
如何判断导数值为零的点的类型
当发现训练数据集误差不再下降的时候,不是只有卡在局部最小值的情况,还有另外一种情况是处于鞍点,鞍点位置处虽然其导函数为零,但是其既不是局部最大值也不是局部最小值,如图:
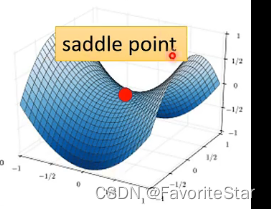

因此,我们把局部最小值和鞍点这种点统称为驻点(critical point),但这两种情况是截然不同的,因为如果是局部最小值那么周围都是比该点更大的loos,但是鞍点不一样,周围可能会有更小的loss,因此要认识到如何分辨这两种点。
判断导数为0的点是鞍点还是极值点
首先需要了解一下泰勒展开式,假设我们在\(\theta=\theta^{`}\)处进行二阶泰勒展开(忽略冗余项),即:
\]
其中,\(g\)为梯度,是一个向量,而\(H\)是一个矩阵,存放的是L的二阶微分,即:
H_{ij}=\frac{\partial^2}{\partial \theta_i \partial \theta_j}L(\theta^`)
\]

可以看成后面两项就是可以补齐这两个点之间的差距,使得值更加接近。
那么当遇到导数值为0的点是,将会有\(g=0\),那么第一项为0,那么只有第二项起作用,为了表达方便,设\(v=\theta-\theta^`\),则若
- 对于任意\(v\),均有 \(v^T Hv>0\),则相当于在\(\theta^`\)周围均有\(L(\theta)>L(\theta^`)\),那么就说明这是一个局部最小值
- 对于任意\(v\),均有 \(v^T Hv<0\),则相当于在\(\theta^`\)周围均有\(L(\theta)<L(\theta^`)\),那么就说明这是一个局部最大值
- 对于任意\(v\),有 \(v^T Hv>0\)也有 \(v^T Hv<0\),则说明该点是一个鞍点
但是总不可能把所以的\(v\)都代进去算,因此要看矩阵\(H\)的性质!
- 若\(H\)为正定矩阵(positive definite),即所有特征值(eigen valuse)都为正,那么就满足局部最小值的条件
- 若\(H\)为负定矩阵(negative definite),即所有特征值(eigen valuse)都为负,那么就满足局部最大值的条件
- 若\(H\)的特征值有正有负,那么就满足鞍点的条件
而\(H\)除了可以帮助我们判断是什么类型的点之外,还可以在梯度为0的情况下帮助我们判断下一次如何更新参数,具体推导过程如下:
假设\(u\)是矩阵\(H\)的一个特征向量,\(\lambda\)是对应的特征值,那么
\]
那么如果\(\lambda<0\),则这一项就小于0,那么如果让
\]
就可以让L减小。因此只要让\(\theta - \theta^`=u\),则\(\theta=\theta^`+u\)就可以让损失函数进一步减小,因此只要找出特征值小于0对应的特征向量,就可以继续更新参数了。
但其实这个方法在大部分情况是不可行的,因为是二阶微分的矩阵,而且求特征值和特征向量,这个计算量太大了。
另外一个需要补充的点是由于我们之间的视角都是二维或者三维视角,但实际上数据是特别高的维度的,因此能够局部最小值是非常少见的,大多数情况是一个鞍点。因为要让海参矩阵的特征值全部为正几乎是不可能的。
批次(batch)与动量(momentum)
Batch
Batch实际上是说:在进行计算损失以及梯度时,我们并不是每次都对全部的数据计算总损失再来计算梯度,而是将数据分为许多份,每一份代表一个batch,然后每次计算一个batch中的损失再计算梯度再更新参数,每一份都计算及更新完毕称为一个epoch,如下图:
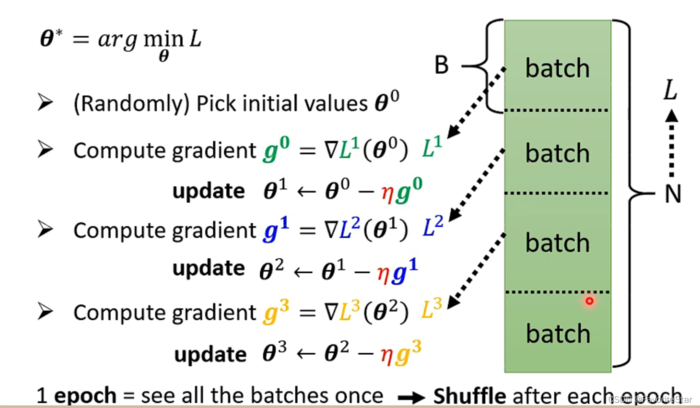
而我们可以选择执行多次的epoch,每次都有一个shuffle过程,即重新打乱顺序,重新划分batch、
而这个batch划分的大小就是一个值得讨论的问题:
- 当batch更大:虽然花费时间更长,但是总体上对梯度的计算更加精确,即更新参数更加有效
- 当batch更小:花费时间短,但是具有一定的噪声性质,更新的参数不一定是有效的
并且不一定batch大花费的时间就长,GPU具有平行运算的能力,在其能力范围内batch的增加对其计算时间基本没什么影响。而如果计算损失和梯度的时间没什么太大的差距的话,那么就会在更新参数的次数上体现出时间的差距了,如下图:

