


? 作者:韩信子@ShowMeAI
? 数据分析实战系列:https://www.showmeai.tech/tutorials/40
? 机器学习实战系列:https://www.showmeai.tech/tutorials/41
? 本文地址:https://www.showmeai.tech/article-detail/308
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容

人力资源是组织的一个部门,负责处理员工的招聘、培训、管理和福利。一个组织每年都会雇佣几名员工,并投入大量时间、金钱和资源来提高员工的绩效和效率。每家公司都希望能够吸引和留住优秀的员工,失去一名员工并再次雇佣一名新员工的成本是非常高的,HR部门需要知道雇用和留住重要和优秀员工的核心因素是什么,那那么可以做得更好。

在本项目中,ShowMeAI 带大家通过数据科学和AI的方法,分析挖掘人力资源流失问题,并基于机器学习构建解决问题的方法,并且,我们通过对AI模型的反向解释,可以深入理解导致人员流失的主要因素,HR部门也可以根据分析做出正确的决定。
本篇涉及到的数据集大家可以通过 ShowMeAI 的百度网盘地址获取。
? 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [17]人力资源流失场景机器学习建模与调优 『HR-Employee-Attrition 数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
? 探索性数据分析
和 ShowMeAI 之前介绍过的所有AI项目一样,我们需要先对场景数据做一个深度理解,这就是我们提到的EDA(Exploratory Data Analysis,探索性数据分析)过程。

EDA部分涉及的工具库,大家可以参考ShowMeAI制作的工具库速查表和教程进行学习和快速使用。
?数据科学工具库速查表 | Pandas 速查表
?数据科学工具库速查表 | Seaborn 速查表
?图解数据分析:从入门到精通系列教程
? 数据&字段说明
我们本次使用到的数据集字段基本说明如下:
| 列名 | 含义 |
|---|---|
| Age | 年龄 |
| Attrition | 离职 |
| BusinessTravel | 出差:0-不出差、1-偶尔出差、2-经常出差 |
| Department | 部门:1-人力资源、2-科研、3-销售 |
| DistanceFromHome | 离家距离 |
| Education | 教育程度:1-大学一下、2-大学、3-学士、4-硕士、5-博士 |
| EducationField | 教育领域 |
| EnvironmentSatisfaction | 环境满意度 |
| Gender | 性别:1-Mae男、0- Female女 |
| Joblnvolvement | 工作投入 |
| JobLevel | 职位等级 |
| JobRole | 工作岗位 |
| JobSatisfaction | 工作满意度 |
| Maritalstatus | 婚姻状况:0- Divorced离婚、1- Single未婚、2-已婚 |
| Monthlylncome | 月收入 |
| NumCompaniesWorked | 服务过几家公司 |
| OverTime | 加班 |
| RelationshipSatisfaction | 关系满意度 |
| StockOptionLevel | 股权等级 |
| TotalworkingYears | 总工作年限 |
| TrainingTimesLastYear | 上一年培训次数 |
| WorkLifeBalance | 工作生活平衡 |
| YearsAtCompany | 工作时长 |
| YearsInCurrentRole | 当前岗位在职时长 |
| YearsSinceLastPromotion | 上次升职时间 |
| YearsWithCurrManager | 和现任经理时长 |
? 数据速览
下面我们先导入所需工具库、加载数据集并查看数据基本信息:
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("darkgrid")
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns',100)
print("import complete")
# 读取数据
data = pd.read_csv("HR-Employee-Attrition.csv")
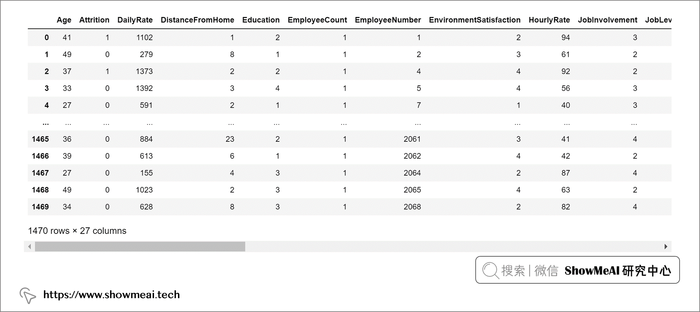
data.head()

查看前 5 条数据记录后,我们了解了一些基本信息:
① 数据包含『数值型』和『类别型』两种类型的特征。
② 有不少离散的数值特征。
? 查看数据基本信息
接下来我们借助工具库进一步探索数据。
# 字段、类型、缺失情况
data.info()

我们使用命令 data.info``() 来获取数据的信息,包括总行数(样本数)和总列数(字段数)、变量的数据类型、数据集中非缺失的数量以及内存使用情况。
从数据集的信息可以看出,一共有 35 个特征,Attrition 是目标字段,26 个变量是整数类型变量,9 个是对象类型变量。
? 缺失值检测&处理
我们先来做一下缺失值检测与处理,缺失值的存在可能会降低模型效果,也可能导致模型出现偏差。
# 查看缺失值情况
data.isnull().sum()

从结果可以看出,数据集中没有缺失值。
? 特征编码
因为目标特征“Attrition”是一个类别型变量,为了分析方便以及能够顺利建模,我们对它进行类别编码(映射为整数值)。
#since Attrition is a categotical in nature so will be mapping it with integrs variables for further analysis
data.Attrition = data.Attrition.map({"Yes":1,"No":0})
? 数据统计概要
接下来,我们借助于pandas的describe函数检查数值特征的统计摘要:
#checking statistical summary
data.describe().T
注意这里的“.T”是获取数据帧的转置,以便更好地分析。

从统计摘要中,我们得到数据的统计信息,包括数据的中心趋势——平均值、中位数、众数和散布标准差和百分位数,最小值和最大值等。
? 数值型特征分析
我们进一步对数值型变量进行分析
# 选出数值型特征
numerical_feat = data.select_dtypes(include=['int64','float64'])
numerical_feat
print(numerical_feat.columns)
print("No. of numerical variables :",len(numerical_feat.columns))
print("Number of unique values \n",numerical_feat.nunique())

