

这一节的主要内容是当测试数据的准确度不够高的时候应该怎么做。
首先一定要检查你的训练数据集的误差,如果发现是你的训练数据集误差也比较大,那么就有两种可能:
- 模型过于简单,无法很好的拟合当前的数据集
- 陷入局部最优价,也就是优化算法做的不够好
那么如果分辨这两种情况呢?找模型来比较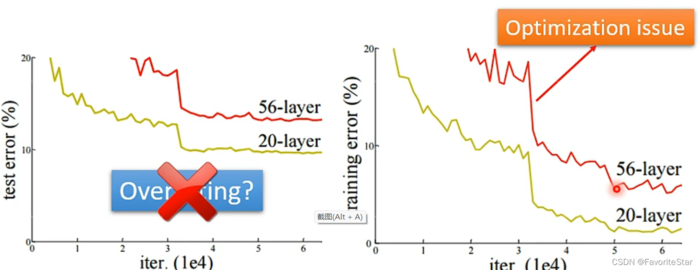

例如在上图,一个20层的神经网络和56层的神经网络,发现测试集上56层的神经网络的误差更大,那么这很容易让我们觉得这是过拟合的问题,但是如果我们检查一下训练集的误差发现,同样是56层的误差更大,这就说明不是过拟合,如果是过拟合应该是56层的网络的训练集的误差很小才对,那么56层的神经网络肯定比20层的复杂度高,只剩下一种可能就是优化算法做得不够好
那么这给我们的启发就是,在面对一个未知的问题时可以这样做:
- 先训练一些简单的模型,比如层次较低的神经网络,比较SVM,这些模型的优化算法比较容易实现,就会找到在这个模型复杂度下的最优价
- 再训练复杂的模型,如果复杂的模型明明弹性(即复杂度)比简单的模型更大,可误差反而更加不理想,那么可能就是复杂模型的优化算法做得不够好了
那么经过上述解决完训练数据的问题,使得训练数据精度足够小时再重新计算测试数据的精度,如果此时仍然是测试数据的误差很大,那么就有可能是真的遇到了过拟合的问题,甚至是遇到了mismatch问题,解决办法有两个:
- 最直接的方法就是增加训练数据集。例如找新的数据,或者对数据进行处理,图像翻转等等
- 给模型更多的限制,例如给比较少的参数,共用参数,正则化、早停等等
模型复杂度与误差的曲线大致如下:
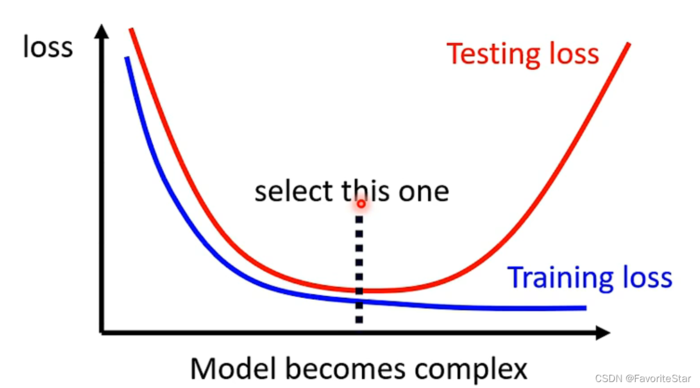
在选取不同的模型时,最好是不要直接在测试集上比较,因为测试集是用来衡量该模型的泛化误差的,因此通常是将原本的训练集分为训练集和验证集两部分,在训练集上训练各个不同的模型,然后再在验证集上选出最好的模型,再在测试集上得到该模型的泛化能力。那么这个时候就要考虑到验证集选取的问题了,为了避免随机选取到不合适的验证集,可以用k折交叉验证:
即将训练数据进行k等分,然后选取其中一个作为验证集其他作为训练集,然后训练模型并验证在验证集上的好坏,这个操作重复k次保证每一个子集都有机会当验证集,之后将k次结果去平均即可。
mismatch问题就是训练集的分布和测试集的分布是不同的分布,这就导致不管你如何增加训练集的数据或者改进模型都很难在测试集上取得好的结果。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【机器学习】李宏毅——机器学习任务攻略 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 