormalization(epsilon=1e-6),
name=f"feedforward_{layer_idx}",
)(features)
# MLP全连接的隐层结果
mlp_hidden_units = [
factor * features.shape[-1] for factor in mlp_hidden_units_factors
]
# 最终的MLP网络
features = create_mlp(
hidden_units=mlp_hidden_units,
dropout_rate=dropout_rate,
activation=keras.activations.selu,
normalization_layer=layers.BatchNormalization(),
name="MLP",
)(features)
# 添加sigmoid构建二分类器
outputs = layers.Dense(units=1, activation="sigmoid", name="sigmoid")(features)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
# 完整的模型
baseline_model = create_baseline_model(
embedding_dims=EMBEDDING_DIMS,
num_mlp_blocks=NUM_MLP_BLOCKS,
mlp_hidden_units_factors=MLP_HIDDEN_UNITS_FACTORS,
dropout_rate=DROPOUT_RATE,
)
print("Total model weights:", baseline_model.count_params())
keras.utils.plot_model(baseline_model, show_shapes=True, rankdir="LR")
# Total model weights: 109629
上述模型构建完成之后,我们通过plot_model操作,绘制出模型结构如下:
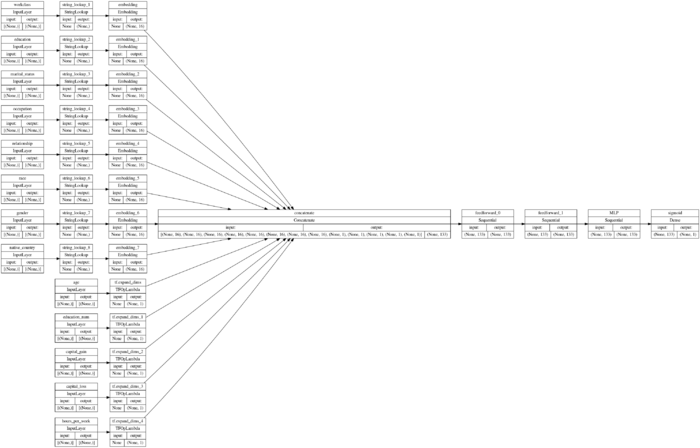 |
接下来我们训练和评估一下基线模型:
history = run_experiment(
model=baseline_model,
train_data_file=train_data_file,
test_data_file=test_data_file,
num_epochs=NUM_EPOCHS,
learning_rate=LEARNING_RATE,
weight_decay=WEIGHT_DECAY,
batch_size=BATCH_SIZE,
)
输出的训练过程日志如下:
Start training the model...
Epoch 1/15
123/123 [==============================] - 6s 25ms/step - loss: 110178.8203 - accuracy: 0.7478 - val_loss: 92703.0859 - val_accuracy: 0.7825
Epoch 2/15
123/123 [==============================] - 2s 14ms/step - loss: 90979.8125 - accuracy: 0.7675 - val_loss: 71798.9219 - val_accuracy: 0.8001
Epoch 3/15
123/123 [==============================] - 2s 14ms/step - loss: 77226.5547 - accuracy: 0.7902 - val_loss: 68581.0312 - val_accuracy: 0.8168
Epoch 4/15
123/123 [==============================] - 2s 14ms/step - loss: 72652.2422 - accuracy: 0.8004 - val_loss: 70084.0469 - val_accuracy: 0.7974
Epoch 5/15
123/123 [==============================] - 2s 14ms/step - loss: 71207.9375 - accuracy: 0.8033 - val_loss: 66552.1719 - val_accuracy: 0.8130
Epoch 6/15
123/123 [==============================] - 2s 14ms/step - loss: 69321.4375 - accuracy: 0.8091 - val_loss: 65837.0469 - val_accuracy: 0.8149
Epoch 7/15
123/123 [==============================] - 2s 14ms/step - loss: 68839.3359 - accuracy: 0.8099 - val_loss: 65613.0156 - val_accuracy: 0.8187
Epoch 8/15
123/123 [==============================] - 2s 14ms/step - loss: 68126.7344 - accuracy: 0.8124 - val_loss: 66155.8594 - val_accuracy: 0.8108
Epoch 9/15
123/123 [==============================] - 2s 14ms/step - loss: 67768.9844 - accuracy: 0.8147 - val_loss: 66705.8047 - val_accuracy: 0.8230
Epoch 10/15
123/123 [==============================] - 2s 14ms/step - loss: 67482.5859 - accuracy: 0.8151 - val_loss: 65668.3672 - val_accuracy: 0.8143
Epoch 11/15
123/123 [==============================] - 2s 14ms/step - loss: 66792.6875 - accuracy: 0.8181 - val_loss: 66536.3828 - val_accuracy: 0.8233
Epoch 12/15
123/123 [==============================] - 2s 14ms/step - loss: 65610.4531 - accuracy: 0.8229 - val_loss: 70377.7266 - val_accuracy: 0.8256