我们有以下观察结论:
① 共有27个数值型特征变量
② 月收入、日费率、员工人数、月费率等为连续数值
③ 其余变量为离散数值(即有固定量的候选取值)
我们借助于 seaborn 工具包中的分布图方法 sns.distplot() 来绘制数值分布图
# 数据分析&分布绘制
plt.figure(figsize=(25,30))
plot = 1
for var in numerical_feat:
plt.subplot(9,3,plot)
sns.distplot(data[var],color='skyblue')
plot+=1
plt.show()
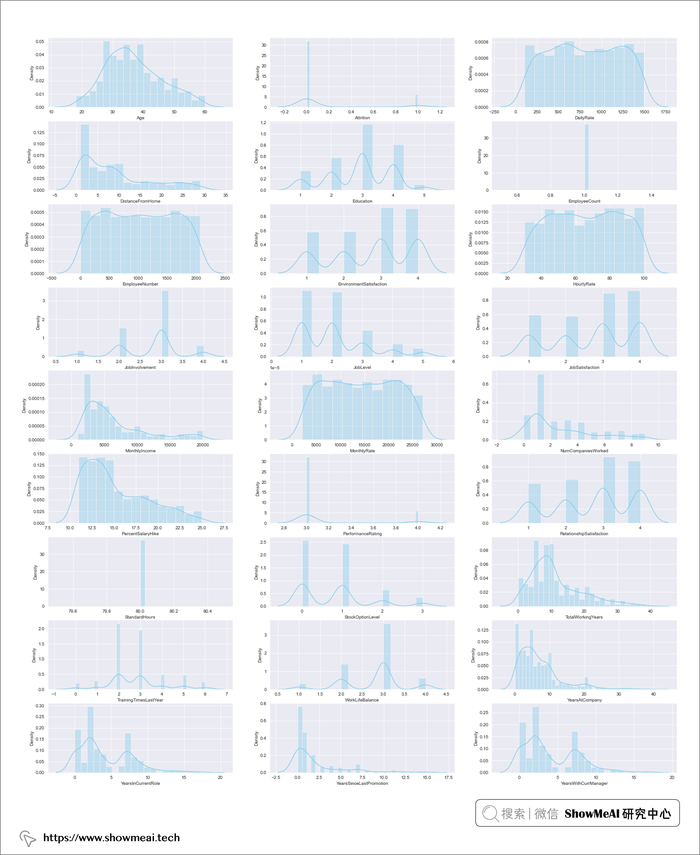
通过以上分析,我们获得以下一些基本观察和结论:
- 大多数员工都是 30 多岁或 40 多岁
- 大多数员工具有 3 级教育
- 大多数员工将环境满意度评为 3 和 4
- 大多数员工的工作参与度为 3 级
- 大多数员工来自工作级别 1 和 2
- 大多数员工将工作满意度评为 3 和 4
- 大多数员工只在 1 个公司工作过
- 大多数员工的绩效等级为 3
- 大多数员工要么没有股票期权,要么没有一级股票期权
- 大多数员工有 5-10 年的工作经验
- 大多数员工的工作与生活平衡评分为 3
接下来我们对目标变量做点分析:
# 目标变量分布
sns.countplot('Attrition',data=data)
plt.title("Distribution of Target Variable")
plt.show()
print(data.Attrition.value_counts())
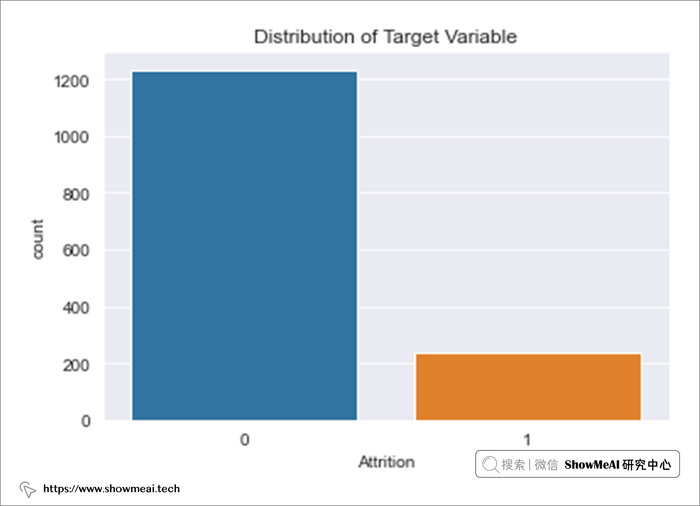
我们可以看到数据集中存在类别不平衡问题(流失的用户占比少)。类别不均衡情况下,我们要选择更有效的评估指标(如auc可能比accuracy更有效),同时在建模过程中做一些优化处理。
我们分别对各个字段和目标字段进行联合关联分析。
# Age 与 attrition
age=pd.crosstab(data.Age,data.Attrition)
age.div(age.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(14,7),cmap='spring')
plt.title("Age vs Attrition",fontsize=20)
plt.show()

# Distance from home 与 attrition
dist=pd.crosstab(data.DistanceFromHome,data.Attrition)
dist.div(dist.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7))
plt.title("Distance From Home vs Attrition",fontsize=20)
plt.show()

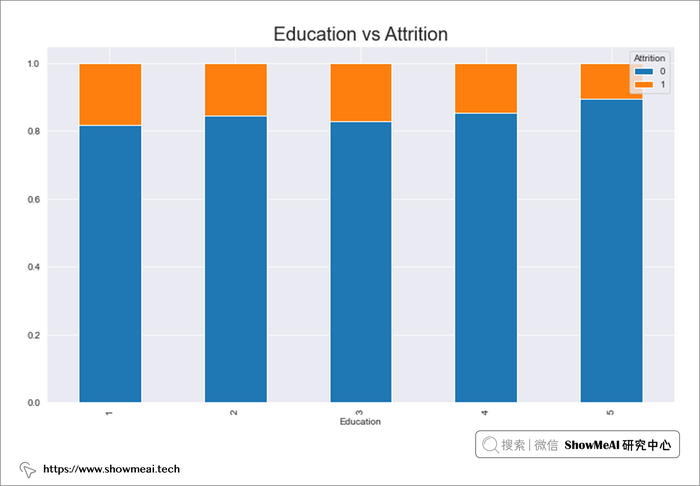
# Education 与 Attrition
edu=pd.crosstab(data.Education,data.Attrition)
edu.div(edu.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7))
plt.title("Education vs Attrition",fontsize=20)
plt.show()
# Environment Satisfaction 与 Attrition
esat=pd.crosstab(data.EnvironmentSatisfaction,data.Attrition)
esat.div(esat.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='BrBG')
plt.title("Environment Satisfaction vs Attrition",fontsize=20)
plt.show()

# Job Involvement 与 Attrition
job_inv=pd.crosstab(data.JobInvolvement,data.Attrition)
job_inv.div(job_inv.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Spectral')
plt.title("Job Involvement vs Attrition",fontsize=20)
plt.show()

