NVIDIA深度学习Tensor Core性能解析(下)
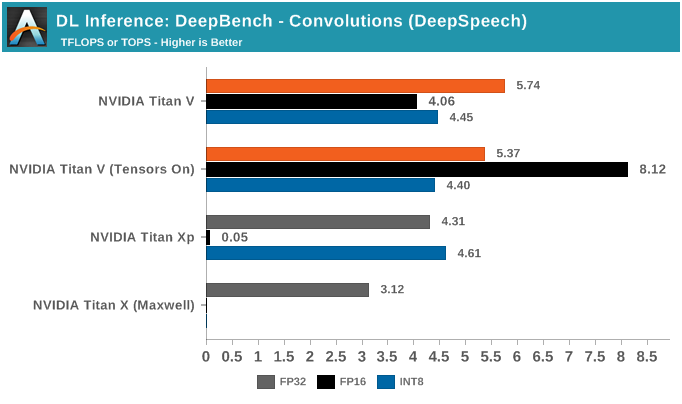


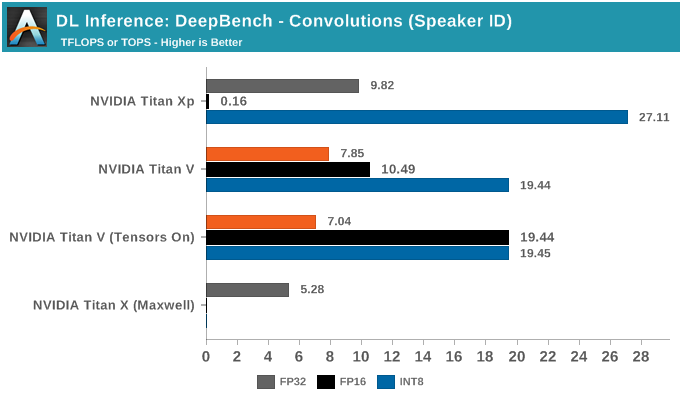
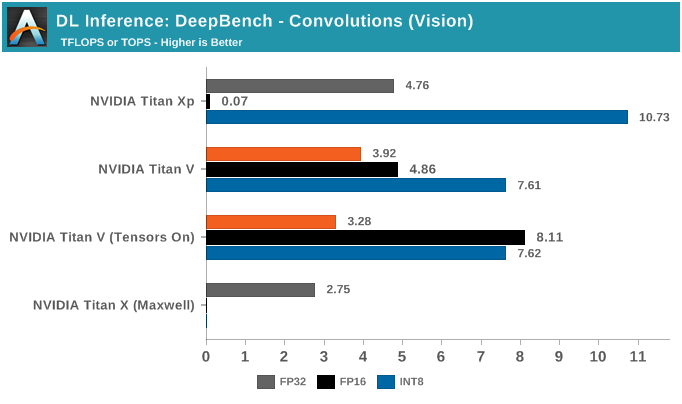
DeepBench推理测试之RNN和Sparse GEMM
DeepBench的最后一项推理测试是RNN和Sparse GEMM,虽然测试中可以选择FP16,但实际上它们都只支持FP32运算。
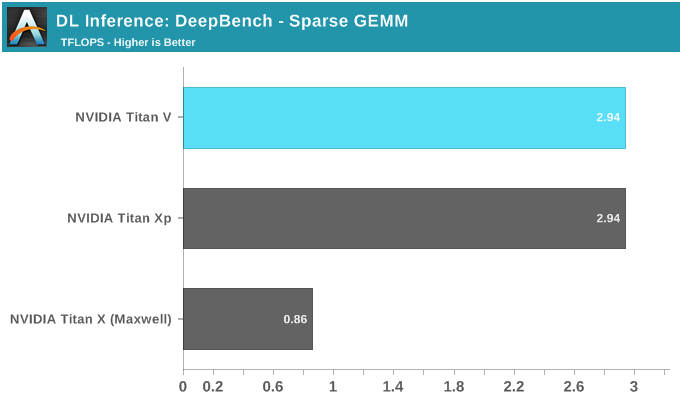
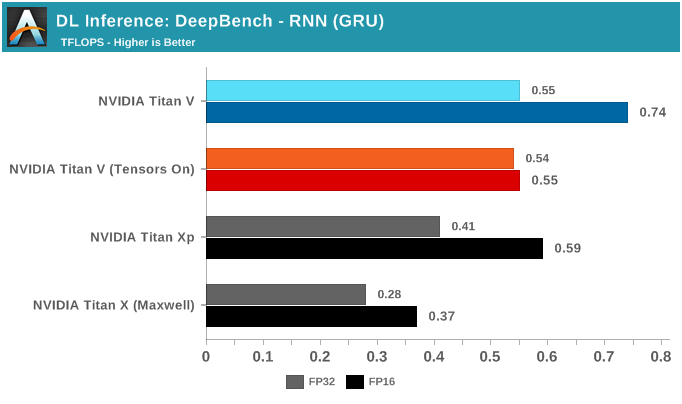
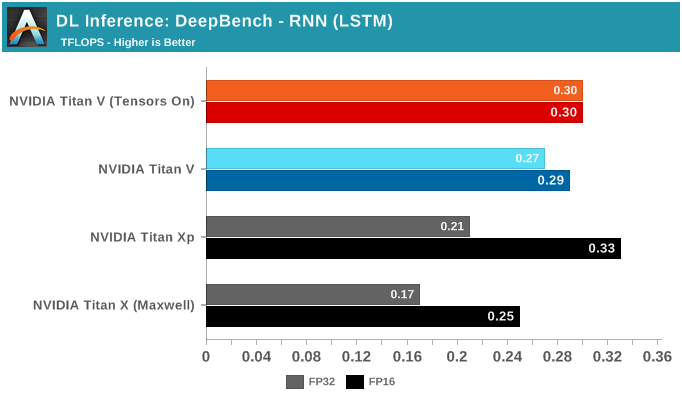

虽然RNN可能会有加速,但DeepBench和NVIDIA目前仅支持单精度RNN推理。
NVIDIA Caffe2测试之ResNet50和ImageNet
虽然内核和深度学习数学运算可能很有用,但实际应用中是使用真实数据集进行训练的。使用标准的ILSVRC 2012图片集,在ImageNet上通过ResNet50模型来训练和推断,可以展示更具参考的性能数据。
虽然FP16和Tensor Core有单独的开关,但Titan V在启用和禁用Tensor Core的情况下运行FP16的性能是完全一样的。


只看原始吞吐量性能的话,Titan V在所有批尺寸下都处于领先地位。凭借Tensor Core,Titan V可处理的批尺寸达到甚至超过了64,而其他显卡即便有12 GB显存也无法与之相比。
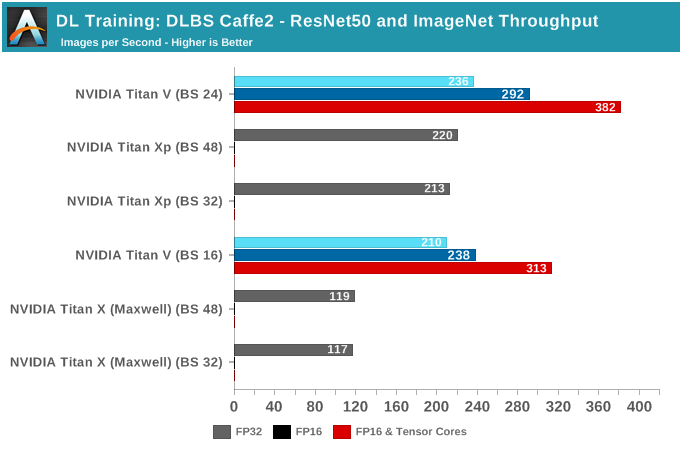
不过只看原始吞吐量性能的问题在于,深度学习的实际性能从来没有这么简单。首先,许多模型可能会牺牲精度和训练时间以换取针对吞吐量的优化,如果模型需要较长的时间来收敛,那么每秒训练的峰值性能就没有参考意义了。
