
1.概念
1.1 pipeline
一个基础的 深度学习的Pipeline 主要包含了下述 5 个步骤(5个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。):
- (1).数据读取
- (2).数据预处理
- (3).创建模型(具体到模型也有相应的Pipeline,比如模型的具体构成部分:比如GCN+Attention+MLP的混合模型)
- (4).评估模型结果
- (5).模型调参
总之,深度学习的Pipeline 就是模型实现的步骤。深度学习现在的Pipeline 一般都比较强调模型的组件构成流程。
1.2 baseline
baseline意思是基线,这个概念是作为算法提升的参照物而存在的,相当于一个基础模型,可以以此为基准来比较对模型的改进是否有效。
通常在一些竞赛或项目中,baseline就是指能够顺利完成数据预处理、基础的特征工程、模型建立以及结果输出与评价,然后通过深入进行数据处理、特征提取、模型调参与模型提升或融合,使得baseline可以得到改进。
所以这个没有明确的指代,改进后的模型也可以作为后续模型的baseline。
1.3 backbone
backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。
在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
所以将这一部分网络结构称为backbone十分形象,仿佛是一个人站起来的支柱。
1.4 CNN中feature map的含义
在每个卷积层,数据都是以三维形式存在的。你可以把它看成许多个二维图片叠在一起,其中每一个称为一个feature map。在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)。层与层之间会有若干个卷积核(kernel),上一层和每个feature map跟每个卷积核做卷积,都会产生下一层的一个feature map。
1.5 epoch、 iteration和batchsize
- (1)batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
- (2)iteration:1个iteration等于使用batchsize个样本训练一次;
- (3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子,训练集有1000个样本,batchsize=10,那么:训练完整个样本集需要:100次iteration,1次epoch。
1.6 “输入通道”与“输出通道”
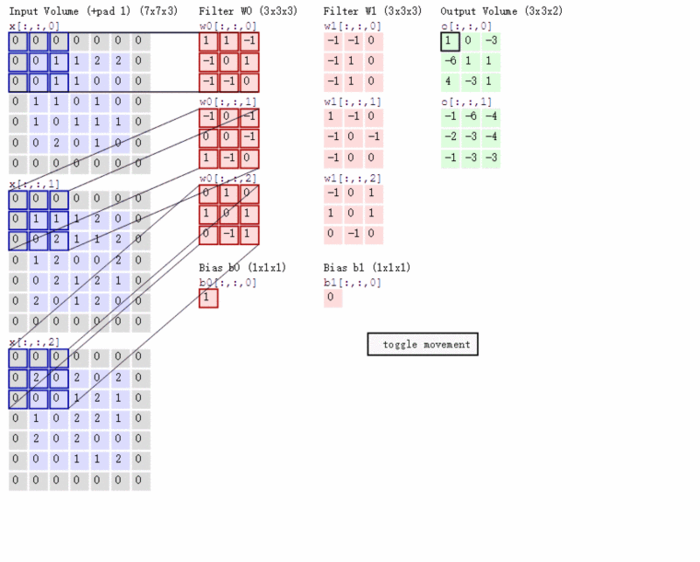

输入通道指的是输入了几个二维信息,也就是很直观的rgb图有r,g,b三个通道,这决定了卷积核的通道数,即输入图像的通道数决定了卷积核通道数;(图片中,第一列有三个矩阵,也就是输入通道为3,所以后面,第二列和第三列,也就是两个卷积核,它们也都有三个矩阵,即卷积核通道数目也为3。)
输出通道是指卷积(关联)运算之后的输出通道数目,它决定了有几个卷积核,即需要输出通道数为几,就需要几个卷积核。(图中,第二列和第三列分别都是三通道的卷积核,输入图像与这两个卷积核做完卷积运算后,产生了第四列的两个矩阵,也就是输出了两个通道)
最后说一下动图演示的事情,输入一个三通道图像,和两个三通道的卷积核做了卷积运算,得到两个输出通道。
题外话:
每个卷积核具有长、宽、深三个维度。
卷积核的长、宽都是人为指定的,长X宽也被称为卷积核的尺寸,常用的尺寸为3X3,5X5等;
卷积核的深度与当前图像的深度(feather map的张数)相同,所以指定卷积核时,只需指定其长和宽两个参数
例如:在原始图像层 (输入层),如果图像是灰度图像,其feather map数量为1,则卷积核的深度也就是1;如果图像是grb图像,其feather map数量为3,则卷积核的深度也就是3.
例如:输入224x224x3(rgb三通道),输出是32位深度,卷积核尺寸为5x5。
那么我们需要32个卷积核,每一个的尺寸为5x5x3(最后的3就是原图的rgb位深3),每一个卷积核的每一层是5x5(共3层)分别与原图的每层224x224卷积,然后将得到的三张新图叠加(算术求和),变成一张新的feature map。 每一个卷积核都这样操作,就可以得到32张新的feature map了。 也就是说:
不管输入图像的深度为多少,经过一个卷积核(filter),最后都通过下面的公式变成一个深度为1的特征图。不同的filter可以卷积得到不同的特征,也就是得到不同的feature map。
2.疑问点
以下部分的内容来源于网络查找,若有不恰当的地方,希望大佬提出。
2.1 卷积神经网络中为什么要在卷积层后面添加激活函数?
简单的说:增加非线性,即使得输入与输出之间保持非线性的关系。如果不加激活函数,神经元永远只能拟合线性的情况...没办法拟合高维数据。(如果只是想浅了解一下,后面的可以不看了)
原理:
卷积操作是一种线性的仿射变换(什么是仿射变换呢?仿射变换,又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间)
以下是卷积过程:

更一般的,我们如果有输入图片x和卷积核w以及输出图片y,它们的各个值为:

由于输出像素是由输入像素和卷积核得到的,所以输出图片的各个像素可以写成:

列出来后,可以看出,这和多元线性回归的式子没有什么区别!我们甚至可以把上面的式子写成向量的形式:
\(Y=W^TX\)
相当于将图片x和y展开成一维的形式:

就可以把原式看成向量X和Y的线性方程组。
从这里应该可以看出,卷积核可以表示成一种特殊的多元线性回归的权重矩阵;由于权重矩阵有大量的参数是一样的,且有大量的0,所以可以把权重矩阵的系数都压缩到一个卷积核中又不损失信息。卷积的这种数学操作的特点又保留了图片的空间信息,所以卷积是一种开销小于全连接层,但效果较好的操作。
所以在神经网络学习参数中,可以把对卷积核的拟合视为一种对神经元权重的拟合,只是神经元之间会以某种方式连接并且共享大量参数。
也可以很自然的推导出,如果没有池化层等非线性操作,那么多层卷积就等同于一层卷积,只靠卷积操作无法拟合任意函数。
2.2 卷积神经网络卷积层后一定要跟激活函数吗?
这个问题是上一个问题的引申,卷积神经网络卷积层后是不一定要跟激活函数的。
解释:
卷积神经网络卷积层后是否加激活函数是根据数据集来定的:如果是图像类,需要得到复杂深度特征,需要非线性激活,那就要加激活。而如果是处理一维信号,比如振动数据,音频数据,很多时候不加激活效果会好上不少。尤其是工业故障数据,很多时候本身就是线性可分的,网络越复杂效果越差。
我觉得这个问题几本上没有什么好纠结的,我们都知道一般的机器学习算法,比如决策树算法,支持向量机,这些算法都只能解决线性可分的问题,当遇到线性不可分的问题时便没法了,而神经网络为何如此强大的原因一部分就归结于其引入了激活函数,使得函数经过隐藏层之间的层层调用,变成了线性可分的了。假如不跟激活函数,层层之间的数据传递也只是前面的x的参数多点而已,达不到将x变成高次方的目的,不能变成高次方不能函数的形状就还是直线型,还是线性的。
3.代码相关(pytorch版)
以下仅为自己写代码时的方式:
3.1 写代码的流程
确定输出目标—》选择数据-》数据预处理(通常是转化为张量)—》提取特征(构建主干网络模型提取)—》模型训练(不可视的,将标准输入数据经过模型得到输出数据,然后与标准输出数据比对,再利用修改参数,再去训练,直到比对正确)—》模型评估与优化—》模型预测结果—》输出目标转换
3.2 代码的组织结构
3.2.1 主要部分
当一个程序代码长度过长,就可以拆分成几个文件,方便阅读和修改,代码拆分数据如下:
preprocess:数据预处理
对数据进行预处理的文件,将数据转为backbone想要接收的格式与类型。
backbone:提取特征
翻译为主干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,供后面的网络使用。这些网络经常使用的是resnet、VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。
neck:承上启下
是放在backbone和head之间的,是为了更好的利用backbone提取的特征。
bottleneck:转化输出
瓶颈的意思,通常指的是网网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多,就像脖子一样,变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。
head:预测思考
head是获取网络输出内容的网络,利用之前提取的特征,head利用这些特征,做出预测。
3.2.2 次要部分
pretext task和downstream task:
用于预训练的任务被称为前置/代理任务(pretext task),用于微调的任务被称为下游任务(downstream task)
热身Warm up
Warm up指的是用一个小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定。
end to end
在论文中经常能遇到end to end这样的描述,那么到底什么是端到端呢?其实就是给了一个输入,我们就给出一个输出,不管其中的过程多么复杂,但只要给了一个输入,机会对应一个输出。比如分类问题,你输入了一张图片,肯呢个网络有特征提取,全链接分类,概率计算什么的,但是跳出算法问题,单从结果来看,就是给了一张输入,输出了一个预测结果。End-To-End的方案,即输入一张图,输出最终想要的结果,算法细节和学习过程全部丢给了神经网络。
3.3 代码解读
大家直接去看大佬JacobDale的博客就可
4.参考文章
深度学习网络中backbone和feature map的含义
backbone、head、neck等深度学习中的术语解释 - 知乎
https://blog.csdn.net/zouxiaolv/article/details/109530461
(8条消息) pytorch之dataloader,enumerate
【创作不易,望点赞收藏,若有疑问,请留言,谢谢】
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习资料梳理 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 