# Job Level 与 Attrition
job_lvl=pd.crosstab(data.JobLevel,data.Attrition)
job_lvl.div(job_lvl.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='prism_r')
plt.title("Job Level vs Attrition",fontsize=20)
plt.show()
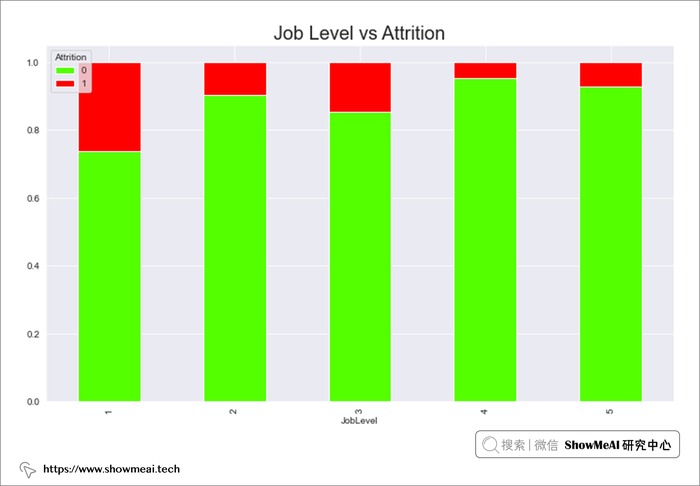
# Job Satisfaction 与 Attrition
job_sat=pd.crosstab(data.JobSatisfaction,data.Attrition)
job_sat.div(job_sat.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='inferno')
plt.title("Job Satisfaction vs Attrition",fontsize=20)
plt.show()
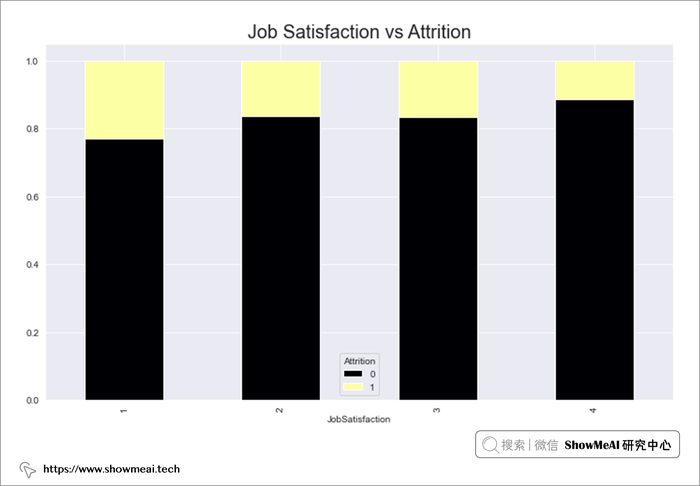
# Number of Companies Worked 与 Attrition
num_org=pd.crosstab(data.NumCompaniesWorked,data.Attrition)
num_org.div(num_org.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='cividis_r')
plt.title("Number of Companies Worked vs Attrition",fontsize=20)
plt.show()
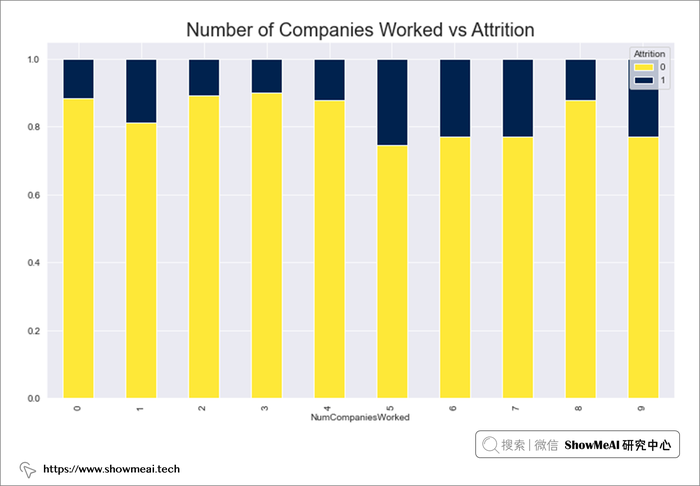
# Percent Salary Hike 与 Attrition
sal_hike_percent=pd.crosstab(data.PercentSalaryHike,data.Attrition)
sal_hike_percent.div(sal_hike_percent.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='RdYlBu')
plt.title("Percent Salary Hike vs Attrition",fontsize=20)
plt.show()
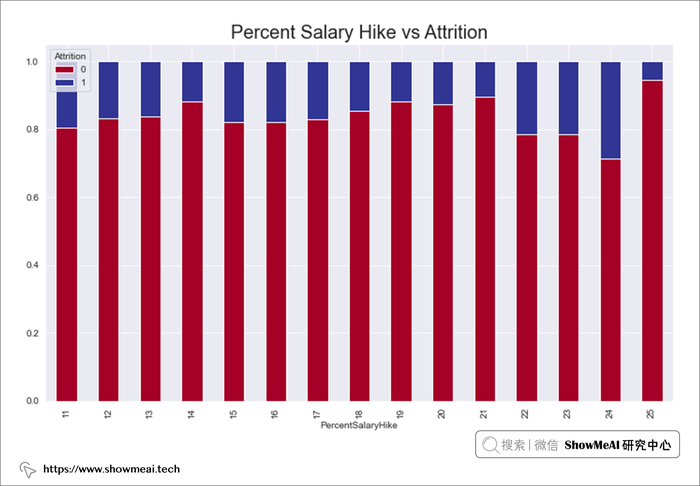
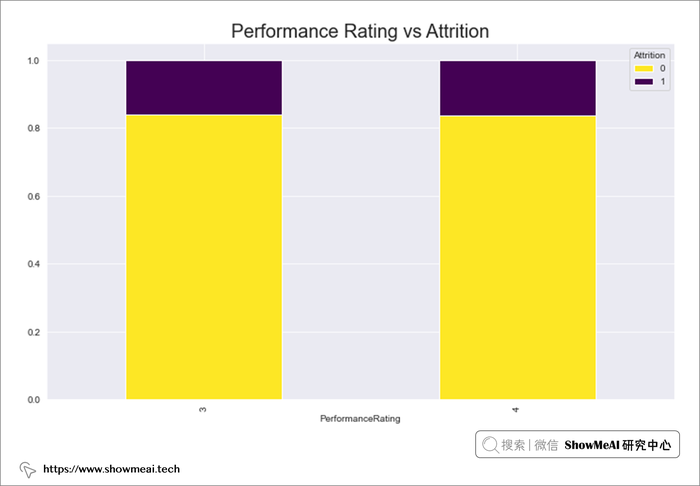
# Performance Rating 与 Attrition
performance=pd.crosstab(data.PerformanceRating,data.Attrition)
performance.div(performance.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='viridis_r')
plt.title("Performance Rating vs Attrition",fontsize=20)
plt.show()
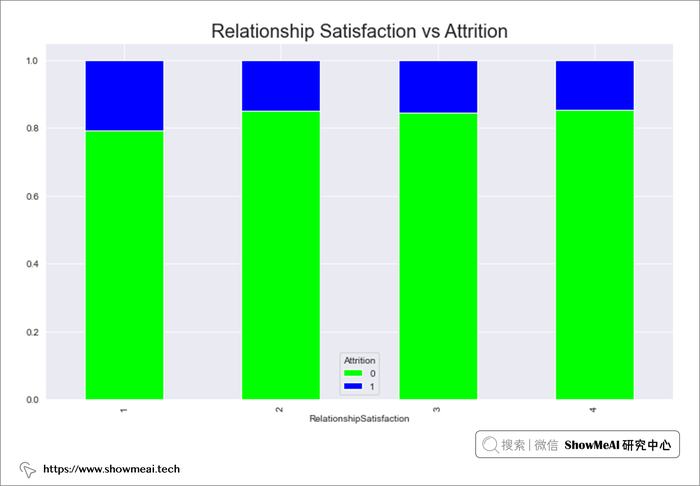
# Relationship Satisfaction 与 Attrition
rel_sat=pd.crosstab(data.RelationshipSatisfaction,data.Attrition)
rel_sat.div(rel_sat.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='brg_r')
plt.title("Relationship Satisfaction vs Attrition",fontsize=20)
plt.show()
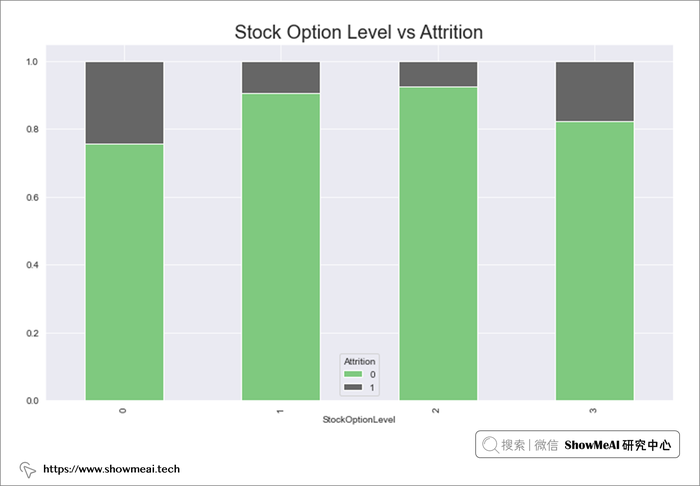
# Stock Option Level 与 Attrition
stock_opt=pd.crosstab(data.StockOptionLevel,data.Attrition)
stock_opt.div(stock_opt.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Accent')
plt.title("Stock Option Level vs Attrition",fontsize=20)
plt.show()
# Training Times Last Year 与 Attrition
tr_time=pd.crosstab(data.TrainingTimesLastYear,data.Attrition)
tr_time.div(tr_time.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='coolwarm')
plt.title("Training Times Last Year vs Attrition",fontsize=20)
plt.show()

