一、TensorFlow的主要依赖包
1.Protocol Buffer
Protocol Buffer负责将结构化的数据序列化,并从序列化之后的数据流中还原出原来的结构化数据。TensorFlow中的数据基本都是通过Protocol Buffer来组织的。
结构化数据:
name: 张三 id: 12345 email: zhangsan@abc.com
Protocol Buffer格式的序列化数据:
message user{ optional string name = 1; required int32 id = 2; repeated string email = 3; }
Protocol Buffer数据格式一般保存在.proto文件中。
- 与XML、Json等其他工具比较:
序列化为二进制流,而不是字符串
XML、Json格式信息包含在数据流中,Protocol Buffer需要先定义数据的格式
Protocol Buffer数据流比XML小3-10倍,解析时间快20-100倍
2.Bazel
Bazel是从Google开源的自动化构建工具,相比传统的makefile,Ant或者Maven,Bazel在速度、可伸缩性、灵活性以及对不同程序语言和平台的支持上都要更加出色。
项目空间(workspace)是Bazel的一个基本概念。一个项目空间可以简单地理解为一个文件夹,在这个文件夹中包含了编译一个软件所需要的源代码以及输出编译结果的软连接(symbolic link)地址。项目空间所对应的的文件夹是这个项目的根目录:
- WORKSPACE文件:定义了对外部资源的依赖关系
- BUILD文件:找到需要编译的目标
在编译出来的结果中,bazel-bin目录下存放了编译产生的二进制文件以及运行该二进制文件所需要的所有依赖关系。
二、TensorFlow安装
1、安装Anaconda
下载安装包:https://www.anaconda.com/distribution/

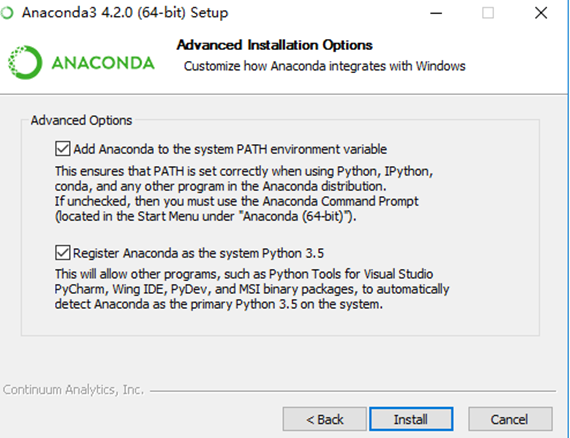
按照正常步骤安装即可。
Att:以下两个选项都选上,将安装路径写入环境变量
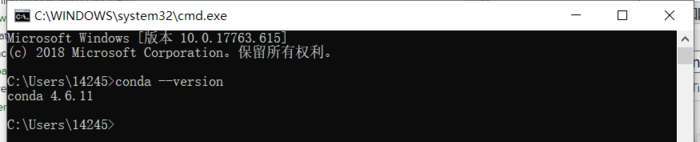
检测anconda环境是否安装成功:Win+R cmd 进入Windows命令窗口,输入命令:
conda --version
输出版本信息则安装成功。
2、安装TensorFlow
(1)建立tensorflow anaconda虚拟环境
命令窗口下输入:
conda create --name tensorFlow python=3.7 anaconda
- conda create:建立虚拟环境
- --name tensorFlow:虚拟环境的名称是TensorFlow
- python=3.7:Python版本是3.7
(2)启动虚拟环境
命令窗口下输入:
activate tensorFlow
(3)安装TensorFlow
命令窗口下输入:
pip install tensorflow
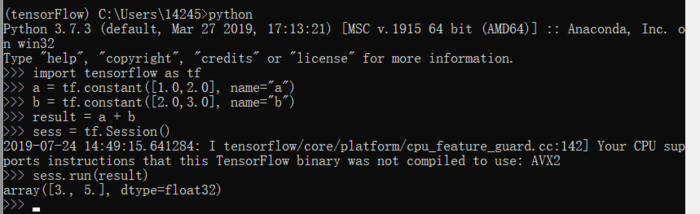
3、验证TensorFlow是否安装成功(测试样例)
import tensorflow as tf # 加载tensorFlow a = tf.constant([1.0,2.0], name="a") b = tf.constant([2.0,3.0], name="b") # 定义两个向量a和b,被定义为常量(tf.constant) result = a + b # 将两个向量加起来 sess = tf.Session() sess.run(result) # 要输出相加的结果,不能简单地输出result,而需要先生成一个会话(session),并通过这个会话来计算结果
一般来说,只要第一句的import不报错,就说明TensorFlow安装成功了。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:《TensorFlow实战Google深度学习框架》笔记——TensorFlow环境搭建 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 