NVIDIA TensorRT高性能深度学习推理
NVIDIA TensorRT™ 是用于高性能深度学习推理的 SDK。此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。
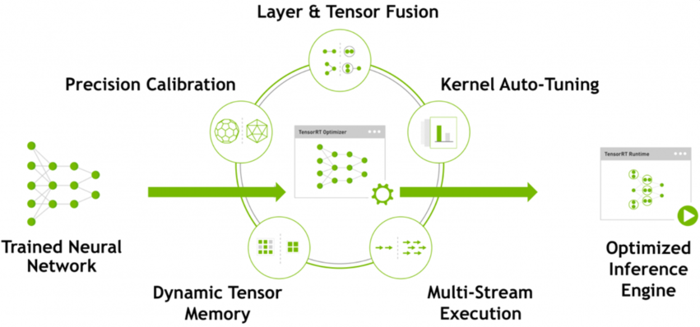

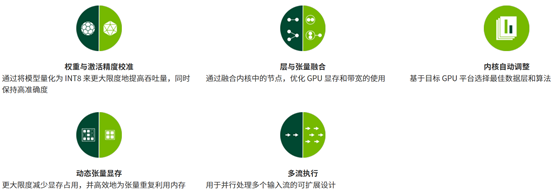
在推理过程中,基于 TensorRT 的应用程序的执行速度可比 CPU 平台的速度快 40 倍。借助 TensorRT,您可以优化在所有主要框架中训练的神经网络模型,精确校正低精度,并最终将模型部署到超大规模数据中心、嵌入式或汽车产品平台中。
TensorRT 以 NVIDIA 的并行编程模型 CUDA 为基础构建而成,可帮助您利用 CUDA-X 中的库、开发工具和技术,针对人工智能、自主机器、高性能计算和图形优化所有深度学习框架中的推理。
TensorRT 针对多种深度学习推理应用的生产部署提供 INT8 和 FP16 优化,例如视频流式传输、语音识别、推荐和自然语言处理。推理精度降低后可显著减少应用延迟,这恰巧满足了许多实时服务、自动和嵌入式应用的要求。
可以从每个深度学习框架中将已训练模型导入到 TensorRT。应用优化后,TensorRT 选择平台特定的内核,在数据中心、Jetson 嵌入式平台以及 NVIDIA DRIVE 自动驾驶平台上更大限度提升 Tesla GPU 的性能。
借助 TensorRT,开发者可专注于创建新颖的 AI 支持应用,无需费力调节性能来部署推理工作。
TensorRT 优化与性能

与所有主要框架集成
NVIDIA 与深度学习框架开发者紧密合作,使用 TensorRT 在 AI 平台上实现优化的推理性能。如果您的训练模型采用 ONNX 格式或其他热门框架(例如 TensorFlow 和 MATLAB),您可以通过一些简单的方法将模型导入到 TensorRT 以进行推理。下面介绍了一些集成,其中包含了新手入门信息。
TensorRT 和 TensorFlow 已紧密集成,因此您可以同时尽享 TensorFlow 的灵活性和 TensorRT 的超强优化性能。
MATLAB 已通过 GPU 编码器实现与 TensorRT 的集成,这能协助工程师和科学家在使用 MATLAB 时为 Jetson、DRIVE 和 Tesla 平台自动生成高性能推理引擎。
TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地从框架(例如 Caffe 2、Chainer、Microsoft
Cognitive Toolkit、MxNet 和 PyTorch)中将 ONNX 模型导入到 TensorRT。
TensorRT 还与 ONNX Runtime 集成,助您以 ONNX 格式轻松实现机器学习模型的高性能推理。
如果您在专有或自定义框架中执行深度学习训练,请使用 TensorRT C++
API 来导入和加速模型。

“通过在 V100 上使用
Tensor 核心、新近优化的 CUDA 库以及 TF-TRT 后端,我们能将原本就很快的深度学习 (DL) 网络速度再提升 4 倍”
公布 TensorRT
7.1:新功能
TensorRT 7.1 针对 NVIDIA A100 GPU 进行了优化并加入了新优化,现可使用 INT8 精度加速 BERT 推理,实现高达 V100 GPU 六倍的性能。NVIDIA 开发者计划成员可于 2020 年夏季下载 TensorRT 7.1。
TensorRT 7.0(当前版本)包含:
- 新编译器,可对语音和异常检测中的常用时间递归神经网络进行加速
- 对 20 多种新 ONNX 操作的支持,这些操作可对 BERT、TacoTron 2 和 WaveRNN 等关键的语音模型进行加速
- 对动态形状的扩展支持,可实现关键的会话式 AI 模型
- 新版插件、解析器
- BERT、Mask-RCNN、Faster-RCNN、NCF 和 OpenNMT 的新示例
其他资源
概览
- NGC 中的 TensorRT 容器、模型和脚本
-
运行 TensorRT 的“Hello
World”(示例代码) -
将 ONNX 用作输入,运行 TensorRT 的“Hello
World”(示例代码) - 使用自定义校准以 INT8 精度执行推理(示例代码)
- TensorRT 简介(网络研讨会)
-
使用 TensorRT 执行
8 位推理(网络研讨会)
会话式 AI
-
使用 TensorRT 通过
BERT 实现实时自然语言理解(博客) - 使用 TensorRT 进行自动语音识别 (Notebook)
- 使用 TensorRT 对实时文字转语音进行加速(博客)
-
使用 BERT 实现
NLU (Notebook) (Notebook) - 实时文字转语音(示例)
- 基于序列到序列 (seq2seq) 模型的神经网络机器翻译 (NMT)(示例代码)
- 逐层构建 RNN 网络(示例代码)
开始实操训练
NVIDIA 深度学习学院 (DLI) 为 AI 和加速计算领域的开发者、数据科学家和研究人员提供实操训练。立即参加关于使用 TensorRT 优化和部署 TensorFlow 模型以及“使用 TensorRT 部署智能视频分析”的自定进度选修课程,获取 TensorRT 实操经验。
适用范围
NVIDIA 开发者计划会员可访问 TensorRT 产品页面,免费使用 TensorRT 进行用于开发和部署。最新版本的插件、解析器和示例也以开源形式提供,可从 TensorRT GitHub 资源库获取。
开发者还可以通过 NGC 容器注册表中的 TensorRT 容器获得 TensorRT。
TensorRT 已纳入:
- 用于在计算机视觉和智能视频分析
(IVA) 应用中进行实时流分析的 NVIDIA Deepstream SDK - 适用于 NVIDIA DRIVE PX2 自动驾驶平台的 NVIDIA DriveInstall
- 适用于 Jetson TX1、TX2
嵌入式平台的 NVIDIA Jetpack
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:NVIDIA TensorRT高性能深度学习推理 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 