Epoch 13/15
123/123 [==============================] - 2s 14ms/step - loss: 63930.2500 - accuracy: 0.8282 - val_loss: 68294.8516 - val_accuracy: 0.8289
Epoch 14/15
123/123 [==============================] - 2s 14ms/step - loss: 63420.1562 - accuracy: 0.8323 - val_loss: 63050.5859 - val_accuracy: 0.8204
Epoch 15/15
123/123 [==============================] - 2s 14ms/step - loss: 62619.4531 - accuracy: 0.8345 - val_loss: 66933.7500 - val_accuracy: 0.8177
Model training finished
Validation accuracy: 81.77%
我们可以看到基线模型(全连接MLP网络)实现了约 82% 的验证准确度。
⑤ 模型实现2:TabTransformer
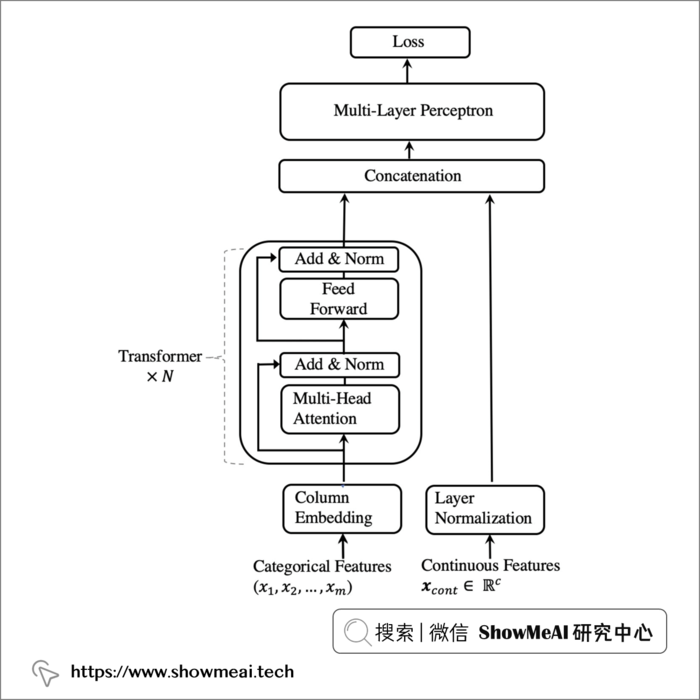
TabTransformer 架构的工作原理如下:
- 所有类别型特征都被编码为嵌入,使用相同的
embedding_dims。 - 将列嵌入(每个类别型特征的一个嵌入向量)添加类别型特征嵌入中。
- 嵌入的类别型特征被输入到一系列的 Transformer 块中。 每个 Transformer 块由一个多头自注意力层和一个前馈层组成。
- 最终 Transformer 层的输出, 与输入的数值型特征连接,并输入到最终的 MLP 块中。
- 尾部由一个
softmax结构完成分类。
def create_tabtransformer_classifier(
num_transformer_blocks,
num_heads,
embedding_dims,
mlp_hidden_units_factors,
dropout_rate,
use_column_embedding=False,
):
# 构建输入
inputs = create_model_inputs()
# 编码特征
encoded_categorical_feature_list, numerical_feature_list = encode_inputs(
inputs, embedding_dims
)
# 堆叠类别型特征的embeddings,为输入Tansformer做准备
encoded_categorical_features = tf.stack(encoded_categorical_feature_list, axis=1)
# 拼接数值型特征
numerical_features = layers.concatenate(numerical_feature_list)
# embedding
if use_column_embedding:
num_columns = encoded_categorical_features.shape[1]
column_embedding = layers.Embedding(
input_dim=num_columns, output_dim=embedding_dims
)
column_indices = tf.range(start=0, limit=num_columns, delta=1)
encoded_categorical_features = encoded_categorical_features + column_embedding(
column_indices
)
# 构建Transformer块
for block_idx in range(num_transformer_blocks):
# 多头自注意力
attention_output = layers.MultiHeadAttention(
num_heads=num_heads,
key_dim=embedding_dims,
dropout=dropout_rate,
name=f"multihead_attention_{block_idx}",
)(encoded_categorical_features, encoded_categorical_features)
# 第1个跳接/Skip connection
x = layers.Add(name=f"skip_connection1_{block_idx}")(
[attention_output, encoded_categorical_features]
)
# 第1个层归一化/Layer normalization
x = layers.LayerNormalization(name=f"layer_norm1_{block_idx}", epsilon=1e-6)(x)
# 全连接层
feedforward_output = create_mlp(
hidden_units=[embedding_dims],
dropout_rate=dropout_rate,
activation=keras.activations.gelu,
normalization_layer=layers.LayerNormalization(epsilon=1e-6),
name=f"feedforward_{block_idx}",
)(x)
# 第2个跳接/Skip connection
x = layers.Add(name=f"skip_connection2_{block_idx}")([feedforward_output, x])
# 第2个层归一化/Layer normalization
encoded_categorical_features = layers.LayerNormalization(
name=f"layer_norm2_{block_idx}", epsilon=1e-6
)(x)
# 展平embeddings
categorical_features = layers.Flatten()(encoded_categorical_features)
# 对数值型特征做层归一化
numerical_features = layers.LayerNormalization(epsilon=1e-6)(numerical_features)
# 拼接作为最终MLP的输入
features = layers.concatenate([categorical_features, numerical_features])
# 计算MLP隐层单元
mlp_hidden_units = [
factor * features.shape[-1] for factor in mlp_hidden_units_factors
]