尽管batch=1能够使得每一次更新时计算资料的速度特别快,但是由于每次epoch需要进行的更新次数太多了,因此其总体一次epoch的时间是特别长的。因此在考虑平行计算后不是batch越小越好。
那么这样是不是就说明越大的batch时间没有劣势就越好了呢?并不是!来看下图:
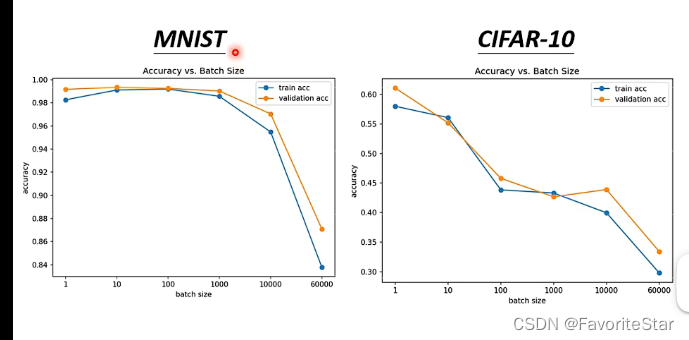
在同一个模型下,其训练数据集的精确度居然随着batch的增大而逐渐减小,因此这不是模型的问题,这就是batch改变而引起的优化算法的问题。
直观上的解释如下图:

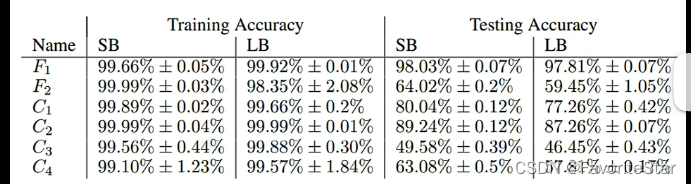
可能在整体的损失函数上陷入了局部最小值,此时如果不考虑前述的海森矩阵的话那么就无法继续进行梯度更新;但是在更小的batch上可以认为每一次选用的损失函数是具有一定差异的,在L1上陷入局部最小值那么下一次更新的时候是L2,该点并不是局部最小值,那么就还可以继续更新继续使得损失函数降低。还有论文证明了如果在训练集上想办法让大的batch和小的batch的精确度都训练到接近一样,但是在测试集上很可能会出现大的batch的模型的效果会差很多,如下图:
直观上解释可以这么认为:
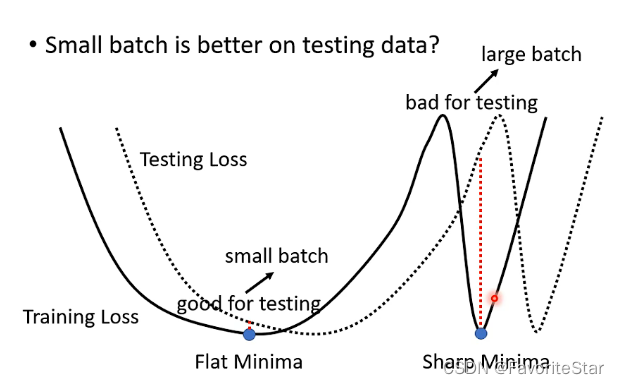
假设在训练集的误差函数上有两类最小值的点,第一种Flat Minima是比较好的,另一种Sharp Minima是比较坏的,那么对于小batch来说由于其更新参数的方向具有一定的随机性,因此即使陷入了Sharp Minima里面,也有较大的概率能够更新出来,而只有在Flat Minima里面周围都比较平坦才能够困住它们参数的更新;对于大batch如果陷入Sharp Minima之后几乎就不可能出来了,因为梯度为0。那么假设当前测试集的误差函数是相对于训练集的误差函数进行移动,那么按照刚才的说法就会导致大batch的效果很差,而小batch的效果就比较稳定。
经过上述分析,对比如下:
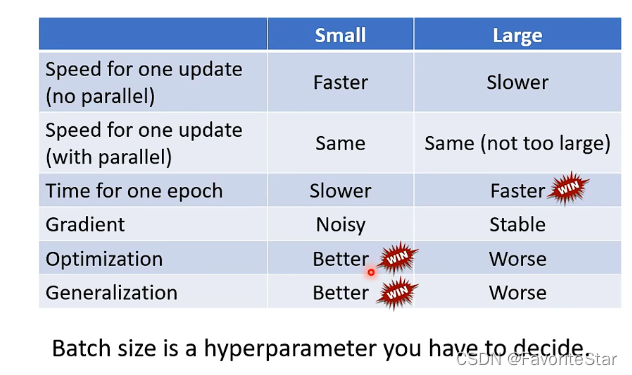
所以batch也就成为了一个需要调整的超参数。
Momentum

在现实生活中,如果具有动量,那么在损失函数的下滑中是很可能不会卡在梯度为0的鞍点或者局部最小值的,因为动量很可能会带着他继续往前走,因此要思考能不能加入这个动量的想法来解决驻点的问题呢?
先回顾一下梯度下降的过程:每一次参数更新的方向都是梯度的反方向
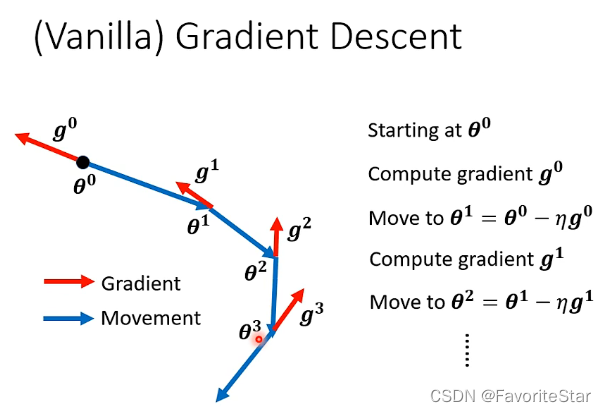
那么如果加入了动量这个因素,则移动的方向是梯度的反方向加上前一步移动的方向这两个综合起来决定的。如下图:
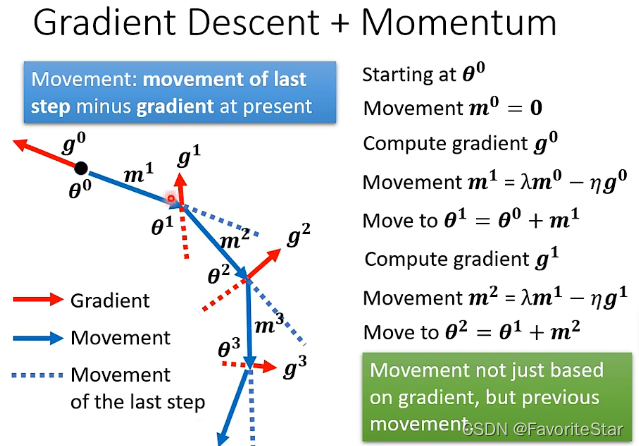
每次的方向计算为:
\]
而由于\(m^t\)与\(m^{t-1}\)和\(g^{t-1}\)有关,以此类推可以得到\(m^t\)与\(g^1\)到\(g^{t-1}\)都有关,因此另一种直观解释就是不只是考虑当前梯度的反方向,而是过去所有梯度方向的综合。
自动调整学习率
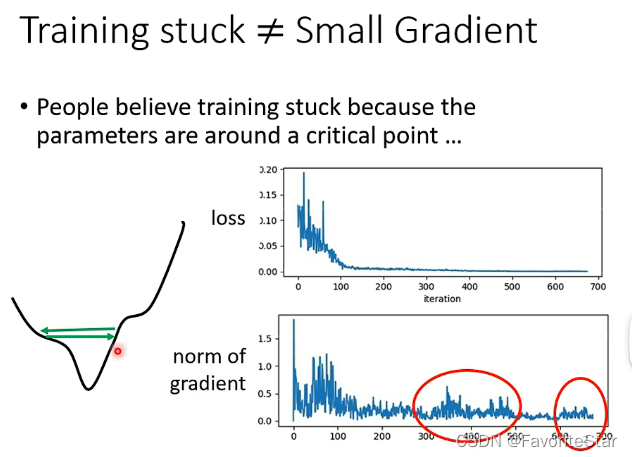
如果在训练过程中发现训练误差不再下降,这可能并不是卡在了驻点的问题,这时候需要检查一下梯度向量是否为0,如果为0,才是真正卡在了驻点的位置,但是通过下图可以发现在后续误差不再下降时其梯度仍然具有很大的变化,仍然不会零,但就是不能够再误差减小,这很可能就是在最小值的两边来回的震荡导致的。
,
而仅仅看上图可能会觉得是学习率设置得太大了,那么看下图:

如果学习率很大,那么极大地可能一直震荡,如果将学习率调整到足够小,虽然它能够进入到中间的位置然后左转去靠近最小值的点,但是在中间部分梯度已经很小了,而你的学习率也很小,所以几乎是不可能走完那一段路程的。因此需要自动调整学习率。
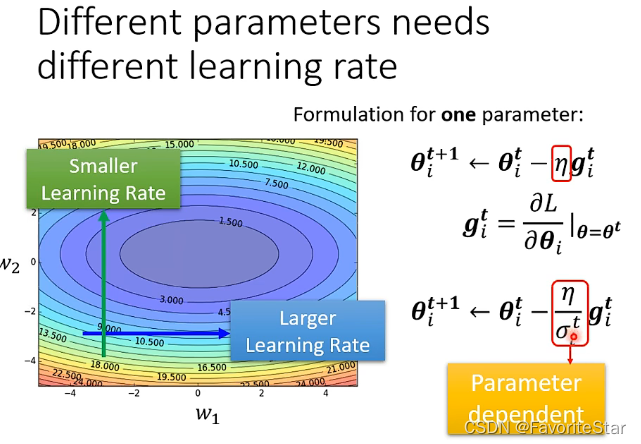
我们总希望在梯度比较小的方向上能够有较大的学习率,在梯度比较大的方向上能够有比较小的学习率,因此需要对每个参数定制学习率,即:
\]
则说明现在学习率不仅与i有关而且与t有关,因此与具体的参数有关,而且也是具有迭代性质的。更新公式如下:

这为什么能够做到在梯度比较小的方向上能够有较大的学习率,在梯度比较大的方向上能够有比较小的学习率呢?如下图:
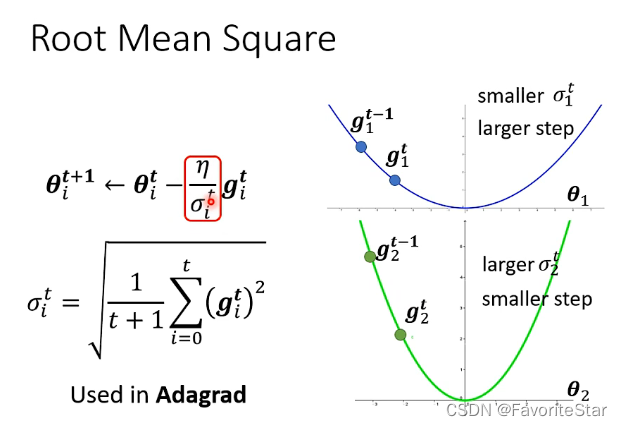
当梯度比较大,那么\(\sigma\)算出来就大,那么学习率就小,相反也同理。
但这个方法有一个问题,就是例如同一个参数在一开始其梯度比较大,后面的梯度比较小,但这样前面大的梯度已经在根号里面累积了,在梯度突然变小的时候很难让学习率立马反应过来而增大的,
因此改进为如下的RMSProp方法:
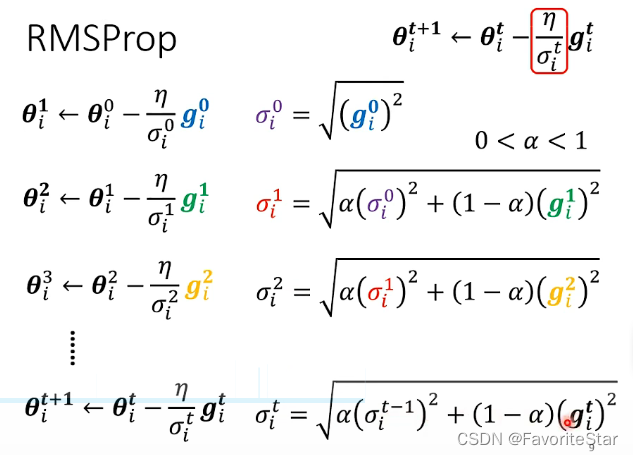
即可以手动调整权重\(\alpha\)来实时调整学习率的大小,例如下图:
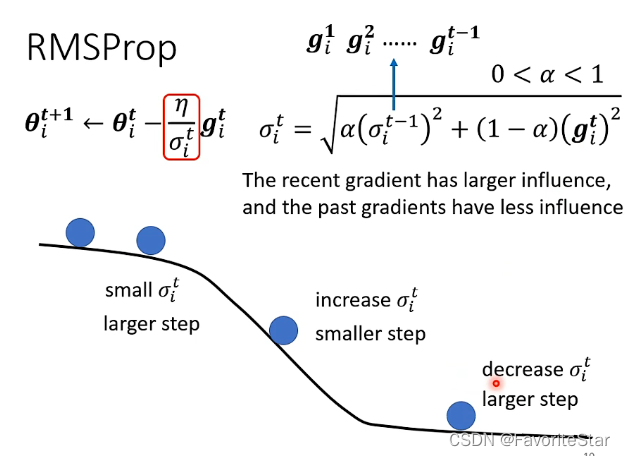
在中间滑坡的位置直接将\(\alpha\)减小,那么学习率就会降低,从而可以慢下来;而在后面平坦的位置再将\(\alpha\)增大,那么学习率就会增加。
因此现在较好的方法就是RMSProp+Momentum,称为Adam
还有另外一个可以调整的地方为固定的\(\eta\):

第二个方式有点难以理解,但可以这样解释:由于\(\sigma\)是一个累积的结果,累积一个方向的梯度有多大有多小,那么一开始仍然处于一个摸索的阶段,因此可以设置学习率比较小防止其乱飞,当累积到一定程度比较稳定之后,学习率也逐渐上升到较大的值,那么再稳定移动,此时再来慢慢减小。
那么结合上述的方法可以使用这种方法:

但有一个疑问就是\(m^t_i\)和\(\sigma^t_i\)会不会相互抵消,其实是不会的,因为m虽然考虑了所有的梯度,但是也考虑了它们的方向以及正负,而\(\sigma\)是将各个梯度的平方求和再开根号,所有并不会有抵消的作用。
损失函数的影响

