1 特征点检测(Landmark detection)
假设你正在构建一个人脸识别应用,出于某种原因,你希望算法可以给出眼角的具体位置。眼角坐标为(x, y),你可以让神经网络的最后一层多输出两个数字lx和ly,作为眼角的坐标值。如果你想知道两只眼睛的四个眼角的具体位置,那么从左到右,依次用四个特征点来表示这四个眼角。对神经网络稍做些修改,输出第一个特征点(l1x,l1y),第二个特征点(l2x,l2y),依此类推,这四个脸部特征点的位置就可以通过神经网络输出了。也可以有更多的特征点,用来提取脸部轮廓或下颌轮廓。
2 目标检测(Object detection)
通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法。假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车。滑动窗口目标检测算法接下来会继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络,因此输入给卷积网络的只有红色方框内的区域,再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落。为了滑动的更快,可以选用比较大的步幅。
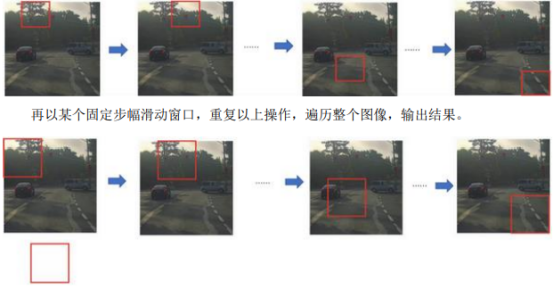

滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:特征点检测、目标检测 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 