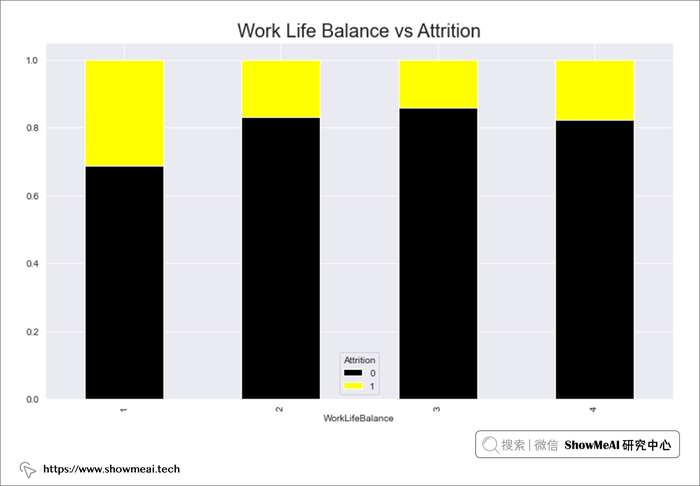
# Work Life Balance 与 Attrition
work=pd.crosstab(data.WorkLifeBalance,data.Attrition)
work.div(work.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='gnuplot')
plt.title("Work Life Balance vs Attrition",fontsize=20)
plt.show()
# Years With Curr Manager 与 Attrition
curr_mang=pd.crosstab(data.YearsWithCurrManager,data.Attrition)
curr_mang.div(curr_mang.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='OrRd_r')
plt.title("Years With Curr Manager vs Attrition",fontsize=20)
plt.show()

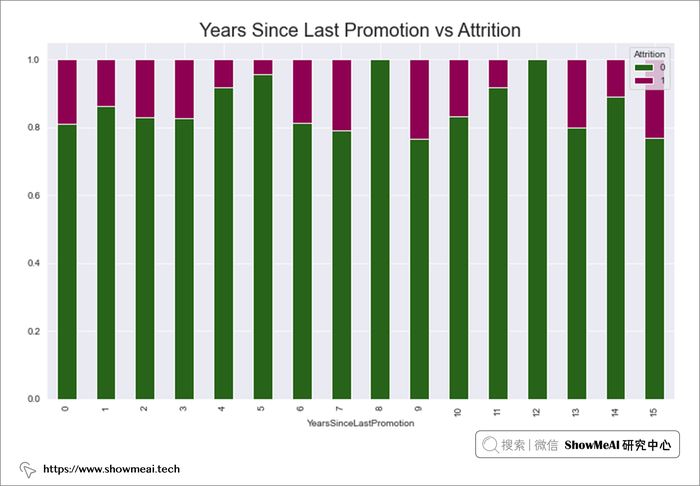
# Years Since Last Promotion 与 Attrition
prom=pd.crosstab(data.YearsSinceLastPromotion,data.Attrition)
prom.div(prom.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='PiYG_r')
plt.title("Years Since Last Promotion vs Attrition",fontsize=20)
plt.show()
# Years In Current Role 与 Attrition
role=pd.crosstab(data.YearsInCurrentRole,data.Attrition)
role.div(role.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='terrain')
plt.title("Years In Current Role vs Attrition",fontsize=20)
plt.show()