这些问题与使用FP16存储和Tensor Core的Volta尤为相关,如果在实际应用中使用了有损缩放或单精度批量归一化,这在吞吐量性能中都是无法体现的。
HPE DLBS Caffe2测试之ResNet50和ImageNet
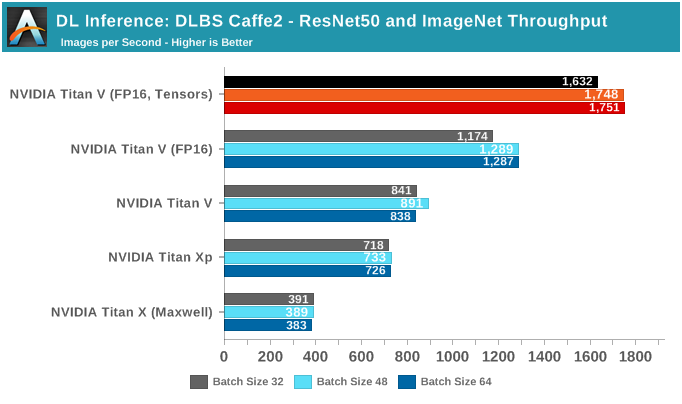
接下来,我们看一下深度学习指南中的HPE DLBS。与通常的深度学习测试不同,HPE DLBS基本上只输出吞吐量和时间指标。
HPE DLBS的一大特色是支持NVIDIA Caffe2测试使用的数据集,我们同样可以在ImageNet上使用ResNet50模型来训练和推断。但是由于二者的模型和实现不同,测出的吞吐量性能无法与NVIDIA Caffe2直接进行比较。

在测试中,Titan V无法支持某些特定的批尺寸,但总体趋势和之前的测试基本相同,FP16和Tensor Core提供了更高的吞吐量。不过遗憾的是,HPE DLBS Caffe2测试似乎不支持INT8推理。
HPE DLBS TensorRT测试之ResNet50和ImageNet
HPE DLBS的另一大特色是支持TensorRT(NVIDIA推理优化引擎)的基准测试功能, NVIDIA近年来已将TensorRT与新的深度学习功能(如INT8/DP4A和Tensor Core的16位累加器模式)相结合以进行推理。
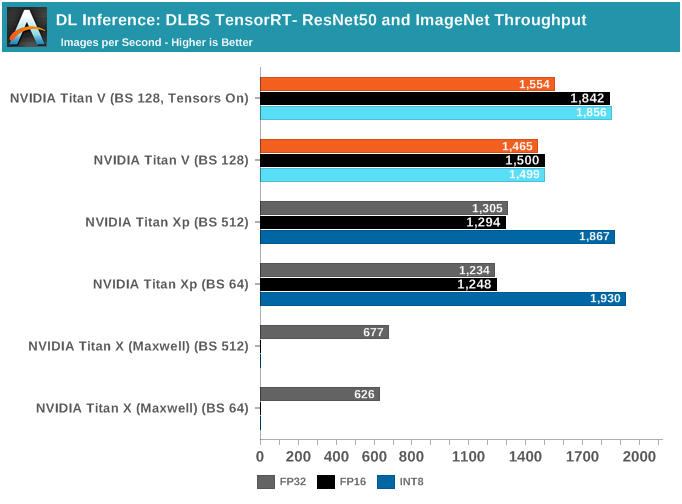
使用Caffe模型,TensorRT可以根据需要调整模型,以便在给定的精度下进行推理。我们在Titan X(Maxwell)和Titan Xp(Pascal)上运行了64、512和1024的批尺寸,在Titan V运行了128、256和640的批尺寸。
Titan Xp的高INT8性能在一定程度上印证了GEMM/卷积性能,这两个工作负载似乎都在使用DP4A。不过雷锋网并未了解到DP4A如何在Titan V上实现,只知道它由Volta指令集提供支持,且Volta确实拥有独立的INT32单元。
