
在FNN(DNN)的前向传播,反向梯度推导以及代码验证中,我们不仅总结了FNN(DNN)这种神经网络结构的前向传播和反向梯度求导公式,还通过tensorflow的自动求微分工具验证了其准确性。在本篇章,我们将专门针对CNN这种网络结构进行前向传播介绍和反向梯度推导。更多相关内容请见《神经网络的梯度推导与代码验证》系列介绍。
注意:
- 本系列的关注点主要在反向梯度推导以及代码上的验证,涉及到的前向传播相对而言不会做太详细的介绍。
-
反向梯度求导涉及到矩阵微分和求导的相关知识,请见《神经网络的梯度推导与代码验证》之数学基础篇:矩阵微分与求导,内含手把手教学级的内容。
目录
-
3.1 CNN的前向传播
- 3.1.1 CNN输入层前向传播到卷积层
- 3.1.2 隐藏层前向传播到卷积层
- 3.1.3 隐藏层前向传播到池化层
- 3.1.4 隐藏层前向传播到全连接层
- 3.1.5 CNN前向传播算法小结
-
3.2 CNN的反向梯度推导
- 3.2.1 已知池化层的$\delta^{l}$,推导前一隐藏层的$\delta^{l-1}$
- 3.2.2 已知卷积层的$\delta^{l}$,推导前一隐藏层的$\delta^{l-1}$
- 3.2.3 已知卷积层的$\delta^{l}$,推导该层的$W$,$b$的梯度
- 3.2.4 CNN反向梯度求导总结
- 参考资料
提醒:
- 后续会反复出现$\boldsymbol{\delta}^{l}$这个(类)符号,它的定义为$\boldsymbol{\delta}^{l} = \frac{\partial l}{\partial\boldsymbol{z}^{\boldsymbol{l}}}$,即loss $l$对$\boldsymbol{z}^{\boldsymbol{l}}$的导数
- 其中$\boldsymbol{z}^{\boldsymbol{l}}$表示第$l$层(DNN,CNN,RNN或其他例如max pooling层等)未经过激活函数的输出。
- $\boldsymbol{a}^{\boldsymbol{l}}$则表示$\boldsymbol{z}^{\boldsymbol{l}}$经过激活函数后的输出。
这些符号会贯穿整个系列,还请留意。
3.1 CNN的前向传播
CNN大致的结构如下,包括输出层,若干的卷积层+ReLU激活函数,若干的池化层,DNN全连接层,以及最后的用Softmax激活函数的输出层。这里我们用一个彩色的汽车样本的图像识别再从感官上回顾下CNN的结构。图中的CONV即为卷积层,POOL即为池化层,而FC即为FNN全连接层,包括了Softmax激活函数。
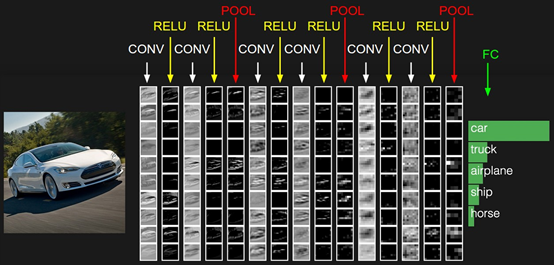

从上图可以看出,要理顺CNN的前向传播算法,重点是输入层的前向传播,卷积层的前向传播以及池化层的前向传播。而FNN全连接层和用Softmax激活函数的输出层的前向和反向传播在讲FNN时已经介绍过了。
3.1.1 CNN输入层前向传播到卷积层
输入层的前向传播是CNN前向传播算法的第一步。一般输入层的下一层都是卷积层,因此我们标题是输入层前向传播到卷积层。
我们这里还是以图像识别为例。
先考虑最简单的,样本都是二维的黑白图片。这样输入层$\boldsymbol{X}$就是一个矩阵,矩阵的值等于图片的各个像素位置的值。这时和卷积层相连的卷积核$\boldsymbol{W}$就也是矩阵。
如果样本都是有RGB的彩色图片,这样输入 就是3个矩阵,即分别对应R,G和B的矩阵,或者说是一个张量。这时和卷积层相连的卷积核 就也是张量,对应的最后一维的维度为3。即每个卷积核都是3个子矩阵组成。
同样的方法,对于3D的彩色图片之类的样本,我们的输入$\boldsymbol{X}$可以是4维,5维的张量,那么对应的卷积核$\boldsymbol{W}$也是个高维的张量。不管维度多高,对于我们的输入,前向传播的过程可以表示为:
$\boldsymbol{a}^{2} = \sigma\left( \boldsymbol{z}^{2} \right) = \sigma\left( {\boldsymbol{a}^{1}*\boldsymbol{W}^{2} + \boldsymbol{b}^{2}} \right)$
其中,上标代表层数,星号代表卷积,而$\boldsymbol{b}$代表我们的bias,$\sigma$为激活函数,这里一般都是ReLU。和DNN的前向传播比较一下,其实形式非常的像,只是我们这儿是张量的卷积,而不是矩阵的乘法。同时由于$\boldsymbol{W}$是张量,那么同样的位置,$\boldsymbol{W}$参数的个数就比DNN多很多了。