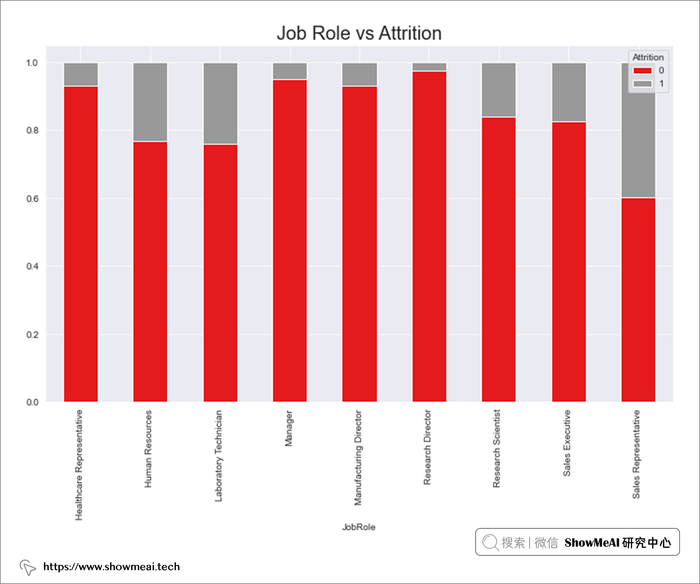
这些堆积条形图显示了员工流失情况与各个字段取值的关系,从上图我们可以得出以下基本结论:
- 30 岁以下或特别是年轻的员工比年长员工的流失率更高。
- 离家较远的员工的流失率较高,即如果员工住在附近,他或她离开公司的机会较小。
- 3 级和1 级教育的流失率较高,5 级教育的流失率最低,高等教育水平的候选人稳定性更高。
- 环境满意度低会导致较高的人员流失率,满意度1 级的人员流失率较高,4 级人员的流失率最低。
- 工作参与级别 1 的员工流失率较高,级别 4 的员工流失率最低,这意味着工作参与度更高的员工离职机会较低。
- 级别 1 和级别 3 的员工流失率较高,级别 5 的员工流失率最低,即职位级别较高的员工流失的可能性较小。
- 工作满意度级别 1 的员工流失率较高,级别 4 的员工流失率最低,工作满意度较高的员工流失的可能性较小。
- 在超过四家公司工作过的员工流失率较高,这个字段本身在一定程度上体现了员工的稳定性。
- 1 级关系满意度较高,4 级最少,这意味着与雇主关系好的员工流失可能性较低。
- 股票期权级别为 0 的员工流失率较高,而级别 1 和 2 的员工流失率较低,这意味着如果员工持有股票,会更倾向于留下
- 工作与生活平衡水平为 1 的员工流失率高,或者我们可以说工作与生活平衡低的员工更可能流失。
- 自过去 8 年以来未晋升的员工有大量流失。
- 随着与经理相处的时间变长,员工流失率会下降。
? 类别型特征分析
现在我们对类别型特征进行分析,在这里我们使用饼图和堆积条形图来分析它们的分布以及它们和目标变量的相关性。
# 分析Buisness Travel
colors=['red','green','blue']
size = data.BusinessTravel.value_counts().values
explode_list=[0,0.05,0.1]
plt.figure(figsize=(15,10))
plt.pie(size,labels=None,explode=explode_list,colors=colors,autopct="%1.1f%%",pctdistance=1.15)
plt.title("Business Travel",fontsize=15)
plt.legend(labels=['Travel_Rarely','Travel_Frequently','Non-Travel'],loc='upper left')
plt.show()
.values
explode_list=[0,0.05,0.06]
plt.figure(figsize=(15,10))
plt.pie(size,labels=None,explode=explode_list,colors=colors,autopct="%1.1f%%",pctdistance=1.1)
plt.title("Department",fontsize=15)
plt.legend(labels=['Sales','Research & Development','Human Resources'],loc='upper left')
plt.show()
.values
explode_list=[0,0.05,0.05,0.08,0.08,0.1]
plt.figure(figsize=(15,10))
plt.pie(size,labels=None,explode=explode_list,colors=colors,autopct="%1.1f%%",pctdistance=1.1)
plt.title("Education Field",fontsize=15)
plt.legend(labels=['Life Sciences','Other','Medical','Marketing','Technical Degree','Human Resources'],loc='upper left')
plt.show()
.values
explode_list=[0,0.05,0.05,0.05,0.08,0.08,0.08,0.1,0.1]
plt.figure(figsize=(15,10))
plt.pie(size,labels=None,explode=explode_list,colors=colors,autopct="%1.1f%%",pctdistance=1.1)
plt.title("Job Role",fontsize=15)
plt.legend(labels=['Sales Executive','Research Scientist','Laboratory Technician','Manufacturing Director','Healthcare Representative','Manager','Sales Representative','Research Director','Human Resources'],loc='upper left')
plt.show()
)
plt.title('Gender distribution',fontsize=15)
sns.countplot('Gender',data=data,palette='magma')

trav.div(trav.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Set1')
plt.title("Business Travel vs Attrition",fontsize=20)
plt.show()
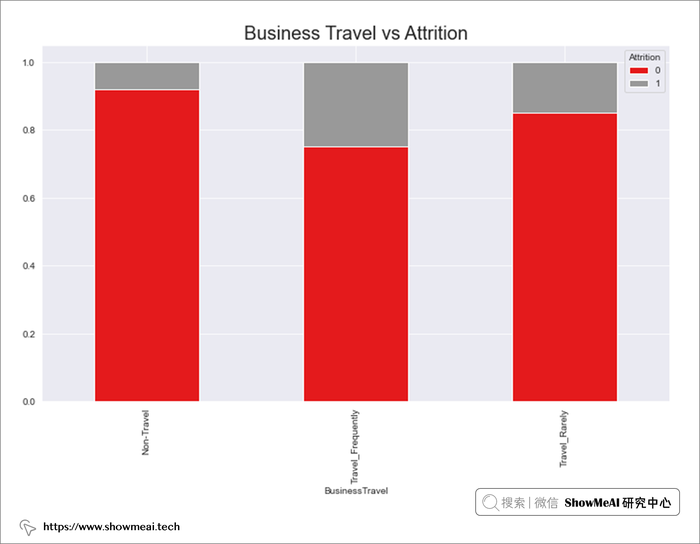
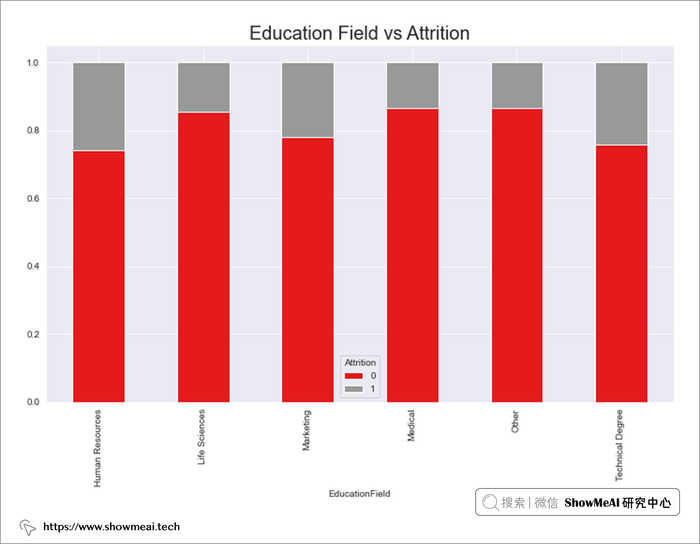
# Department 与 Attrition
dept = pd.crosstab(data.Department,data.Attrition)
dept.div(dept.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Set1')
plt.title("Department vs Attrition",fontsize=20)
plt.show()
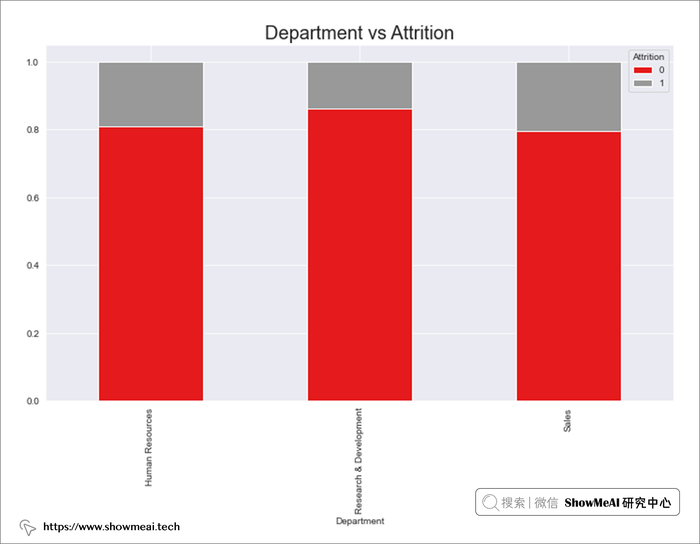
# Education Field 与 Attrition
edu_f = pd.crosstab(data.EducationField,data.Attrition)
edu_f.div(edu_f.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Set1')
plt.title("Education Field vs Attrition",fontsize=20)
plt.show()
# Job Role 与 Attrition
jobrole = pd.crosstab(data.JobRole,data.Attrition)
jobrole.div(jobrole.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Set1')
plt.title("Job Role vs Attrition",fontsize=20)
plt.show()
# Marital Status 与 Attrition
mary = pd.crosstab(data.MaritalStatus,data.Attrition)
mary.div(mary.sum(1),axis=0).plot(kind='bar',stacked=True,figsize=(12,7),cmap='Set1')
plt.title("Marital Status vs Attrition",fontsize=20)
plt.show()

