介绍
感知器是创建深度神经网络的基本构建块,因此,我们首先应该使用感知器开始深度学习之旅,并学习如何使用 TensorFlow 实现它,并来解决不同的问题。以下是此关于感知器学习算法的博客涵盖的主题:
- 作为线性分类器的感知器
- 使用 TensorFlow 库实现感知器
- 使用单层感知器的 SONAR 数据分类
分类问题的类型
可以将可以使用神经网络解决的各种分类问题分为两大类:
- 线性可分问题
- 非线性可分问题
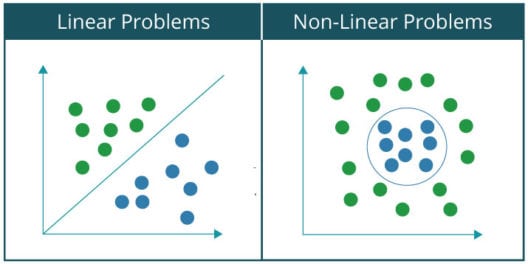
简单来说,如果您可以使用一条线将数据集分为两个类别,则称该问题是线性可分的。比如:在一群猫和狗中,将猫分离出来。而非线性可分问题的数据集包含两种以上的类别,所以需要非线性线将它们分成各自的类别。比如:对手写数字的分类,因为它包含了两种以上的类别,所以要使用非线性线将其分类。
我们可以查看以下绘制好的线性可分问题和非线性可分问题的图形,形象化地理解两者之间的区别:
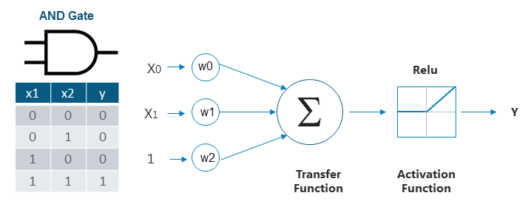
作为程序员,您应该熟悉“与门”,接下来将用它作为例子来解释基于感知器的线性分类器是如何工作的。
用感知器实现与门
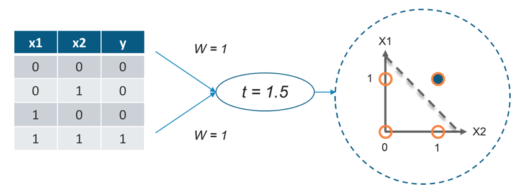
所谓“与门”,即当所有的输入都为1时,输出才为1,否则输出为0。可以看到与门的输出要么是1,要么是0。
因此,感知器可以通过分隔符或决策线,将与门的输入集分为以下两类:
- 第 1 类:输入集的输出为 0,位于决策线下方。
- 第 2 类:输入集的输出为 1,位于决策线上方。
下图显示了上述使用感知器对与门的输入进行分类的想法:
到现在为止,您已具备了理论知识,已经了解了线性感知器可将输入数据集分为两类。但是,它是如何对数据进行分类的呢?
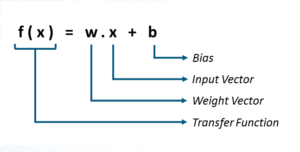
在数学上,可以将感知器表示为权重、输入和偏差(垂直偏移)的函数:
- 感知器接收到的每个输入都根据其对获得最终输出的贡献量进行了加权。
- 偏差允许我们移动决策线,以便它可以最好地将输入分为两类。
仅有理论知识并不足够,接下来我们用Python进行实战,从头开始使用感知器实现与门。
感知器学习算法:源代码实现与门
1.导入所有需要的库
我将从导入所有必需的库开始。我们只需要导入一个库,即 TensorFlow 即可:
#import required library
import tensorflow as tf2. 为输入和输出定义向量变量
现在,我将创建变量来存储我的感知器的输入、输出和偏差:
#input1, input2 and bias
train_in = [
[1., 1.,1],
[1., 0,1],
[0, 1.,1],
[0, 0,1]]
#output
train_out = [
[1.],
[0],
[0],
[0]]3.定义权重变量
现在,我需要定义权重变量并最初为其分配一些随机值。因为,我在这里有三个输入(输入 1、输入 2 和偏差),我需要为每个输入设置 3 个权重值。因此,我将为将使用随机值初始化的权重定义一个形状为 3×1 的张量变量:
#weight variable initialized with random values using random_normal()
w = tf.Variable(tf.random_normal([3, 1], seed=12))4.为输入和输出定义占位符
在 TensorFlow 中,您可以指定可以在运行时接受外部输入的占位符。因此,我将定义两个占位符——x 用于输入,y 用于输出。稍后,您将了解如何将输入提供给占位符。
#Placeholder for input and output
x = tf.placeholder(tf.float32,[None,3])
y = tf.placeholder(tf.float32,[None,1])5.计算输出和激活函数
如前所述,感知器接收到的输入首先乘以各自的权重,然后将所有这些加权输入相加。然后将该求和值馈送到激活以获得最终结果,如下图所示,后跟代码:
#calculate output
output = tf.nn.relu(tf.matmul(x, w))注意: 在这种情况下,我使用 relu作为我的激活函数。
6.计算误差
现在,我需要计算感知器输出的误差值和所需的输出。通常,这个误差被计算为均方误差,它只是感知器输出与期望输出之差的平方,如下所示:
#Mean Squared Loss or Error
loss = tf.reduce_sum(tf.square(output - y))7. 最小化错误
TensorFlow 提供了优化器,可以缓慢地改变每个变量(权重和偏差),以最大限度地减少连续迭代中的损失。最简单的优化器是梯度下降,我将在本例中使用它。
#Minimize loss using GradientDescentOptimizer with a learning rate of 0.01
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)8.初始化所有变量
调用tf.Variable时不会初始化变量。因此,我需要使用以下代码显式初始化 TensorFlow 程序中的所有变量:
#Initialize all the global variables