为了简化我们的描述,本文后面如果没有特殊说明,我们都默认输入是3维的张量,即用RBG可以表示的彩色图片。
这里需要我们自己定义的CNN模型参数有:
1)一般我们的卷积核不止一个,比如有K个,那么我们输入层的输出,或者说第二层卷积层的对应的输入就K个。
2)卷积核中每个子矩阵的的大小,一般我们都用子矩阵为方阵的卷积核,比如FxF的子矩阵。
3) 填充padding(以下简称P),我们卷积的时候,为了可以更好的识别边缘,一般都会在输入矩阵在周围加上若干圈的0再进行卷积,加多少圈则P为多少。
4) 步幅stride(以下简称S),即在卷积过程中每次移动的像素距离大小。
3.1.2 隐藏层前向传播到卷积层
现在我们再来看隐藏层前向传播到卷积层时的前向传播算法。
假设隐藏层的输出是M个矩阵对应的三维张量,则输出到卷积层的卷积核也是M个子矩阵对应的三维张量。这时表达式和输入层的很像:
$\boldsymbol{a}^{l} = \sigma\left( \boldsymbol{z}^{l} \right) = \sigma\left( {\boldsymbol{a}^{l - 1}*\boldsymbol{W}^{l} + \boldsymbol{b}^{l}} \right)$
也可以写成M个子矩阵子矩阵卷积后对应位置相加的形式,即:
$\boldsymbol{a}^{l} = \sigma\left( \boldsymbol{z}^{l} \right) = \sigma\left( {\sum\limits_{k = 1}^{M}\boldsymbol{z}_{k}^{l}} \right) = \sigma\left( {\sum\limits_{k - 1}^{M}{\boldsymbol{a}_{\boldsymbol{k}}^{\boldsymbol{l} - 1}*\boldsymbol{W}_{k}^{l} + \boldsymbol{b}^{l}}} \right)$
和上一节3.1.1唯一的区别仅仅在于,这里的输入是隐藏层来的,而不是我们输入的原始图片样本形成的矩阵。
需要我们定义的CNN模型参数也和上一节一样,这里我们需要定义卷积核的个数K,卷积核子矩阵的维度F,填充大小P以及步幅S。
3.1.3 隐藏层前向传播到池化层
池化层的处理逻辑是比较简单的,我们的目的就是对输入的矩阵进行缩小概括。比如输入的若干矩阵是N x N维的,而我们的池化大小是k x k的区域,则输出的矩阵都是 x 维的。
这里需要需要我们定义的CNN模型参数是:
1) 池化区域的大小k
2) 池化的标准,一般是MAX或者Average。
3.1.4 隐藏层前向传播到全连接层
由于全连接层就是普通的DNN模型结构,因此我们可以直接使用DNN的前向传播算法逻辑,即:
$\boldsymbol{a}^{l} = \sigma\left( \boldsymbol{z}^{l} \right) = \sigma\left( {\boldsymbol{W}^{\boldsymbol{l}}\boldsymbol{a}^{\boldsymbol{l} - 1} + \boldsymbol{b}^{l}} \right)$
这里的激活函数一般是sigmoid或者tanh。
经过了若干全连接层之后,最后的一层为Softmax输出层。此时输出层和普通的全连接层唯一的区别是,激活函数是softmax函数。这里需要需要我们定义的CNN模型参数是:
1) 全连接层的激活函数
2) 全连接层各层神经元的个数
3.1.5 CNN前向传播小结
我们现在总结下CNN的前向传播算法。
输入:1个图片样本,CNN模型的层数L和所有隐藏层的类型。
- 对于卷积层,要定义卷积核的大小K,卷积核子矩阵的维度F,填充大小P,步幅S。
- 对于池化层,要定义池化区域大小k和池化标准(MAX或Average)。
- 对于全连接层,要定义全连接层的激活函数(输出层除外)和各层的神经元个数。
输出:CNN模型的输出$\boldsymbol{a}^{L}$
1)根据输入层的填充大小P,填充原始图片的边缘,得到输入张量$\boldsymbol{a}^{l}$
2)初始化所有隐藏层的参数$\boldsymbol{W}$,$\boldsymbol{b}$
3)for $l=2$ to $L-1$:
- 如果第$l$层是卷积层,则输出为
$\boldsymbol{a}^{l} = ReLU\left( \boldsymbol{z}^{l} \right) = ReLU\left( {\boldsymbol{a}^{l - 1}*\boldsymbol{W}^{l} + \boldsymbol{b}^{l}} \right)$