DAWNBench测试之CIFAR10图像分类
就实际应用的性能而言,深度学习训练更适合用时间/准确性和成本来描述,而这两点分别对应DAWNBench的两项子测试。对于使用CIFAR10的图像分类来说,这两项子测试为:
时间/准确性:训练CIFAR10数据集的图像分类模型,报告训练所需的时间,且要求测试集准确性至少为94%。
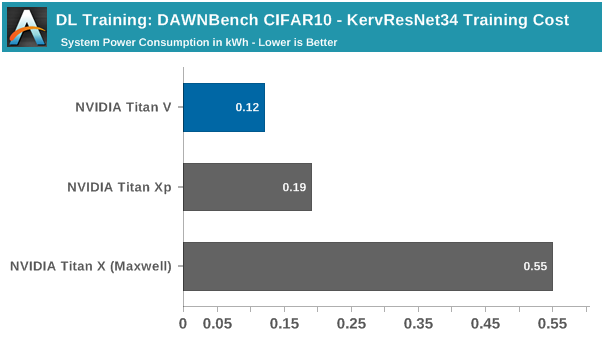
成本:在公共云基础架构上,计算达到94%或更高的测试集准确性所需的总时间,将所花费的时间(以小时为单位)乘以每小时实例的成本,以获得训练模型的总成本。
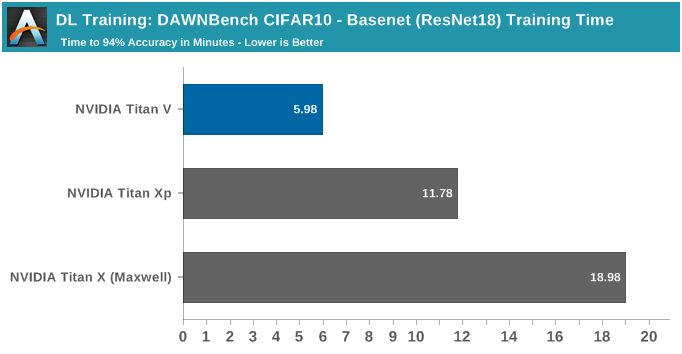
测试选用PyTorch的CIFAR10训练实现中最快的两个,其中一个基于ResNet34,是为了在NVIDIA GeForce GTX 1080 Ti上运行,而第二个基于ResNet18,是为了在单个Tesla V100上运行。这些都是DAWNBench中最近的热门测试,可以认为它们是相当符合现代的项目,同时CIFAR10也不是一个非常密集的数据集。
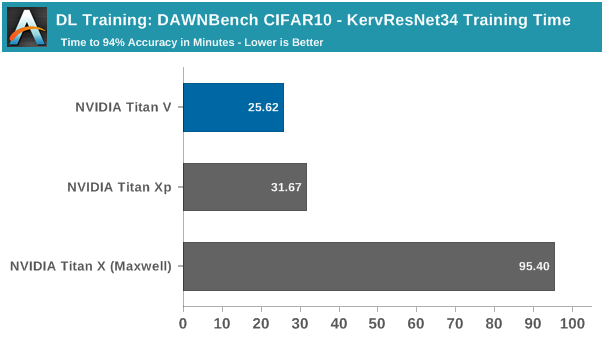
CIFAR10的小型图像数据集运行良好,第一个训练实现是在单个GTX 1080 Ti上运行,需要35分37秒才能训练到94%的准确性,而在第二个训练实现中,Titan V只用了5分41秒就完成了94%的目标。
顺带一提,虽然Titan V在第一个训练实现中不会使用Tensor Core,但凭借相对于Pascal的一般改进,Titan V在这个测试中的速度依然比Titan Xp快20%左右,同时系统峰值功耗也下降了大约80W。
结语
Tensor Core是Titan V的重要组成部分,本文的目的也是尽可能的了解Volta,所以测试着重考察了Tensor Core加速。