# gender 与 Attrition
plt.figure(figsize=(10,9))
plt.title('Gender distribution',fontsize=15)
sns.countplot('Gender',data=data,palette='magma')
)
sns.heatmap(data.corr(method='spearman'),annot=True,cmap='Accent')
plt.title('Correlation of features',fontsize=20)
plt.show()

# 相关度排序
plt.figure(figsize=(15,9))
correlation = data . corr(method='spearman')
correlation.Attrition.sort_values(ascending=False).drop('Attrition').plot.bar(color='r')
plt.title('Correlation of independent features with target feature',fontsize=20)
plt.show()
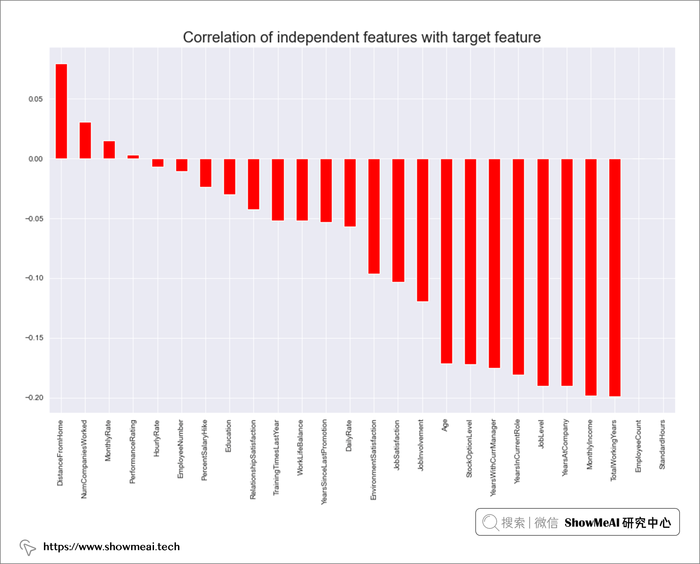
? 异常值检测与处理
下面我们检测一下数据集中的异常值,在这里,我们使用箱线图来可视化分布并检测异常值。
# 绘制箱线图
plot=1
plt.figure(figsize=(15,30))
for i in numerical_feat.columns:
plt.subplot(9,3,plot)
sns.boxplot(data[i],color='navy')
plt.xlabel(i)
plot+=1
plt.show()

箱线图显示数据集中有不少异常值,不过这里的异常值主要是因为离散变量(可能是取值较少的候选),我们将保留它们(不然会损失掉这些样本信息),不过我们注意到月收入的异常值比较奇怪,这可能是由于数据收集错误造成的,可以清洗一下。
? 特征工程
关于机器学习特征工程,大家可以参考 ShowMeAI 整理的特征工程最全解读教程。
? 类别均衡处理
下面我们来完成特征工程的部分,从原始数据中抽取强表征的信息,以便模型能更直接高效地挖掘和建模。
我们在EDA过程中发现 MonthlyIncome、JobLevel 和 YearsAtCompany 以及 YearsInCurrentRole 高度相关,可能会带来多重共线性问题,我们会做一些筛选,同时我们会删除一些与 EmployeeCount、StandardHours 等变量不相关的特征,并剔除一些对预测不重要的特征。
dataset = data.copy()
# 删除与目标相关性低的Employee count 和 standard hours特征
dataset.drop(['EmployeeCount','StandardHours'],inplace=True,axis=1)
dataset.head(2)

下面我们对类别型特征进行编码,包括数字映射与独热向量编码。
# 按照出差的频度进行编码
dataset.BusinessTravel = dataset.BusinessTravel.replace({
'Non-Travel':0,'Travel_Rarely':1,'Travel_Frequently':2
})
# 性别与overtime编码
dataset.Gender = dataset.Gender.replace({'Male':1,'Female':0})
dataset.OverTime = dataset.OverTime.replace({'Yes':1,'No':0})
# 独热向量编码
new_df = pd.get_dummies(data=dataset,columns=['Department','EducationField','JobRole', 'MaritalStatus'])
new_df
处理与转换后的数据如下所示:
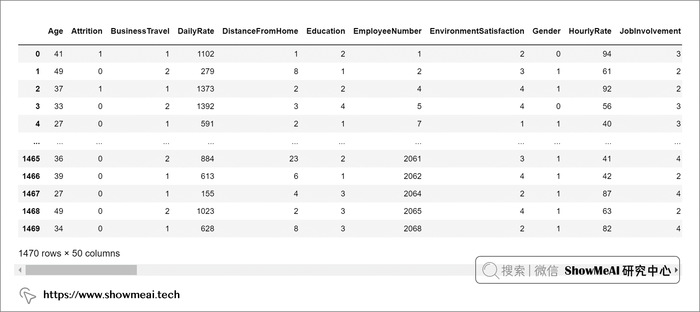
在前面的数据探索分析过程中,我们发现目标变量是类别不平衡的,因此可能会导致模型偏向多数类而带来偏差。我们在这里会应用过采样技术 SMOTE(合成少数类别的样本补充)来处理数据集中的类别不平衡问题。
我们把数据先切分为特征和标签,处理之前的标签类别比例如下:
# 切分特征和标签
X = new_df.drop(['Attrition'],axis=1)
Y = new_df.Attrition
# 标签01取值比例
sns.countplot(data=new_df,x=Y,palette='Set1')
plt.show()
print(Y.value_counts())

