

假设现在有两种类别的样本,其类别分别为\(C_1\)和\(C_2\),而拥有的样本数分别为\(N_1\)和\(N_2\),那么假设每个样本都是从其类别对应的高斯分布中取出来的,那么则可以进行如下推导:


那么就可以得到《统计学习方法》中第六章的逻辑回归对于两类概率的定义(解决了我的疑惑)

那么逻辑回归就是如何找到式子中的参数\(\omega\)和b。
假设\(f_{\omega,b}(x)=P(C_1 \mid x)\),可以将该模型用神经网络结点的形式来表达,如下图所示,可以更直观地理解。
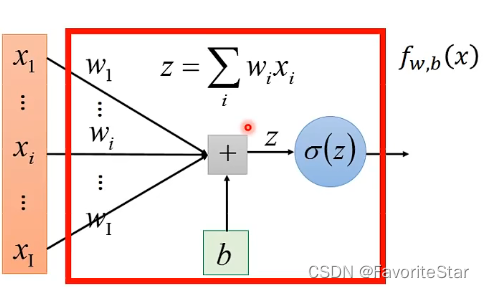
那么可以将样本出现的概率写成这样的表达式:

因此求解目标即为:
\]
但是由于不同类别的概率表达式不同,因此加上对数函数会很复杂,因此需要进行符号上的转换:

因此总概率函数就可以写成: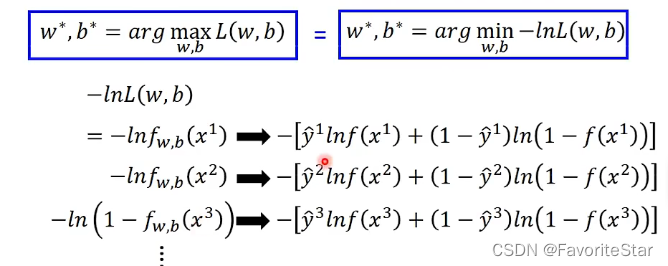
就可以代入具体的y来对表达式进行化简,或者写成求和的形式也很方便、即:
\]
实际上是交叉熵的形式(将y和f(x)都当成一个伯努利分布):
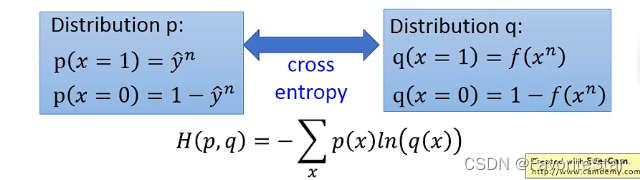
那么对比一下逻辑回归和线性回归:

下面就是求解参数了,同样可以采用梯度下降的方法:


因此我们可以得到逻辑回归和线性回归的参数更新公式是一样的:
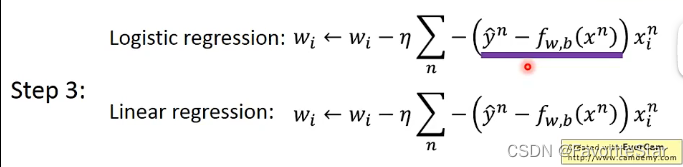
需要讨论的另一个问题时为什么逻辑回归的损失函数不可以采用和线性回归一样的平方误差呢?,来看下图;
可以看到逻辑回顾如果采用平方误差将会造成很大的偏差!!!,这会造成什么呢?来看下图:
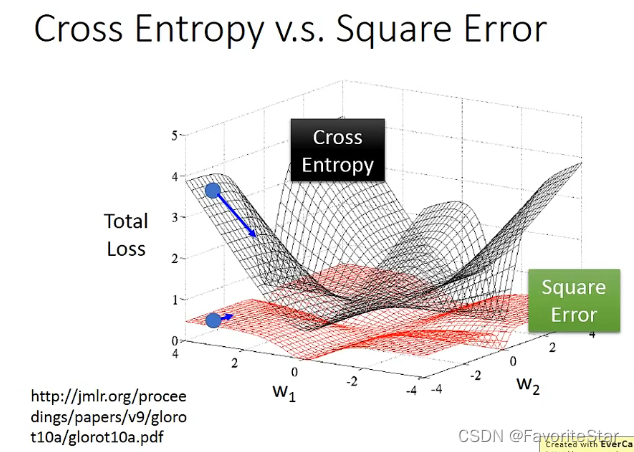
采用交叉熵的话,当距离目标处较远时仍然有较大的梯度因此更新参数的速度较快,而如果是平方误差那么其远处的损失也很平坦,这非常不利于梯度下降。
那么回到最开始的推导,我们在逻辑回归中是对\(P(C_1 \mid x)\)直接求\(\omega\)和b,在前面的推导中呢是先求两个高斯分布的参数然后再来求\(\omega\)和b,即:

那么重点就在于虽然共用同一个模型,但是求解出来的参数是不一样的,因此逻辑回归就直接求参数,而另外一个是假设在高斯分布的前提下来求解的。而实际上在很多文献中都说判别式模型比生成式模型更好。我理解是判别式模型因为没有假设,因此它的函数集合会更大,找到更好的函数的可能性也就更大。
对比一下生成式模型和判别式模型:
- 因为生成式模型具有一定的假设,因此在数据量比较少的时候,它有时候不会因为数据量的偏差而受到太大的影响,它会遵循自己内心的假设,而判别式模型就是完全靠数据来运作,因此在数据量少的时候有可能生成式模型是优于判别式模型的
逻辑回归的思想同样可以用到多分类问题上:
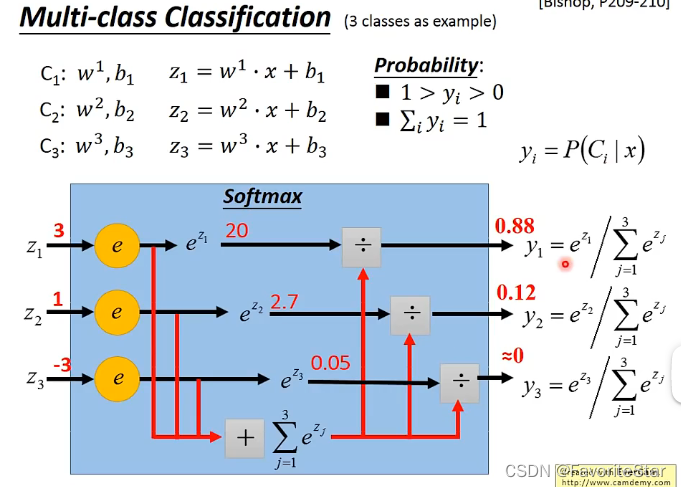
这部分同样的如果从高斯分布的模型推导最大概率可以推导出Sofrmax的模型,如果从最大熵(统计学习方法)的角度也可以推导出这个公式。
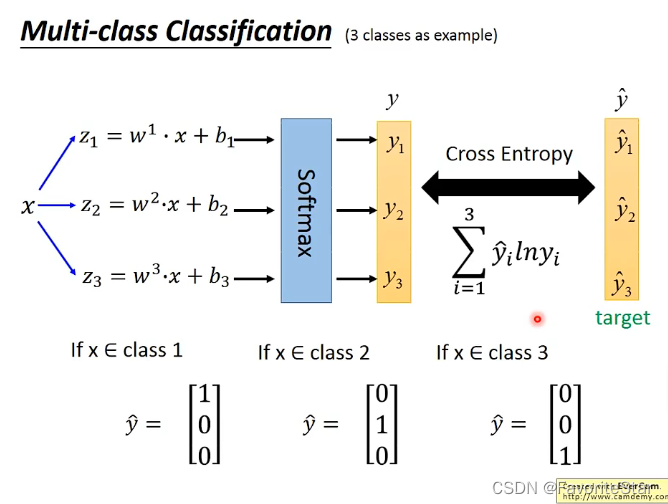
具体的流程如下图:(可以认为\(y\)和\(\hat{y}\)都是一个概率分布,那么两个概率分布的相似度就可以通过交叉熵来求解)。
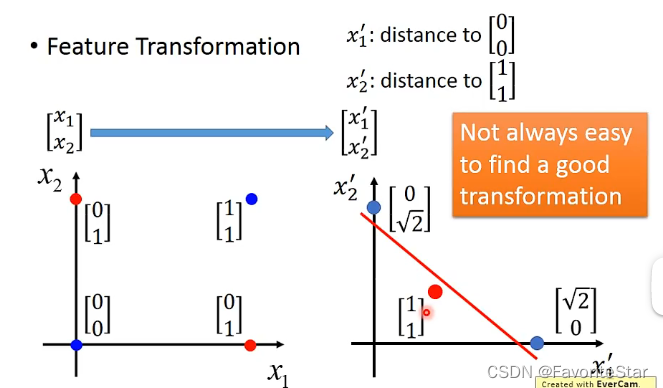
但是逻辑回归也有一定的局限性,例如下图这样的例子逻辑回归就无法用一条直线(逻辑回归的分界面是直线)将它们完全分开:

那么这其实有一种解决办法,就是将\(x_1\quad x_2\)的坐标进行转换(相当于是转换到新的坐标轴使得能够进行划分),例如我们用\(x_1`\)表示每个点到[0,0]的距离,用\(x_2`\)表示每个点到[1,1]的距离,那么就可以画出下图:
也就可将两类点划分了。但能否让机器来为我们选择最好的坐标转换方式呢?,有!用另外的逻辑回归来对坐标进行转换!,如下图:
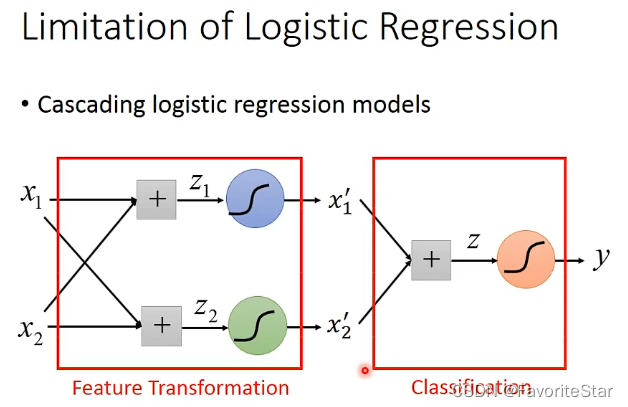
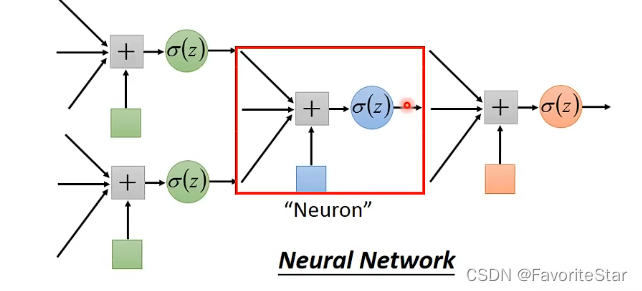
因此在无论在多复杂的模型中,都可以用这种方法,每个逻辑回归的输入可以是其他逻辑回归的输出,因此就引出了神经网络:
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【机器学习】李宏毅——从逻辑回归推导出神经网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 