本次测试还有许多没有涉及到的各种其他测试和套件,它们普遍在设计上有太多欠缺。事实证明,无论从整体还是局部来看,都不可能找到一个负载贴合当下实际、提供端到端指标、覆盖多个机器学习域、支持Tensor Core和混合精度,最重要的是易于非专业开发者使用的深度学习套件。
即便是参考价值较大的DAWNBench,设计本意也并非提供一个通用的基准,而是为方便研究者和开发者创建他们自己的实现。DAWNBench的深度学习框架仍然需要修改以作为一款有效的基准测试使用,但重新配置一个与Volta兼容的混合精度模型就不是一件可以轻松完成的事情。

这实际上与Titan V自身相关,Tensor Core和混合精度需要专门的开发来适配支持,只能在特定情况下明显提升性能。且即便用户的代码和数据集可以与Tensor Core良好的匹配,到头来神经网络处理也会受到来自传统ALU的限制。
而对于主流消费者群体来说,Tensor Core的发展对他们意味着什么?最新的Turing架构证明,Tensor Core在游戏卡领域同样可以有所应用。雷锋网(公众号:雷锋网)曾在NVIDIA RTX 2080Ti/2080/2070发布时报道过,RTX光线追踪技术就是使用Tensor Core对图像进行降噪以弥补光线数量的限制。NVIDIA唯一需要考虑的问题是,这些玩家是否乐意为这些Tensor Core买单。


对于任何考虑购买Titan V以满足计算需求的人来说,投资Titan V就意味着投资混合精度深度学习模型和基于WMMA的HPC GEMM加速。在cuDNN、cuBLAS以及早期DP4A和FP16*2混合精度计算的背景下,Tensor Core是试图用可编程硬件来实现深度学习加速的一种自然进化。
可以肯定的是,Titan V绝对代表了NVIDIA对未来GPGPU的愿望。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:NVIDIA深度学习Tensor Core性能解析(下) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 