



? 作者:韩信子@ShowMeAI
? 机器学习实战系列:https://www.showmeai.tech/tutorials/41
? 深度学习实战系列:https://www.showmeai.tech/tutorials/42
? 自然语言处理实战系列:https://www.showmeai.tech/tutorials/45
? 本文地址:https://www.showmeai.tech/article-detail/405
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容
? 引言
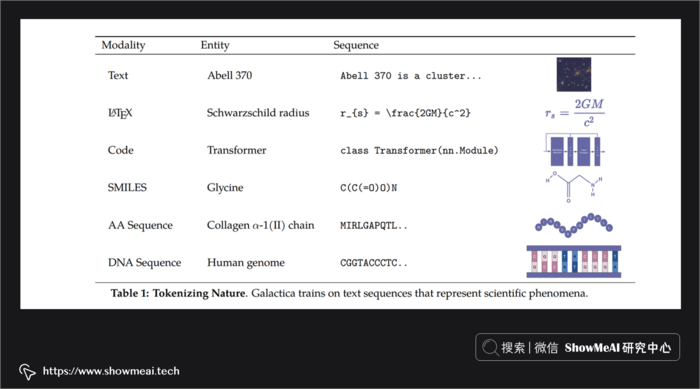
?Galactica 是 Meta AI 开源的大型语言模型,基于 Transformer 架构构建,主要使用科学文章和研究论文作为数据,并使用 ?GROBID 库将文档从 pdf 转换为文本作为语料进行学习。
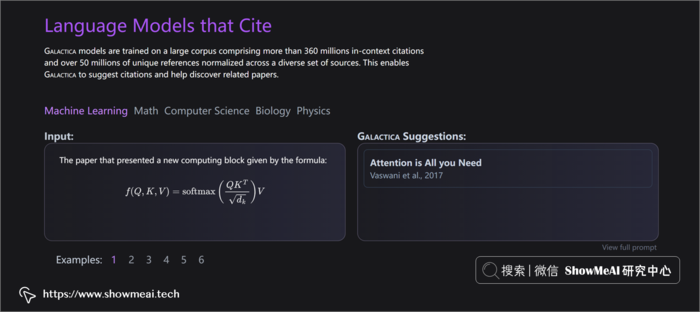
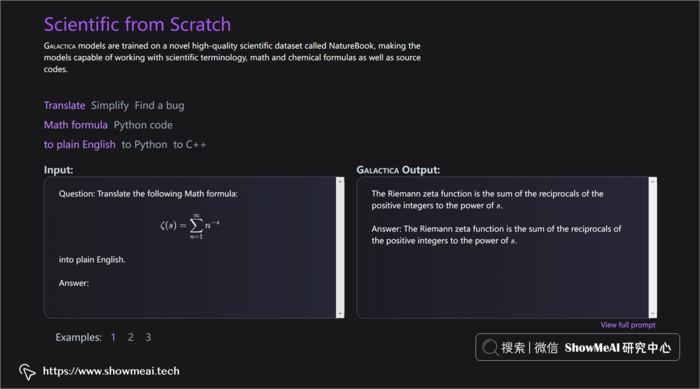
Galactica 模型使用单个模型管理多个科学任务。可以完成推理、创建讲义、预测资料引用等,有以下特点:
- 模型包括125M-120B参数之间的5种不同尺寸。
- 该模型使用 2048 长度的上下文窗口。
- 用于管理特定数据类型的“专业”标记化方法。
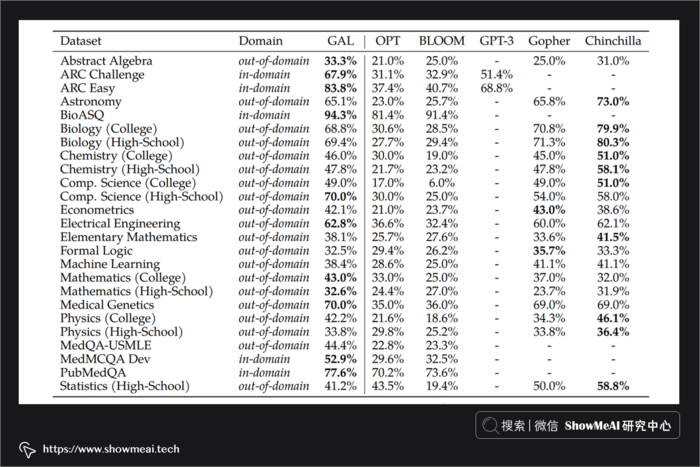
Galactica 模型在面向科学的数据集上做到了最先进的性能。与升级后的 GPT-3 或 OPT 相比,它在 TruthfulQA 数据集中问题结果更少,可作为开源项目使用,在本篇内容中,ShowMeAI就带大家一起体验一下这个科学界的巨型语言模型。
? 实践
? 安装与加载
我们可以通过如下命令安装Galactica模型:
pip install git+https://github.com/paperswithcode/galai
注意:Galactica 模型适用于 Python 版本 3.8 和 3.9。目前Python 3.10 及更高版本时模型安装失败。主要是由于 promptsource-library 依赖要求。
使用下述命令导入模型:
import galai as gal
通过load_model函数加载模型。
model = gal.load_model("base", num_gpus = 1)
加载模型时可以指定加载的预训练模型版本,我们在这里使用“base”版本,模型包括 1.3B(13亿)参数。可选的版本包括“mini”,“base”,“standard”,“large” 和 “huge”,参数量从 125m 到 120b。
更大的模型需要更多内存与计算资源,我们在这里基于内存情况选择“base”版本,它消耗大约 11GB 的内存。
-
load_model的第2个参数是可选的,它指定GPU的数量。
? 模型使用示例
下面我们开始使用和体验模型,下面是一个百科解释类的示例:
model.generate("We can explain Brain as", new_doc=True, top_p=0.7, max_length=200)
模型包括其他参数,我们可以在参数设置中限制输出文本长度,这些参数类似于 GPT-3 模型。
模型输出的结果如下:
We can explain Brain as a computer program that takes in data from the external world, and produces an output as a result. The Brain is the machine that makes decisions about what to do. The Brain is the part of the brain that is made up of neurons, the basic building blocks of the brain. Neurons are the smallest units of the brain. Each neuron contains a membrane and a set of synapses that allow it to communicate with other neurons.\n\n[IMAGE]\n\nFigure Caption: Figure 10.2.110.2.1: Neurons are the smallest units of the brain.\n\n# What are the Functions of Neurons?\n\nNeurons are the basic building blocks of the brain. The brain is the part of the body that is made up of neurons. Neurons communicate with each other using chemical signals called neurotransmitters. The brain has many different types of neurons. The different types of neurons in the brain are called neurons of the different types. Neurons of different types'