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)9. 迭代训练感知器
现在,我需要训练我们的感知器,即在连续迭代中更新权重和偏差值,以最小化错误或损失。
#Compute output and cost w.r.t to input vector
sess.run(train, {x:train_in,y:train_out})
cost = sess.run(loss,feed_dict={x:train_in,y:train_out})
print('Epoch--',i,'--loss--',cost)在上面的代码中,您可以观察我是如何使用 feed_dict 将 train_in(与门的输入集)和 train_out(与门的输出集)分别提供给占位符 x 和 y 来计算成本或错误的。
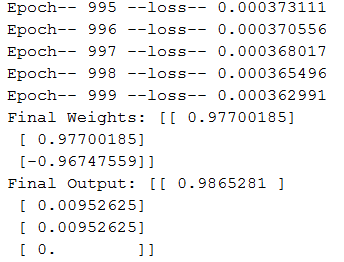
输出:
以下是我的感知器模型训练后得到的最终输出:
激活函数
如前所述,激活函数应用于感知器的输出,如下图所示:
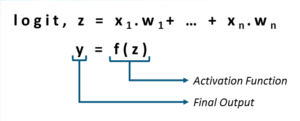
在前面的示例中,我向您展示了如何使用具有 relu 激活函数的线性感知器对与门的输入集进行线性分类。但是,如果您希望执行的分类本质上是非线性的怎么办?在这种情况下,您将使用一种非线性激活函数。下面显示了一些突出的非线性激活函数:
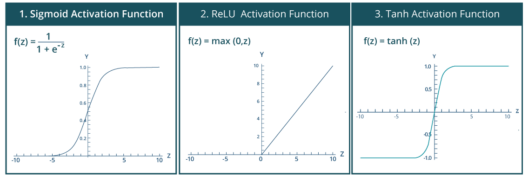
TensorFlow 库提供了用于应用激活函数的内置函数。下面列出了上述激活函数的内置函数:
-
tf.sigmoid(x, name=None)
- 按元素计算 x 的 sigmoid
- 对于元素 x,sigmoid 计算为: y = 1 / (1 + exp(-x))
-
tf.nn.relu(features, name=None)
- 计算修正线性为 – max(features, 0)
-
tf.tanh(x, name=None)
- 计算 x 元素的双曲正切值
到目前为止,您已经了解了感知器的工作原理以及如何使用 TensorFlow 对其进行编程。因此,是时候继续前进并应用我们对感知器的理解来解决一个有趣的 SONAR 数据分类用例了。
实战2:使用单层感知器的声呐数据分类
在此实例中,我们拥有一个声纳数据集,其中包含 208 种模式的数据,这些模式是通过在各种角度和各种条件下从金属圆柱体(水雷)和岩石上反射声纳信号获得的。
现在,我们的目标是建立一个模型,可以根据我们的数据集预测物体是水雷还是岩石。

现在,让我们看看我们的声呐数据集:

在这里,总体基本过程将与与门的基本过程相同,只有很少的差异。接下来向您展示使用单层感知器对声呐数据集执行线性分类的所有步骤,如下:
现在您已经清楚地了解了此实例中的所有步骤,让我们继续使用 TensorFlow 对模型进行编程:
1.导入所有需要的库
首先,我将从下面列出的所有必需库开始:
- matplotlib 库: 它提供了绘制图形的功能。
- tensorflow库:它提供了实现深度学习模型的功能。
- pandas、numpy 和 sklearn 库:它提供了预处理数据的功能。
2.读取并预处理数据集
在前面的示例中,我定义了输入和输出变量 wrt AND Gate 并明确为其分配了所需的值。
- 首先,我将使用 read_csv() 函数读取 CSV 文件(输入数据集)
- 然后,我将特征列(自变量)和输出列(因变量)分别分离为 X 和 y
- 输出列由字符串分类值组成,如“M”和“R”,分别表示 Rock 和 Mine。所以,我将它们标记为 0 和 1 wrt 'M' 和 'R'
- 在将这些分类值转换为整数标签后,我将使用下一步讨论的 one_hot_encode() 函数应用一个热编码。
#Read the sonar dataset
df = pd.read_csv("sonar.csv")
print(len(df.columns))
X = df[df.columns[0:60]].values
y = df[df.columns[60]]
#encode the dependent variable as it has two categorical values
encoder = LabelEncoder()
encoder.fit(y)
y = encoder.transform(y)
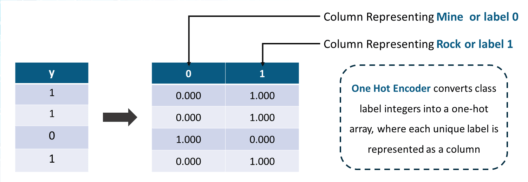
Y = one_hot_encode(y)3. 一个热编码器的功能
One Hot Encoder 根据列中存在的标签数量添加额外的列。在这种情况下,我有两个标签 0 和 1(用于 Rock 和 Mine)。因此,将添加两个额外的列,对应于每个分类值,如下图所示:
#function for applying one_hot_encoder
def one_hot_encode(labels):
n_labels = len(labels)
n_unique_labels = len(np.unique(labels))
one_hot_encode = np.zeros((n_labels,n_unique_labels))
one_hot_encode[np.arange(n_labels), labels] = 1