- 如果第$l$层是池化层,则输出为
$\boldsymbol{a}^{l} = \boldsymbol{z}^{l} = pooling\left( \boldsymbol{a}^{l - 1} \right)$
这里的$pooling\left( ~ \right)$指按照池化区域大小k和池化标准将输入张量缩小的过程。
- 如果第$l$层是全连接层,则输出为
$\boldsymbol{a}^{l} = \sigma\left( \boldsymbol{z}^{l} \right) = \sigma\left( {\boldsymbol{W}^{\boldsymbol{l}}\boldsymbol{a}^{\boldsymbol{l} - 1} + \boldsymbol{b}^{l}} \right)$
4) 对于输出层第L层:
$\boldsymbol{a}^{L} = softmax\left( \boldsymbol{z}^{L} \right) = softmax\left( {\boldsymbol{W}^{\boldsymbol{L}}\boldsymbol{a}^{\boldsymbol{L} - 1} + \boldsymbol{b}^{L}} \right)$
以上就是CNN前向传播算法的过程总结。有了CNN前向传播算法的基础,我们后面再来理解CNN的反向传播算法就简单多了。
3.2 CNN的反向梯度推导
与推导DNN时候类似,我们定义$\boldsymbol{\delta}^{l} = \frac{\partial l}{\partial\boldsymbol{z}^{\boldsymbol{l}}}$
要套用DNN的反向传播算法到CNN,有几个问题需要解决:
1)池化层没有激活函数,这个问题倒比较好解决,我们可以令池化层的激活函数为$\sigma\left( \boldsymbol{z} \right) = \boldsymbol{z}$,即激活后就是自己本身。这样池化层激活函数的导数为1。
2)池化层在前向传播的时候,对输入进行了压缩,那么我们现在需要向前反向推导$\boldsymbol{\delta}^{l - 1}$,这个推导方法和DNN完全不同。
3)卷积层是通过张量卷积,或者说若干个矩阵卷积求和而得的当前层的输出,这和DNN很不相同,DNN的全连接层是直接进行矩阵乘法得到当前层的输出。这样在卷积层反向传播的时候,$\boldsymbol{\delta}^{l - 1}$的递推计算方法肯定有所不同。
4)对于卷积层,由于$\boldsymbol{W}$使用的运算是卷积,那么从$\boldsymbol{\delta}^{l }$推导出该层的所有卷积核的$\boldsymbol{W}$和$\boldsymbol{b}$的方式也不同。
从上面可以看出,问题1比较好解决,但是问题2,3,4就需要好好的动一番脑筋了,而问题2,3,4也是解决CNN反向传播算法的关键所在。另外大家要注意到的是,DNN中的$\boldsymbol{a}^{\boldsymbol{l}}$和$\boldsymbol{z}^{\boldsymbol{l}}$都只是一个向量,而CNN中的$\boldsymbol{a}^{\boldsymbol{l}}$和$\boldsymbol{z}^{\boldsymbol{l}}$都是一个张量,这个张量是一般三维的,即由若干个输入的子矩阵组成。
下面我们就针对问题2,3,4来一步步研究CNN的反向传播算法。
在推导过程中,需要注意的是,由于卷积层可以有多个卷积核,各个卷积核的处理方法是完全相同且独立的,为了简化算法公式的复杂度,我们下面提到卷积核都是卷积层中若干卷积核中的一个。
因为CNN前传的顺序一般是卷积-池化,所以BP推导的时候,我们先看池化的BP推导,然后在看卷积的BP推导。
3.2.1 已知池化层的$\delta^{l}$,推导前一隐藏层的$\delta^{l-1}$
我们先搬出池化层的计算公式:
$\boldsymbol{a}^{l} = \boldsymbol{z}^{l} = pooling\left( \boldsymbol{a}^{l - 1} \right) = pooling\left( {\sigma\left( \boldsymbol{z}^{l - 1} \right)} \right)$
