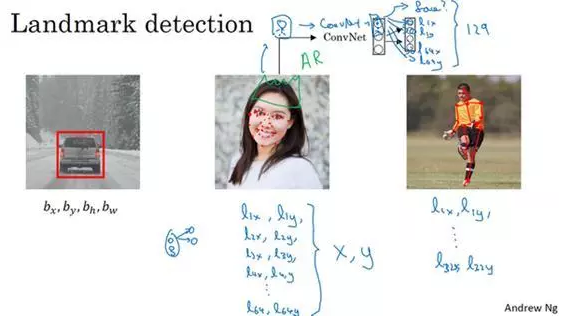
特征点检测(Landmark detection)
上节课,我们讲了如何利用神经网络进行对象定位,即通过输出四个参数值b_x、b_y、b_h和b_w给出图片中对象的边界框。更概括地说,神经网络可以通过输出图片上特征点的(x,y)坐标来实现对目标特征的识别,我们看几个例子。

假设你正在构建一个人脸识别应用,出于某种原因,你希望算法可以给出眼角的具体位置。
眼角坐标为(x,y),你可以让神经网络的最后一层多输出两个数字l_x和l_y,作为眼角的坐标值。如果你想知道两只眼睛的四个眼角的具体位置,那么从左到右,依次用四个特征点来表示这四个眼角。对神经网络稍做些修改,输出第一个特征点(l_1x,l_1y),第二个特征点(l_2x,l_2y),依此类推,这四个脸部特征点的位置就可以通过神经网络输出了。

也许除了这四个特征点,你还想得到更多的特征点输出值,这些(图中眼眶上的红色特征点)都是眼睛的特征点,你还可以根据嘴部的关键点输出值来确定嘴的形状,从而判断人物是在微笑还是皱眉,也可以提取鼻子周围的关键特征点。
为了便于说明,你可以设定特征点的个数,假设脸部有64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
具体做法是,准备一个卷积网络和一些特征集,将人脸图片输入卷积网络,输出1或0,
1表示有人脸,0表示没有人脸,
然后输出(l_1x,l_1y)……直到(l_64x,l_64y)。这里我用l代表一个特征,这里有129个输出单元,其中1表示图片中有人脸,因为有64个特征,64×2=128,所以最终输出128+1=129个单元,由此实现对图片的人脸检测和定位。
这只是一个识别脸部表情的基本构造模块,如果你玩过Snapchat或其它娱乐类应用,你应该对AR(增强现实)过滤器多少有些了解,Snapchat过滤器实现了在脸上画皇冠和其他一些特殊效果。
检测脸部特征也是计算机图形效果的一个关键构造模块,比如实现脸部扭曲,头戴皇冠等等。当然为了构建这样的网络,你需要准备一个标签训练集,也就是图片x和标签y的集合,这些点都是人为辛苦标注的。
最后一个例子,如果你对人体姿态检测感兴趣,你还可以定义一些关键特征点,如胸部的中点,左肩,左肘,腰等等。然后通过神经网络标注人物姿态的关键特征点,再输出这些标注过的特征点,就相当于输出了人物的姿态动作。当然,要实现这个功能,你需要设定这些关键特征点,从胸部中心点(l_1x,l_1y)一直往下,直到(l_32x,l_32y)。
一旦了解如何用二维坐标系定义人物姿态,操作起来就相当简单了,批量添加输出单元,用以输出要识别的各个特征点的(x,y)坐标值。
要明确一点,特征点1的特性在所有图片中必须保持一致,就好比,特征点1始终是右眼的外眼角,特征点2是右眼的内眼角,特征点3是左眼内眼角,特征点4是左眼外眼角等等。所以标签在所有图片中必须保持一致,假如你雇用他人或自己标记了一个足够大的数据集,那么神经网络便可以输出上述所有特征点,你可以利用它们实现其他有趣的效果,比如判断人物的动作姿态,识别图片中的人物表情等等。
以上就是特征点检测的内容,下节课我们将利用这些构造模块来构建对象检测算法。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【51】目标检测之特征点检测 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