return one_hot_encode4.将数据集划分为Training和Test Subset
在处理任何深度学习项目时,您需要将数据集分为两部分,其中一部分用于训练深度学习模型,另一部分用于在训练后验证模型。因此,在这一步中,我还将数据集分为两个子集:
- 训练子集:用于训练模型
- 测试子集:用于验证我们训练好的模型
我将使用 sklearn 库中的 train_test_split() 函数来划分数据集:
#Divide the data in training and test subset
X,Y = shuffle(X,Y,random_state=1)
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.20, random_state=42)5.定义变量和占位符
在这里,我将为以下实体定义变量:
- 学习率:权重将被调整的量。
- 训练时期:迭代次数
- 成本历史:存储连续时期成本值的数组。
- Weight :存储权重值的张量变量
- bias: 存储偏置值的张量变量
除了变量,我还需要可以接受输入的占位符。因此,我将为我的输入创建占位符,并在稍后将数据集提供给它。最后,我将调用 global_variable_initializer() 来初始化所有变量。
#define all the variables to work with the tensors
learning_rate = 0.1
training_epochs = 1000
cost_history = np.empty(shape=[1],dtype=float)
n_dim = X.shape[1]
n_class = 2
x = tf.placeholder(tf.float32,[None,n_dim])
W = tf.Variable(tf.zeros([n_dim,n_class]))
b = tf.Variable(tf.zeros([n_class])6.计算成本或错误
与 AND 门实施类似,我将计算我们的模型产生的成本或错误。在这种情况下,我将使用交叉熵来计算 误差,而不是均方误差 。
y_ = tf.placeholder(tf.float32,[None,n_class])
y = tf.nn.softmax(tf.matmul(x, W)+ b)
cost_function = tf.reduce_mean(-tf.reduce_sum((y_ * tf.log(y)),reduction_indices=[1]))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function)7. 在连续的时代训练感知器模型
现在,我将在连续的时期训练我的模型。在每个 epoch 中,都会计算成本,然后根据此成本,优化器会修改权重和偏差变量以最小化误差。
#Minimizing the cost for each epoch
for epoch in range(training_epochs):
sess.run(training_step,feed_dict={x:train_x,y_:train_y})
cost = sess.run(cost_function,feed_dict={x: train_x,y_: train_y})
cost_history = np.append(cost_history,cost)
print('epoch : ', epoch, ' - ', 'cost: ', cost)8. 基于测试子集的模型验证
如前所述, 训练模型的准确性是根据测试子集计算的。因此,首先,我会将测试子集提供给我的模型并获得输出(标签)。然后,我将从模型获得的输出与实际或期望输出的输出进行比较,最后,将计算准确度,即正确预测占测试子集总预测的百分比。
#Run the trained model on test subset
pred_y = sess.run(y, feed_dict={x: test_x})
#calculate the correct predictions
correct_prediction = tf.equal(tf.argmax(pred_y,1), tf.argmax(test_y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy: ",sess.run(accuracy))输出:
以下是训练完成后您将获得的输出:
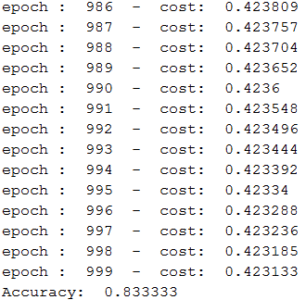
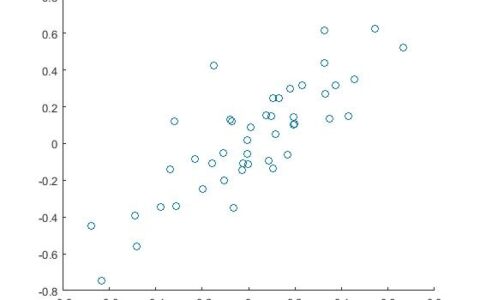
如您所见,我们得到了83.34%的准确率,这已经足够下降了。现在,让我们通过绘制成本与时期数的关系图来观察连续时期的成本或错误是如何减少的:
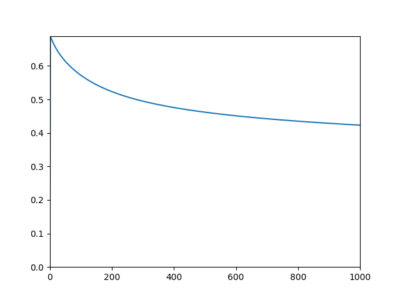
使用单层感知器进行声纳数据分类的完整代码
#import the required libraries
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
#define the one hot encode function
def one_hot_encode(labels):
n_labels = len(labels)