对于分类问题,也可以用回归的模型,只需要将输出改为一个向量即可。
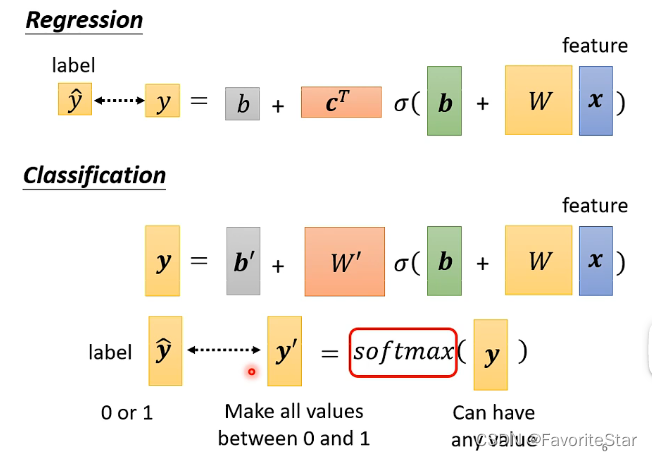
且一般来说,对于用模型计算出来的y,通常是加上一个softmax函数处理之后,再来跟理想\(\hat{y}\)进行对比相似度的。
softmax的处理过程如下:
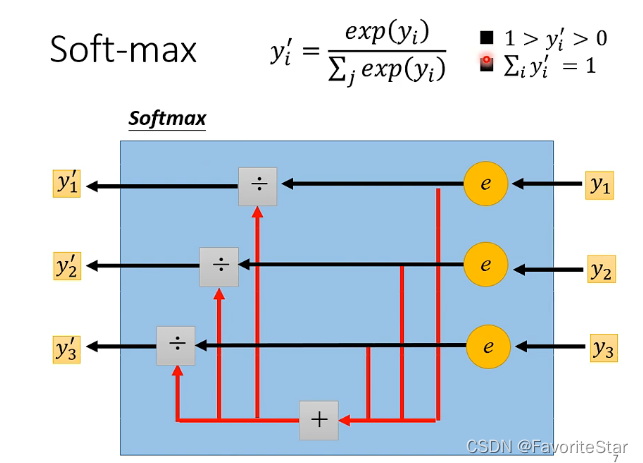
而上述的例子是三个类别,虽然softmax也可以运用在两个类别的问题上,但更多在面对两个类别的问题时是利用Sigmoid函数,,不过在两个类别时这两种方法是等价的。
而在比较\(y`\)和\(\hat{y}\)时,也有几种方法,例如:

需要知道的是最大可能性和最小化交叉熵是等价的。
下面通过一个例子来表明这两种损失函数的区别:在两张图中都可以看到,在右下角都是\(y_1\)大而\(y_2\)小,那么损失函数都很小,左上角都是\(y_1\)小而\(y_2\)大,暗恶魔损失韩式都很大,这就很满足我们的预期
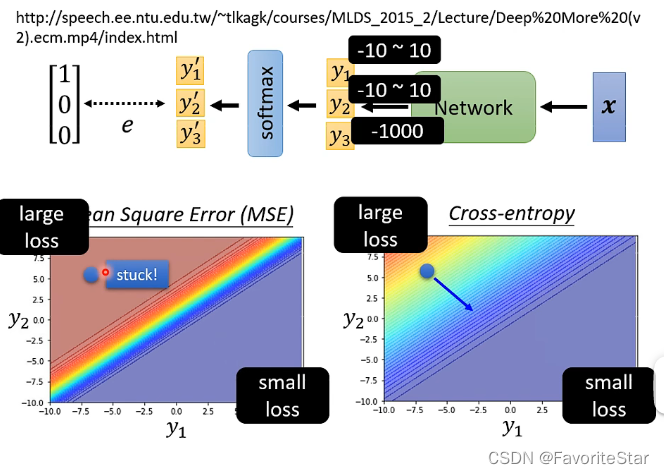
但在MSE的损失函数中,如果训练的起点位于左上方的损失函数很大的位置,其很明显的特性在于其是非常平坦的,梯度很小,大面积都很大的损失,因此训练起来就很难走往右下角,而在交叉熵中就不会有这个问题。因此在分类问题中要用交叉熵作为损失函数。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【机器学习】李宏毅——类神经网络训练不起来怎么办 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 