x,y = sm.fit_resample(X,Y)
print(x.shape," \t ",y.shape)
# (2466, 45) (2466,)
过采样后
# 过采样之后的比例
sns.countplot(data=new_df,x=y,palette='Set1')
plt.show()
print(y.value_counts())

x_scaled = scaler.fit_transform(x)
x_scaled = pd.DataFrame(x_scaled, columns=x.columns)
x_scaled
处理后我们的数据集看起来像这样
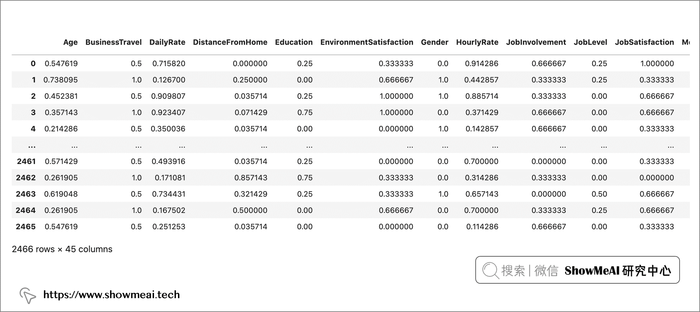
所有取值都已调整到 0 -1 的幅度范围内。
? 分析特征重要性
通常在特征工程之后,我们会得到非常多的特征,太多特征会带来模型训练性能上的问题,不相关的差特征甚至会拉低模型的效果。
我们很多时候会进行特征重要度分析的工作,筛选和保留有效特征,而对其他特征进行剔除。我们先将数据集拆分为训练集和测试集,再基于互信息判定特征重要度。
## 训练集测试集切分
from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest = train_test_split(x_scaled,y,test_size=0.3,random_state=1)
我们使用 sklearn.feature_selection 类中的mutual_info_classif 方法来获得特征重要度。Mutual _info_classif的工作原理是类似信息增益。
from sklearn.feature_selection import mutual_info_classif
mutual_info = mutual_info_classif(xtrain,ytrain)
mutual_info

下面我们绘制一下特征重要性
mutual_info = pd.Series(mutual_info)
mutual_info.index = xtrain.columns
mutual_info.sort_values(ascending=False)
plt.title("Feature Importance",fontsize=20)
mutual_info.sort_values().plot(kind='barh',figsize=(12,9),color='r')
plt.show()
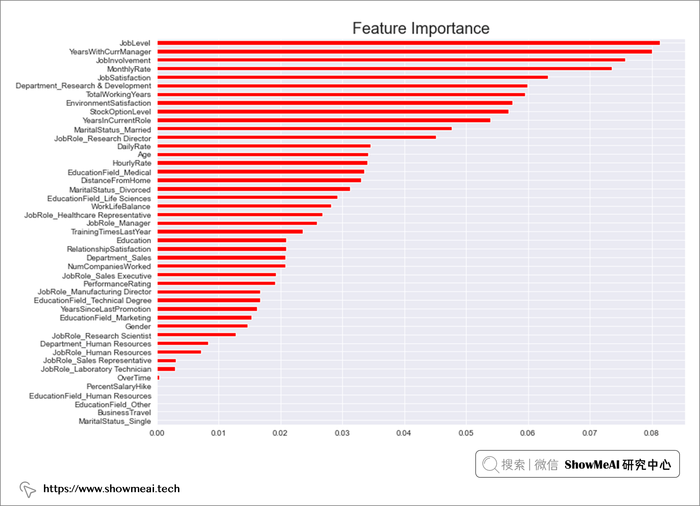
当然,实际判定特征重要度的方式有很多种,甚至结果也会有一些不同,我们只是基于这个步骤,进行一定的特征筛选,把最不相关的特征剔除。
? 模型构建和评估
关于建模与评估,大家可以参考 ShowMeAI 的机器学习系列教程与模型评估基础知识文章。
?图解机器学习算法:从入门到精通系列教程
?图解机器学习算法(1) | 机器学习基础知识
?图解机器学习算法(2) | 模型评估方法与准则
好,我们前序工作就算完毕啦!下面要开始构建模型了。在建模之前,有一件非常重要的事情,是我们需要选择合适的评估指标对模型进行评估,这能给我们指明模型优化的方向,我们在这里,针对分类问题,尽量覆盖地选择了下面这些评估指标
- 准确度得分
- 混淆矩阵
- precision
- recall
- F1-score
- Auc-Roc
我们这里选用了8个模型构建baseline,并应用交叉验证以获得对模型无偏的评估结果。
# 导入工具库
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import BernoulliNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score,cross_validate
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score,plot_roc_curve,roc_curve,auc,roc_auc_score,precision_score,r
# 初始化baseline模型(使用默认参数)
LR = LogisticRegression()
KNN = KNeighborsClassifier()
SVC = SVC()
DTC = DecisionTreeClassifier()
BNB = BernoulliNB()
RTF = RandomForestClassifier()
ADB = AdaBoostClassifier()
GB = GradientBoostingClassifier()
# 构建模型列表
models = [("Logistic Regression ",LR),
("K Nearest Neighbor classifier ",KNN),
("Support Vector classifier ",SVC),
("Decision Tree classifier ",DTC),
("Random forest classifier ",RTF),
("AdaBoost classifier",ADB),
("Gradient Boosting classifier ",GB),
("Naive Bayes classifier",BNB)]
接下来我们遍历这些模型进行训练和评估:
for name,model in models:
model.fit(xtrain,ytrain)
print(name," trained")
# 遍历评估
train_scores=[]
test_scores=[]
Model = []
for name,model in models:
print("******",name,"******")
train_acc = accuracy_score(ytrain,model.predict(xtrain))
test_acc = accuracy_score(ytest,model.predict(xtest))
print('Train score : ',train_acc)
print('Test score : ',test_acc)
train_scores.append(train_acc)
test_scores.append(test_acc)
Model.append(name)
# 不同的评估准则
precision_ =[]
recall_ = []
f1score = []
rocauc = []
for name,model in models:
print("******",name,"******")
cm = confusion_matrix(ytest,model.predict(xtest))
print("\n",cm)
fpr,tpr,thresholds=roc_curve(ytest,model.predict(xtest))
roc_auc= auc(fpr,tpr)
print("\n","ROC_AUC_SCORE : ",roc_auc)
rocauc.append(roc_auc)
print(classification_report(ytest,model.predict(xtest)))
precision = precision_score(ytest, model.predict(xtest))
print('Precision: ', precision)
precision_.append(precision)
recall = recall_score(ytest, model.predict(xtest))
print('Recall: ', recall)
recall_.append(recall)
f1 = f1_score(ytest, model.predict(xtest))
print('F1 score: ', f1)
f1score.append(f1)
plt.figure(figsize=(10,20))
plt.subplot(211)
print(sns.heatmap(cm,annot=True,fmt='d',cmap='Accent'))
plt.subplot(212)
plt.plot([0,1],'k--')
plt.plot(fpr,tpr)
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.show()
我们把所有的评估结果汇总,得到一个模型结果对比表单
# 构建一个Dataframe存储所有模型的评估指标
evaluate = pd.DataFrame({})
evaluate['Model'] = Model
evaluate['Train score'] = train_scores
evaluate['Test score'] = test_scores
evaluate['Precision'] = precision_
evaluate['Recall'] = recall_
evaluate['F1 score'] = f1score
evaluate['Roc-Auc score'] = rocauc
evaluate
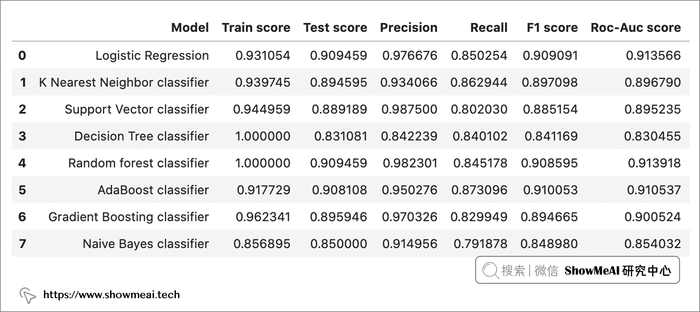
我们从上述baseline模型的汇总评估结果里看到:
- 逻辑回归和随机森林在所有模型中表现最好,具有最高的训练和测试准确度得分,并且它具有低方差的泛化性
- 从precision精度来看,逻辑回归0.976、随机森林0.982,也非常出色
- 从recall召回率来看,Adaboost、逻辑回归、KNN表现都不错
- F1-score会综合precision和recall计算,这个指标上,逻辑回归、随机森林、Adaboost表现都不错
- Roc-Auc评估的是排序效果,它对于类别不均衡的场景,评估非常准确,这个指标上,逻辑回归和随机森林、Adaboost都不错
我们要看一下最终的交叉验证得分情况
# 查看交叉验证得分
for name,model in models:
print("******",name,"******")
cv_= cross_val_score(model,x_scaled,y,cv=5).mean()
print(cv_)