? HuggingFace+Galactica
Galactica 模型也可以使用 HuggingFace 加载和使用,我们来看看这个过程,首先我们导入工具库:
!pip install accelerate #to run with the gpu
from transformers import AutoTokenizer, OPTForCausalLM
注意:使用 GPU 运行模型时需要accelerate库。当仅使用 CPU 运行模型时,我们可以跳过安装“accelerate”库。当仅使用 CPU 运行时,该模型很慢。因此,如果大家有 GPU 资源,我们尽量使用GPU运行它。
我们接下来选择模型版本,不同大小的模型分别为“125m”、“1.3b”、“6.7b”、“30b”和“120b”。我们现在将使用以下代码运行 1.25 亿个参数的最小版本:
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-125m")
model = OPTForCausalLM.from_pretrained("facebook/galactica-125m", device_map="auto")
如果要使用其他版本,大家只需将125m换成其他的版本(“1.3b”、“6.7b”、“30b”和“120b”)即可。
加载完模型之后我们来测试一下,这次我们来测试一下模型的推理推断能力。我们以文本形式提供输入:
input_text = "Car 1 speed is 30km/h and Car 2 speed is 50km/h. Which car travels faster and how much? <work>"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda") #when running with gpu is required to add the ".to("cuda")"
我们使用最小版本的Galactica 模型,就准确返回此推理任务的正确答案,如下所示:
Car 1 travels faster than Car 2 (30km/h vs. 50km/h). calc_1.py
result = 30/50 with open(“output.txt”, “w”) as file: file.write(str(round(result)))<<run: “calc_1.py”>> <<read: “output.txt”>> 10 So 10 km. Car 1 travels faster than Car 2 (50km/h vs. 30km/h). calc_2.py ```result = 50/30 … Answer: 20
参考资料
- ? Galactica 官方网站:https://www.galactica.org/
- ? GROBID 官方网站:https://grobid.readthedocs.io/en/latest/Introduction/
- ? Galactica: A Large Language Model for Science:https://galactica.org/static/paper.pdf
推荐阅读
- ? 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- ? 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- ? 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- ? TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- ? PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- ? NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- ? CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
- ? AI 面试题库系列:https://www.showmeai.tech/tutorials/48

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:全都会!预测蛋白质标注!创建讲义!解释数学公式!最懂科学的智能NLP模型Galactica尝鲜 ⛵ - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 