n_unique_labels = len(np.unique(labels))
one_hot_encode = np.zeros((n_labels,n_unique_labels))
one_hot_encode[np.arange(n_labels), labels] = 1
return one_hot_encode
#Read the sonar dataset
df = pd.read_csv("sonar.csv")
print(len(df.columns))
X = df[df.columns[0:60]].values
y=df[df.columns[60]]
#encode the dependent variable containing categorical values
encoder = LabelEncoder()
encoder.fit(y)
y = encoder.transform(y)
Y = one_hot_encode(y)
#Transform the data in training and testing
X,Y = shuffle(X,Y,random_state=1)
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.20, random_state=42)
#define and initialize the variables to work with the tensors
learning_rate = 0.1
training_epochs = 1000
#Array to store cost obtained in each epoch
cost_history = np.empty(shape=[1],dtype=float)
n_dim = X.shape[1]
n_class = 2
x = tf.placeholder(tf.float32,[None,n_dim])
W = tf.Variable(tf.zeros([n_dim,n_class]))
b = tf.Variable(tf.zeros([n_class]))
#initialize all variables.
init = tf.global_variables_initializer()
#define the cost function
y_ = tf.placeholder(tf.float32,[None,n_class])
y = tf.nn.softmax(tf.matmul(x, W)+ b)
cost_function = tf.reduce_mean(-tf.reduce_sum((y_ * tf.log(y)),reduction_indices=[1]))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function)
#initialize the session
sess = tf.Session()
sess.run(init)
mse_history = []
#calculate the cost for each epoch
for epoch in range(training_epochs):
sess.run(training_step,feed_dict={x:train_x,y_:train_y})
cost = sess.run(cost_function,feed_dict={x: train_x,y_: train_y})
cost_history = np.append(cost_history,cost)
print('epoch : ', epoch, ' - ', 'cost: ', cost)
pred_y = sess.run(y, feed_dict={x: test_x})
#Calculate Accuracy
correct_prediction = tf.equal(tf.argmax(pred_y,1), tf.argmax(test_y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy: ",sess.run(accuracy))
plt.plot(range(len(cost_history)),cost_history)
plt.axis([0,training_epochs,0,np.max(cost_history)])
plt.show()结论
在这篇关于感知器学习算法的博客中,您了解了什么是感知器以及如何使用 TensorFlow 库实现它。您还了解了如何将感知器用作线性分类器,并且我演示了如何利用这一事实来使用感知器实现与门。最后,我向前迈出了一步,应用感知器解决了一个实时用例,在该用例中,我对 SONAR 数据集进行了分类,以检测Rock和Mine之间的差异。现在,在下一篇博客中,我将讨论单层感知器的局限性以及如何构建多层感知器或神经网络来处理更复杂的问题。在那里,您还将了解如何从头开始使用 TensorFlow 构建多层神经网络。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习:感知器学习算法(附源码) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