


如果你还不知道 Stable Diffusion 是什么的话,看看这张图片,这就是它的作品。
之前本站(xzhihui.pro)分享过可以免费使用Stable Diffusion绘画的3个网站,如果你还不知道,请点此文章查看。这三个网站可以免费生成AI图像,对一般用户来说足够用了。
但如果你对图像要求比较高,而且不差钱,你也可以选择在腾讯云或阿里云云端部署Stable Diffusion来跑图,也可以选择在本地电脑部署Stable Diffusion。
在本篇接下来的内容中,我会手把手教你在本地电脑上搭建 Stable Diffusion 环境,并生成第一张AI图像。
环境配置要求
Stable Diffusion主要分为两大部分:
- 第一部分是Stable Diffusion WebUI,它是一个可视化的操作界面,就相当于一个软件,我们跟着操作就可以生成AI图像。
- 第二部分是Model,也就是模型。在Stable Diffusion WebUI中,我们可以选择不同的模型,这样生成出来的图像会有不同的效果。Model你可以在本站model下载模块随意下载,想用哪个用哪个。这一点就不多做解释了,未来我们还会更细致的讲解Model的使用方法。
想要顺利运行Stable Diffusion WebUI和Model,对电脑配置有一定的要求。由于Stable Diffusion主要吃显存的,显存越大运行速度越快。而且电脑内存也不能太小,最好不小于16GB。
一般来说,Stable Diffusion的最低配置至少为:
- GPU:4GB显存
- CPU:4核
- 内存:16GB
预算充足的情况下,你可以专门升级显卡,最差也得是3060ti,显存越大越好。CPU和内存够用就行。
如果你电脑没有GPU,或者GPU显存太小,那么也不用灰心,Stable Diffusion可以选择GPU模式和CPU模式,没有GPU用CPU运行跑图也是可以的,只不过速度相对于GPU来说比较慢,我之前完全使用的是CPU模式,4核CPU生成一张图片大约5分钟,玩一玩还是没问题的。
如果你是个新人,想要快速的创建几张AI图像玩一玩,我推荐你阅读《AI图像无限免费生成!Stable Diffusion初学者强烈推荐!》这篇文章,可以快速入门Stable Diffusion。
本地电脑部署 Stable Diffusion
Stable Diffusion 是一个开源项目,源代码可以直接在Github上获取到。但是直接从项目中启动,需要的环境资源非常多而且杂乱,所以推荐你用大佬们创建出来的整合包。这样你把整合包下载到本地安装好,就可以直接运行Stable Diffusion绘画了,省去了很多麻烦。
目前比较火的整合包有(放上链接以示尊重):
这里我用的是秋叶的整合包,你也可以在百度网盘下载,链接:https://pan.baidu.com/s/11Du5S4zPcMLO7WOG2UbDlw 提取码:izqc。
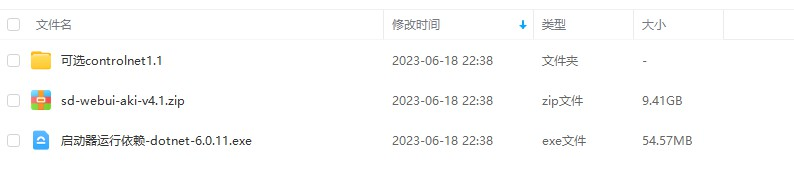
下载下来后总共有以上3种文件,我们先运行【启动器运行依赖】,把依赖项安装上,然后解压【sd-webui-aki-v4.1.zip】文件,Stable Diffusion的所有程序都在这个压缩包中。至于【可选controlnet1.1】文件夹,其中是一些Model模型,不是必须的,不用管它。
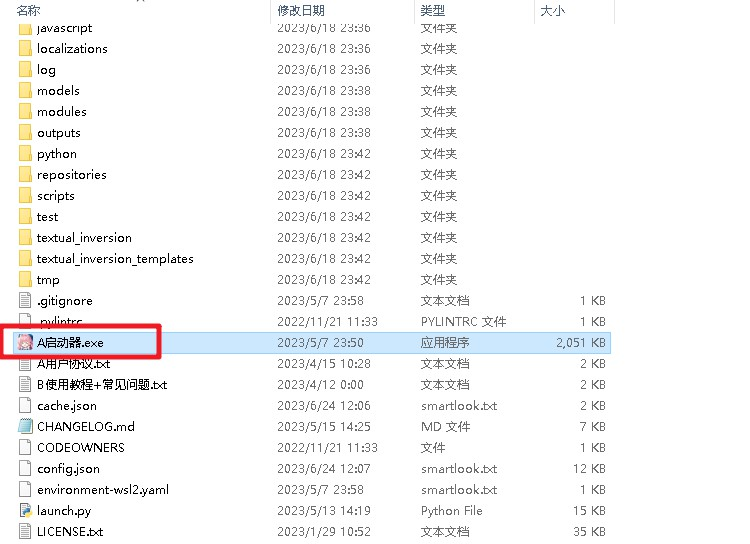
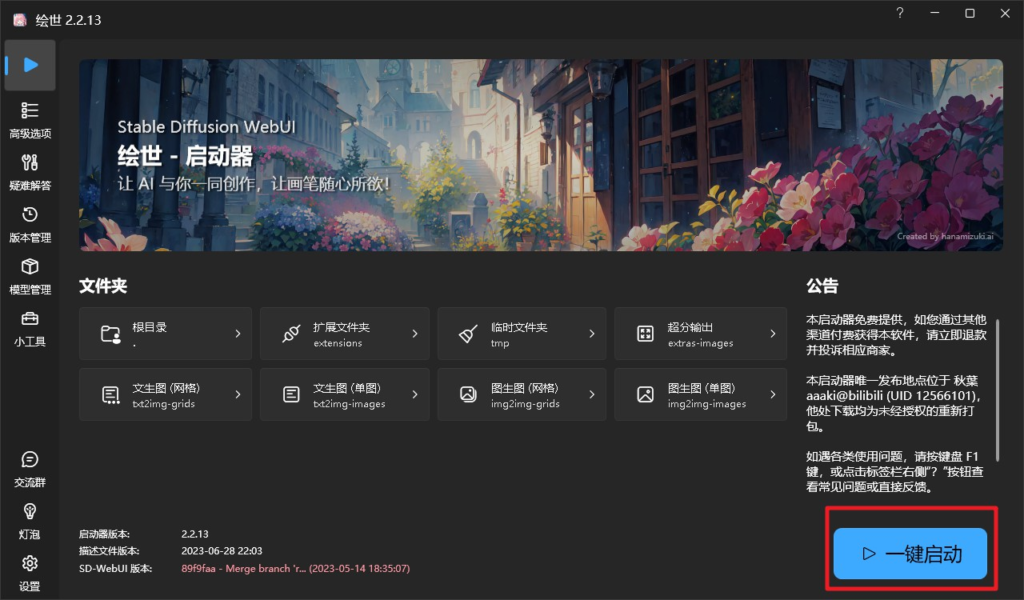
【sd-webui-aki-v4.1.zip】文件解压后,,运行【A启动器】,然后再点击【一键启动】即可启动Stable Diffusion。如下:
稍等片刻之后,会在浏览器中自动打开Stable Diffusion WebUI,界面如下,即说明安装成功了。
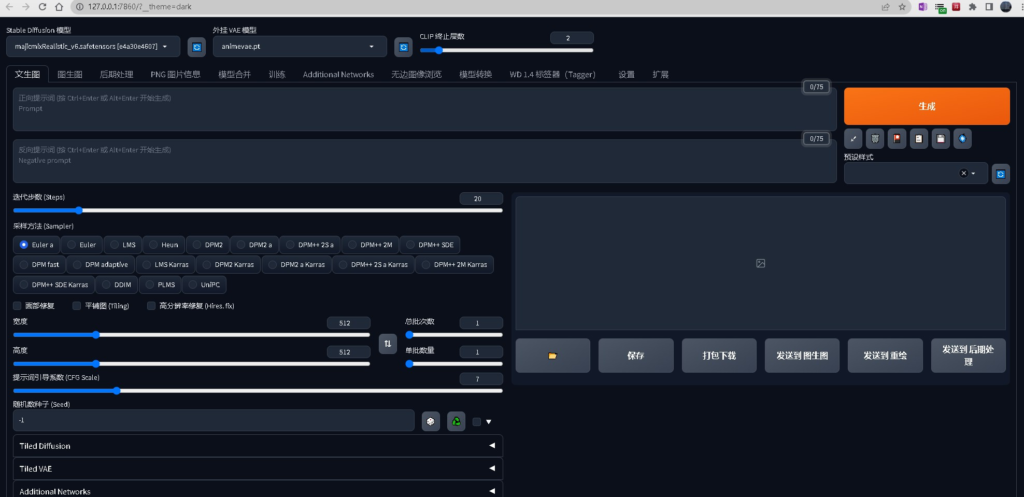
恭喜你,你现在可以进行AI绘画创作了!
接下来我将简单演示使用【文生图】功能创作一张AI图片,大家可以跟我一块实操。如果下列WebUI中有些设置选项你不是很清楚,先不用着急,后续的文章中我们会深度讲解Stable Diffusion的高级操作方法。
首先我们先选择几个基本的参数,输入到对应的文本框中:
- Stable Diffusion模型:此处选择的是绘图model,你们刚安装完的应该是默认的Stable Diffusion v2.1模型,此处我使用了majicMIX realistic模型,这款模型生成出来的图片特别真实、漂亮。由于模型不一样,所以你们生成的图片可能跟我的有很大差别。
- 正向提示词:(8k, best quality, masterpiece:1.2), (realistic, photorealistic, photo-realistic:1.37), ultra-detailed, beautiful detailed eyes, beautiful detailed nose,
- 反向提示词:(EasyNegative:1.2),paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots , acnes, skin blemishes, age spots, (outdoor:1.6), (manboobs), (backlight), (ugly:1.33), (duplicate:1.33), (morbid:1.21), (mutilated:1.21), (tranny: 1.33), mutated hands, (poorly drawn hands:1.33), blurry, (bad anatomy:1.21), (bad proportions:1.33), extra limbs, (disfigured:1.33), (more than 2 nipples), (missing arms: 1.33), (extra legs:1.33), (fused fingers:1.61), (too many fingers:1.61), (unclear eyes:1.33), bad hands, missing fingers, extra digit, (futa:1.16), bad body, NG_DeepNegative_V1_75T, (too many fingers:1.7), (bad hands:0.1), (extra fingers:1.9), (mutated hands:1.9), abdominal stretch, glans, {{fused fingers}}, {{bad body}}
- 宽度:512
- 高度:768
- 随机数种子:2887709609
设置好参数之后,我们点击【生成】按钮。
如果你的GPU显存足够,图片会很快生成,如果你没有GPU,使用的是CPU模式,那么就会很慢,只能耐心等待。
片刻之后,SD给我生成了这张女神照片:

你们生成的图片是怎样的,比一比呀!
看完本篇文章你应该已经入门AI绘画领域了,接下来你可以学习《关于Stable Diffusion模型你应该知道的所有知识!》,也可以学习《Ai绘图关键字大全》进一步学习AI绘画。
本文转载自https://www.xzhihui.pro/134625.html,本文观点不代表Python技术站立场。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 