tensorflow:实战Google深度学习框架第四章01损失函数
深度学习:两个重要特性:多层和非线性
线性模型:任意线性模型的组合都是线性模型,只通过线性变换任意层的全连接神经网络与单层神经网络没有区别。
激活函数:能够实现去线性化(神经元的输出通过一个非线性函数)。
多层神经网络:能够解决异或问题,深度学习有组合特征提取的功能。
使用激活函数和偏置项的前向传播算法
import tensorflow as tf a = tf.nn.relu(tf.matmul(x,w1) + biases1) y = tf.nn.relu(tf.matmul(a,w2) + biases2)
常用的激活函数:tf.nn.relu, tf.sigmoid, tf.tanh
二、损失函数(loss faction)
1、经典损失函数:分类问题:交叉熵,回归问题:均方误差
交叉熵:刻画两个概率分布之间的距离,交叉熵越小,概率分布越接近,给定两个概率分布p和q,通过q表示p的交叉熵(概率分布q来表达概率分布p的困难程度,p:正确答案,q:代表预测值):
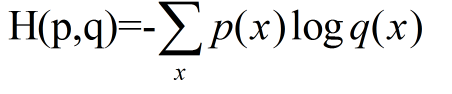

神经网络的输出不一定是概率分布,Softmax回归就是将神经网络的输出变成概率分布常用的方法
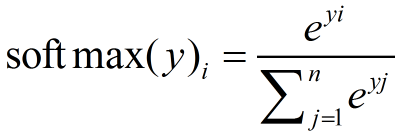
交叉熵的代码实现:
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))#y_代表正确结果,y代表预测结果
#第一个运算tf.clip_by_value函数可以将张量的数值限制在一个范围内,这样可以避免一些运算错误 #例如 import tensorflow as tf sess = tf.Session() v=tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]]) print(tf.clip_by_value(v,2.5,4.5).eval(session=sess)) #输出[[ 2.5 2.5 3. ],[ 4. 4.5 4.5]],将小于2.5的数替换为2.5,将大于4.5的数替换为4.5 #第二个运算tf.log函数,这个函数完成对张量中所有元素依次取对数。 v = tf.constant([1.0,2.0,3.0]) print(tf.log(v).eval(session=sess)) #输出为[ 0. 0.69314718 1.09861231] #第三个运算乘法,在交叉熵代码中将矩阵使用“*”操作相乘,这是元素之间直接相乘,矩阵乘法需要tf.matmul函数完成 v1 = tf.constant([[1.0,2.0],[3.0,4.0]]) v2 = tf.constant([[5.0,6.0],[7.0,8.0]]) print((v1 * v2).eval(session=sess))#元素相乘 #输出为[[ 5. 12.] [ 21. 32.]] print(tf.matmul(v1,v2).eval(session=sess))#矩阵相乘 #输出[[ 19. 22.] [ 43. 50.]] #前三步结果为:n*m的矩阵,其中n为一个batch的样例数量,m为分类的类别数量。根据交叉熵公式,要将每行m个结果相加得到所有样例的交叉熵,再对这n行取平均得到一个batch的平均交叉熵 #由于分类问题类别不变 sess.close()
配合softmax函数使用:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y,y_)
若只有一个正确答案,使用下面函数加速计算:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(y,y_)
回归问题解决的是具体数值的预测,一般只有一个输出节点,最常用的损失函数是均方误差(MSE):
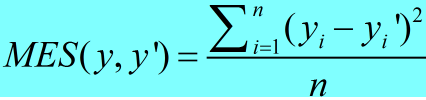
代码实现:
mse = tf.reduce_mean(tf.square(y_-y))
2、自定义损失函数
# 不同的损失函数会对训练模型产生重要影响 import tensorflow as tf from numpy.random import RandomState # 1. 定义神经网络的相关参数和变量 batch_size = 8 x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input") y_ = tf.placeholder(tf.float32, shape=(None, 1), name=\'y-input\') w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1)) y = tf.matmul(x, w1) # 2. 设置自定义的损失函数 # 定义损失函数使得预测少了的损失大,于是模型应该偏向多的方向预测。 loss_less = 10 loss_more = 1 loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less)) train_step = tf.train.AdamOptimizer(0.001).minimize(loss) # 3. 生成模拟数据集 rdm = RandomState(1) X = rdm.rand(128,2) Y = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] # 4. 训练模型 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 5000 for i in range(STEPS): start = (i*batch_size) % 128 end = (i*batch_size) % 128 + batch_size sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 1000 == 0: print("After %d training step(s), w1 is: " % (i)) print(sess.run(w1), "\n") print("[loss_less=10 loss_more=1] Final w1 is: \n", sess.run(w1)) \'\'\' After 0 training step(s), w1 is: [[-0.81031823] [ 1.4855988 ]] After 1000 training step(s), w1 is: [[ 0.01247113] [ 2.13854504]] After 2000 training step(s), w1 is: [[ 0.45567426] [ 2.17060685]] After 3000 training step(s), w1 is: [[ 0.69968736] [ 1.84653103]] After 4000 training step(s), w1 is: [[ 0.89886677] [ 1.29736042]] [loss_less=10 loss_more=1] Final w1 is: [[ 1.01934707] [ 1.04280913]] \'\'\' # 5. 重新定义损失函数,使得预测多了的损失大,于是模型应该偏向少的方向预测 loss_less = 1 loss_more = 10 loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less)) train_step = tf.train.AdamOptimizer(0.001).minimize(loss) with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 5000 for i in range(STEPS): start = (i*batch_size) % 128 end = (i*batch_size) % 128 + batch_size sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 1000 == 0: print("After %d training step(s), w1 is: " % (i)) print(sess.run(w1), "\n") print("[loss_less=1 loss_more=10] Final w1 is: \n", sess.run(w1)) \'\'\' After 0 training step(s), w1 is: [[-0.81231821] [ 1.48359871]] After 1000 training step(s), w1 is: [[ 0.18643527] [ 1.07393336]] After 2000 training step(s), w1 is: [[ 0.95444274] [ 0.98088616]] After 3000 training step(s), w1 is: [[ 0.95574027] [ 0.9806633 ]] After 4000 training step(s), w1 is: [[ 0.95466018] [ 0.98135227]] [loss_less=1 loss_more=10] Final w1 is: [[ 0.95525807] [ 0.9813394 ]] \'\'\' # 6. 定义损失函数为MSE loss = tf.losses.mean_squared_error(y, y_) train_step = tf.train.AdamOptimizer(0.001).minimize(loss) with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 5000 for i in range(STEPS): start = (i*batch_size) % 128 end = (i*batch_size) % 128 + batch_size sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 1000 == 0: print("After %d training step(s), w1 is: " % (i)) print(sess.run(w1), "\n") print("[losses.mean_squared_error]Final w1 is: \n", sess.run(w1)) \'\'\' After 0 training step(s), w1 is: [[-0.81031823] [ 1.4855988 ]] After 1000 training step(s), w1 is: [[-0.13337614] [ 1.81309223]] After 2000 training step(s), w1 is: [[ 0.32190299] [ 1.52463484]] After 3000 training step(s), w1 is: [[ 0.67850214] [ 1.25297272]] After 4000 training step(s), w1 is: [[ 0.89473999] [ 1.08598232]] [losses.mean_squared_error]Final w1 is: [[ 0.97437561] [ 1.0243336 ]] \'\'\'
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:tensorflow:实战Google深度学习框架第四章01损失函数 – 南野小童 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 