# 构建最终的MLP.
features = create_mlp(
hidden_units=mlp_hidden_units,
dropout_rate=dropout_rate,
activation=keras.activations.selu,
normalization_layer=layers.BatchNormalization(),
name="MLP",
)(features)
# 添加sigmoid构建二分类
outputs = layers.Dense(units=1, activation="sigmoid", name="sigmoid")(features)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
tabtransformer_model = create_tabtransformer_classifier(
num_transformer_blocks=NUM_TRANSFORMER_BLOCKS,
num_heads=NUM_HEADS,
embedding_dims=EMBEDDING_DIMS,
mlp_hidden_units_factors=MLP_HIDDEN_UNITS_FACTORS,
dropout_rate=DROPOUT_RATE,
)
print("Total model weights:", tabtransformer_model.count_params())
keras.utils.plot_model(tabtransformer_model, show_shapes=True, rankdir="LR")
#Total model weights: 87479
最终输出的模型结构示意图如下(因为模型结构较深,总体很长,点击放大)
 |
下面我们训练和评估一下TabTransformer 模型的效果:
history = run_experiment(
model=tabtransformer_model,
train_data_file=train_data_file,
test_data_file=test_data_file,
num_epochs=NUM_EPOCHS,
learning_rate=LEARNING_RATE,
weight_decay=WEIGHT_DECAY,
batch_size=BATCH_SIZE,
)
Start training the model...
Epoch 1/15
123/123 [==============================] - 13s 61ms/step - loss: 82503.1641 - accuracy: 0.7944 - val_loss: 64260.2305 - val_accuracy: 0.8421
Epoch 2/15
123/123 [==============================] - 6s 51ms/step - loss: 68677.9375 - accuracy: 0.8251 - val_loss: 63819.8633 - val_accuracy: 0.8389
Epoch 3/15
123/123 [==============================] - 6s 51ms/step - loss: 66703.8984 - accuracy: 0.8301 - val_loss: 63052.8789 - val_accuracy: 0.8428
Epoch 4/15
123/123 [==============================] - 6s 51ms/step - loss: 65287.8672 - accuracy: 0.8342 - val_loss: 61593.1484 - val_accuracy: 0.8451
Epoch 5/15
123/123 [==============================] - 6s 52ms/step - loss: 63968.8594 - accuracy: 0.8379 - val_loss: 61385.4531 - val_accuracy: 0.8442
Epoch 6/15
123/123 [==============================] - 6s 51ms/step - loss: 63645.7812 - accuracy: 0.8394 - val_loss: 61332.3281 - val_accuracy: 0.8447
Epoch 7/15
123/123 [==============================] - 6s 51ms/step - loss: 62778.6055 - accuracy: 0.8412 - val_loss: 61342.5352 - val_accuracy: 0.8461
Epoch 8/15
123/123 [==============================] - 6s 51ms/step - loss: 62815.6992 - accuracy: 0.8398 - val_loss: 61220.8242 - val_accuracy: 0.8460
Epoch 9/15
123/123 [==============================] - 6s 52ms/step - loss: 62191.1016 - accuracy: 0.8416 - val_loss: 61055.9102 - val_accuracy: 0.8452
Epoch 10/15
123/123 [==============================] - 6s 51ms/step - loss: 61992.1602 - accuracy: 0.8439 - val_loss: 61251.8047 - val_accuracy: 0.8441
Epoch 11/15
123/123 [==============================] - 6s 50ms/step - loss: 61745.1289 - accuracy: 0.8429 - val_loss: 61364.7695 - val_accuracy: 0.8445
Epoch 12/15
123/123 [==============================] - 6s 51ms/step - loss: 61696.3477 - accuracy: 0.8445 - val_loss: 61074.3594 - val_accuracy: 0.8450
Epoch 13/15
123/123 [==============================] - 6s 51ms/step - loss: 61569.1719 - accuracy: 0.8436 - val_loss: 61844.9688 - val_accuracy: 0.8456
Epoch 14/15
123/123 [==============================] - 6s 51ms/step - loss: 61343.0898 - accuracy: 0.8445 - val_loss: 61702.8828 - val_accuracy: 0.8455
Epoch 15/15
123/123 [==============================] - 6s 51ms/step - loss: 61355.0547 - accuracy: 0.8504 - val_loss: 61272.2852 - val_accuracy: 0.8495
Model training finished
Validation accuracy: 84.55%
TabTransformer 模型实现了约 85% 的验证准确度,相比于直接使用全连接网络效果有一定的提升。
参考资料
- ? TabTransformer:https://arxiv.org/abs/2012.06678
- ? TensorFlow插件addons:https://www.tensorflow.org/addons/overview
- ?AI垂直领域工具库速查表 | TensorFlow2建模速查&应用速查:https://www.showmeai.tech/article-detail/109

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:只能用于文本与图像数据?No!看TabTransformer对结构化业务数据精准建模 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 