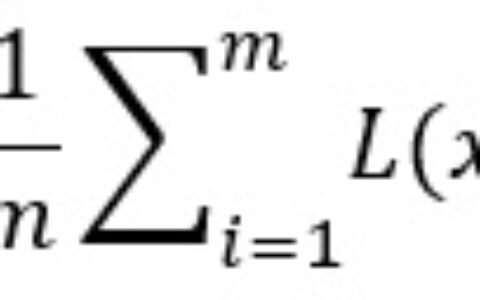NVIDIA深度学习Tensor Core性能解析(上)
本篇将通过多项测试来考验Volta架构,利用各种深度学习框架来了解Tensor Core的性能。
很多时候,深度学习这样的新领域会让人难以理解。从框架到模型,再到API和库,AI硬件的许多部分都是高度定制化的,因而被行业接受的公开基准测试工具很少也就不足为奇。随着ImageNet和一些衍生模型(AlexNet、VGGNet、Inception、Resnet等)的影响,ILSVRC2012(ImageNet大规模视觉识别挑战)中的图像数据集训练逐渐被行业所认可。
基本上所有现代深度学习框架都支持CUDA和cuDNN,对于Volta而言,所有支持FP16存储的框架也都支持Tensor Core加速,启用FP16存储后Tensor Core加速会自动启用,因此我们可以利用这些框架来了解Tensor Core的性能。
")
在常见的第三方深度学习基准套件中,Fathom和TBD是更传统的基准测试套件,其测试针对特定框架和模型进行了配置,涵盖了许多不同的机器学习应用程序。 同时,最近的深度学习框架侧重于比较给定模型和跨框架的数据集的性能。
而DeepBench本身并不使用框架,而是使用低级库来评估不同设备的机器学习性能。就其本身而言,虽然它并不直接将框架/模型/应用程序性能与其他测试联系在一起,但它提供了代表供应商优化的数学操作和硬件性能的指标,每个产品的二进制文件都使用硬件供应商提供的库进行编译。
")
DAWNBench则更加与众不同,与其说它是一个基准测试套件,不如说是对三个数据集(ImageNet、CIFAR10和SQuAD)的训练和推断结果进行类似于竞赛的报告,重点考量端对端的计算精确度和成本。
至于HPE DLBS,作为HPE深度学习指南的一部分,它主要以GPU为中心,坚持使用TensorFlow、MXNet、PyTorch和Caffe类型框架,还包括TensorRT测试。虽然其具有良好的多测试批处理、日志记录、监控和报告功能,但它只输出纯粹的性能和时间指标,不涉及端对端的时间精度或成本。
从这些基准测试软件中可以看出,深度学习框架之间的差异很容易使测试结果变得毫无意义,从而影响我们对这些框架的研究。convnet-benchmark和PyTorch的创始人Soumith Chintala指出,如果没有机器学习的背景,很难独立地验证深度学习基准测试的准确性和范围,不过MLPerf测试项目似乎试图解决这个问题。
")
MLPerf是由DAWNBench等测试软件的设计者和工程师联合打造的全新高端基准测试套件,希望囊括Fathom的跨域测试方法以及DAWNBench对超过阈值精度模型的端对端计算时间考察。不过它目前正在处于alpha阶段,开发团队表示其尚不适合进行精确的硬件对比。
综合考虑之下,本次测试将不包含MLPerf项目,而是使用DeepBench、Caffe2 Docke、Stanford DAWN和HPE DLBS来进行。
DeepBench训练测试之GEMM和RNN
首先进行的是GEMM测试,利用某些深度学习应用程序(DeepSpeech、Speaker ID和Language Modeling)中的内核进行GEMM操作,测出的性能比在cuBLAS中运行纯矩阵-矩阵乘法更有代表性。
测试的结果在意料之内,启用Tensor Core可以大幅提升性能。深入研究细节可以发现,Tensor Core对于特定类型的矩阵-矩阵乘法会有特别的影响。
")
通过深度学习应用程序拆分GEMM测试,我们可以了解Tensor Core在理想和非理想情况下的表现。
")
Speaker ID GEMM工作负载实际上只包含两个内核,其中10微秒的时间差意味着大约1 TFLOPS的算力差异。
")
通过对语言模型内核的研究,可以了解Tensor Core在非理想情况下的性能。这些核矩阵的大小是m=512或1024,n=8或16,k=500000,虽然每个数在技术上都可以被8整除——这是满足张量核加速度的基本要求之一——但这些矩阵的形状与Tensor Core支持的16*16*16、32*8*16和8*32*16等基本WMMA形状不太匹配。假如Tensor Core真正在独立的8x8x8级别上运行,那么运算8*8*8矩阵的性能也不会很好。