从交叉验证结果上看,随机森林表现最优,我们把它选为最佳模型,并将进一步对它进行调优以获得更高的准确性。
? 超参数调优
关于建模与评估,大家可以参考ShowMeAI的相关文章。
我们刚才建模过程,使用的都是模型的默认超参数,实际超参数的取值会影响模型的效果。我们有两种最常用的方法来进行超参数调优:
- 网格搜索:模型针对具有一定范围值的超参数网格进行评估,尝试参数值的每种组合,并实验以找到最佳超参数,计算成本很高。
- 随机搜索:这种方法评估模型的超参数值的随机组合以找到最佳参数,计算成本低于网格搜索。
下面我们演示使用随机搜索调参优化。
from sklearn.model_selection import RandomizedSearchCV
params = {'n_estimators': [int(x) for x in np.linspace(start = 100, stop = 1200, num = 12)],
'criterion':['gini','entropy'],
'max_features': ['auto', 'sqrt'],
'max_depth': [int(x) for x in np.linspace(5, 30, num = 6)],
'min_samples_split': [2, 5, 10, 15, 100],
'min_samples_leaf': [1, 2, 5, 10]
}
random_search=RandomizedSearchCV(RTF,param_distributions=params,n_jobs=-1,cv=5,verbose=5)
random_search.fit(xtrain,ytrain)
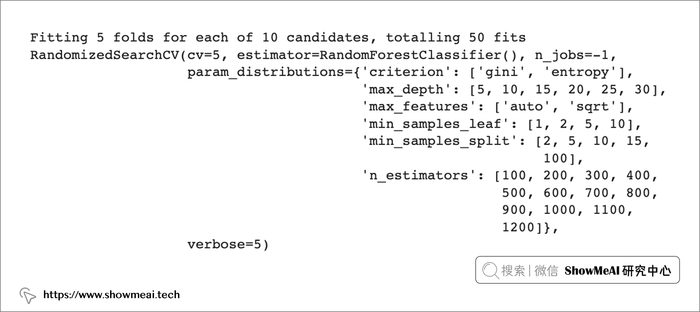
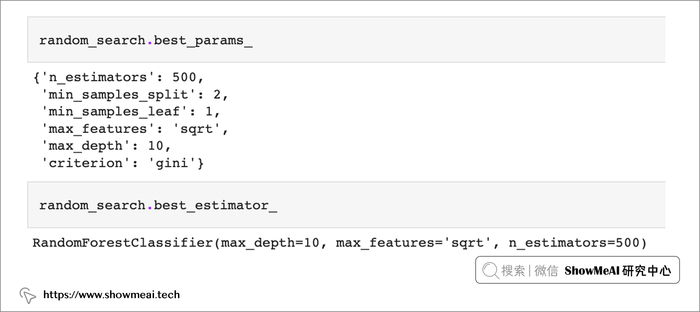
拟合随机搜索后,我们取出最佳参数和最佳估计器。
random_search.best_params_
random_search.best_estimator_
我们对最佳估计器进行评估
# 最终模型
final_mod = RandomForestClassifier(max_depth=10, max_features='sqrt', n_estimators=500)
final_mod.fit(xtrain,ytrain)
final_pred = final_mod.predict(xtest)
print("Accuracy Score",accuracy_score(ytest,final_pred))
cross_val = cross_val_score(final_mod,x_scaled,y,scoring='accuracy',cv=5).mean()
print("Cross val score",cross_val)
plot_roc_curve(final_mod,xtest,ytest)

我们可以看到,超参数调优后:
- 模型的整体性能有所提升。
- 准确度和交叉严重分数提高了。
- Auc 得分达到了97%。
? 保存模型
最后我们对模型进行存储,以便后续使用或者部署上线。
import joblib
joblib.dump(final_mod,'hr_attrition.pkl')
# ['hr_attrition.pkl']
参考链接
- ? 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- ? 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- ? 数据科学工具库速查表 | Seaborn 速查表:https://www.showmeai.tech/article-detail/105
- ? 图解机器学习算法:从入门到精通系列教程:https://www.showmeai.tech/tutorials/34
- ? 图解机器学习算法(1) | 机器学习基础知识:https://www.showmeai.tech/article-detail/185
- ? 图解机器学习算法(2) | 模型评估方法与准则:https://www.showmeai.tech/article-detail/186
- ? 机器学习实战 | 机器学习特征工程最全解读:https://www.showmeai.tech/article-detail/208
- ? 深度学习教程(7) | 网络优化:超参数调优、正则化、批归一化和程序框架:https://www.showmeai.tech/article-detail/218

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:员工离职困扰?来看AI如何解决,基于人力资源分析的 ML 模型构建全方案 ⛵ - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 