")
因此,Tensor Core无法高效的将这些非常不平衡的矩阵分解为n=8或16。而且,Tensor Core在DeepSpeech内核上的性能也出现异常:
")
从所有子项的平均成绩来看,这个浮点运算性能令人印象深刻。当矩阵适合于Tensor Core时,性能可以超过90TFLOPS;相反如果二者无法契合,并正确的换位没有发挥作用,性能会低至<1TFLOPS的水平。
对于DeepBench RNN内核的测试,RNN类型之间没有明显的差异,但是在每种RNN类型中,如果将不同内核挨个进行对比判断,也可以看到与GEMM中相同的趋势。
")
")
")
比较有趣的是,Titan Xp与Titan V在未使用Tensor Core加速时的表现有很接近,Titan Xp的高频率为其性能起到了一定的帮助。
DeepBench训练测试之Convolutions
在卷积训练工作负载测试中,Tensor Core再次显着提高了性能。鉴于卷积层是图像识别和分类的基础,因而卷积运算是Tensor Core加速的最大潜在受益者之一。
从所有测试项的平均成绩可以看出,Volta在启用了Tensor Core的FP16混合精度运算能力后性能再次取得了领先。不过与GEMM不同,在FP32卷积上启用Tensor Core会导致明显的性能损失。
")
")
当计算涉及不匹配的张量尺寸时,标准精度模式遵循cuDNN指定的最快前向算法(如Winograd),而混合精度模式必须对所有内核使用隐式预计算GEMM,这会造成两种混合精度模式的性能会出现下滑。
要符合Tensor Core加速的要求,输入和输出通道尺寸必须是8的倍数,输入、过滤和输出数据的类型必须是半精度。使用Tensor Core实现卷积加速要求张量采用NHWC格式,但大多数框架都希望采用NCHW格式的张量。在这种情况下,输入通道不是8的倍数,但测试程序会自动填充以解决此问题。
")
需要注意的是,所有这些NCHW内核都需要转换为NHWC。想要从Tensor Core中受益,需要正确的调整卷积格式,本次测试使用的是NVIDIA提供的标准库和makefile。NVIDIA指出,一旦进行加速卷积,它会消耗掉相当多的运行时间,这将会对FP32和FP16混合精度模式造成影响。
")
")
DeepBench推理测试之GEMM
数据精度方面,百度将DeepBench GEMM和卷积定义支持32bit累加的INT8格式,以支持Volta和Pascal上的INT8计算。
")
Titan V和Titan Xp均拥有4倍于INT32的INT8性能,DeepBench的INT8推理测试正中Pascal引入的DP4A矢量点积能力之下怀。Volta同样拥有这一能力,在指令集中二者均显示为IDP和IDP4A。
")
对IGEMM来说,正如CUTLASS所示,DP4A是一项定制操作。因此除语言建模之外,INT8的性能都非常之高。当然,与硬件不匹配的张量尺寸不适合Tensor Core加速,这一点与之前完全一样。
")
")
在完全连接(仿射)层中,每个节点都与前一层中的各节点相连接。对于一个典型的CNN来说,完全连接的层意味着可以结合所有提取的特征做出最终预测并对图像进行分类。这些测试结果数据也意味着大型且规则的矩阵可以在Tensor Core加速中获得更大的收益。
")
")
DeepBench推理测试Convolutions
再次来到卷积测试环节,8位乘法/32位累加再次出现在INT8推理中。
测试中最引人注目的是Titan Xp,在Resnet、Speaker ID和Vision项目中,Titan Xp表现出了强劲的INT8吞吐量。
")
从内核方面来看,并没有发现这一现象的根源所在,猜测可能是由于Pascal的DP4A库好驱动程序比Volta更为成熟所致,亦或许是Volta通过单独的INT单元处理这些运算。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:NVIDIA深度学习Tensor Core性能解析(上) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