其中$size\left( \boldsymbol{z}^{l} \right) < size\left( \boldsymbol{a}^{l - 1} \right) = size\left( \boldsymbol{z}^{l - 1} \right)$,即$size\left( \boldsymbol{\delta}^{l} \right) < size\left( \boldsymbol{\delta}^{l - 1} \right)$
先分析下这个$pooling{()}$是在做什么。在前向传播算法时,池化层一般我们会用MAX或者Average对输入进行池化,池化的区域大小是已知的。
现在我们反过来,要从缩小后的误差$\boldsymbol{\delta}^{\boldsymbol{l}}$,还原前一次较大区域对应的误差$\boldsymbol{\delta}^{\boldsymbol{l-1}}$。
在反向传播时,我们首先会把$\boldsymbol{\delta}^{\boldsymbol{l}}$的所有子矩阵矩阵大小还原成池化之前的大小。
如果是MAX,则把$\boldsymbol{\delta}^{\boldsymbol{l}}$的所有子矩阵的各个池化局域的值放在之前做前向传播算法得到最大值的位置。如果是Average,则把$\boldsymbol{\delta}^{\boldsymbol{l}}$的所有子矩阵的各个池化局域的值取平均后放在还原后的子矩阵位置。这个过程一般叫做upsample。
下面以$\boldsymbol{\delta}^{\boldsymbol{l}}$的其中一个子矩阵为例:
假设我们的池化区域大小是2 x 2。$\boldsymbol{\delta}^{\boldsymbol{l}}$的第k各子矩阵为$\boldsymbol{\delta}_{k}^{l} = \left\lbrack \begin{array}{ll} 2 & 8 \\ 4 & 6 \\ \end{array} \right\rbrack$($\boldsymbol{\delta}^{\boldsymbol{l}}$子矩阵数等于前一层卷积层的卷积核数)。
由于池化区域为2x2,我们先将$\boldsymbol{\delta}^{\boldsymbol{l}}$做还原,即变成:
$\left\lbrack \begin{array}{ll} \begin{array}{ll} 0 & 0 \\ 0 & 2 \\ \end{array} & \begin{array}{ll} 0 & 0 \\ 8 & 0 \\ \end{array} \\ \begin{array}{ll} 0 & 4 \\ 0 & 0 \\ \end{array} & \begin{array}{ll} 6 & 0 \\ 0 & 0 \\ \end{array} \\ \end{array} \right\rbrack$
如果是MAX,假设我们之前在前向传播时记录的最大值位置分别是左上,右下,右上,左下,则转换后的矩阵,即$\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}}$为:
$\left\lbrack \begin{array}{ll} \begin{array}{ll} 2 & 0 \\ 0 & 0 \\ \end{array} & \begin{array}{ll} 0 & 0 \\ 0 & 8 \\ \end{array} \\ \begin{array}{ll} 0 & 4 \\ 0 & 0 \\ \end{array} & \begin{array}{ll} 0 & 0 \\ 6 & 0 \\ \end{array} \\ \end{array} \right\rbrack$
如果是Average,则进行平均:转换后的矩阵,即${\partial\boldsymbol{a}_{k}^{l - 1}}$为:
$\left\lbrack \begin{array}{ll} \begin{array}{ll} 0.5 & 0.5 \\ 0.5 & 0.5 \\ \end{array} & \begin{array}{ll} 2 & 2 \\ 2 & 2 \\ \end{array} \\ \begin{array}{ll} 1 & 1 \\ 1 & 1 \\ \end{array} & \begin{array}{ll} 1.5 & 1.5 \\ 1.5 & 1.5 \\ \end{array} \\ \end{array} \right\rbrack$
于是我们得到了$\boldsymbol{\delta}_{k}^{l}$与$\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}}$的关系如下:
$\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} = upsample\left( \boldsymbol{\delta}_{k}^{l} \right)$
接下来先做个错误演示:
我们想通过求$\frac{\partial\boldsymbol{a}_{k}^{l - 1}}{\partial\boldsymbol{z}_{k}^{l - 1}}$,从而得到$\boldsymbol{\delta}_{k}^{l - 1} = \frac{\partial l}{\partial\boldsymbol{z}_{k}^{l - 1}} = \left( \frac{\boldsymbol{a}_{k}^{l - 1}}{\boldsymbol{z}_{k}^{l - 1}} \right)^{T}\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}}$
,但这个式子是不对的注意,因为$\frac{\partial\boldsymbol{a}_{k}^{l - 1}}{\partial\boldsymbol{z}_{k}^{l - 1}}$是矩阵对矩阵的导数,所以并不适用向量对向量的链式法则。
于是我们继续追本溯源,链式法则是从何而来?源头仍然是微分。我们直接从微分的角度入手建立复合法则,从而绕过求$\frac{\partial\boldsymbol{a}_{k}^{l - 1}}{\partial\boldsymbol{z}_{k}^{l - 1}}$的过程基于$\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}}$往下做微分求得$\frac{\partial l}{\partial\boldsymbol{z}_{k}^{l - 1}}$。
正确的解法是用复合微分来接解问题:
我们已知$\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}}$,$\boldsymbol{a}_{k}^{l - 1} = \sigma\left( \boldsymbol{z}_{k}^{l - 1} \right)$,求$\frac{\partial l}{\partial\boldsymbol{z}_{k}^{l - 1}}$
解:
已知$\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}}$这意味着,有微分等式$dl = tr\left( {\left( \frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \right)^{T}d\boldsymbol{a}_{k}^{l - 1}} \right)$成立。
我们把$d\boldsymbol{a}_{k}^{l - 1}$又看成是一个微分问题,基于$\boldsymbol{a}_{k}^{l - 1} = \sigma\left( \boldsymbol{z}_{k}^{l - 1} \right)$套娃式地求其微分变换:
$tr\left( {\left( \frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \right)^{T}d\boldsymbol{a}_{k}^{l - 1}} \right) = tr\left( {\left( \frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \right)^{T}d\sigma\left( \boldsymbol{z}_{k}^{l - 1} \right)} \right) = tr\left( {\left( \frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \right)^{T}\left( {\sigma^{\'}\left( \boldsymbol{z}_{k}^{l - 1} \right) \odot d\boldsymbol{z}_{k}^{l - 1}} \right)} \right) = tr\left( {\left( {\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \odot \sigma^{\'}\left( \boldsymbol{z}_{k}^{l - 1} \right)} \right)^{T}d\boldsymbol{z}_{k}^{l - 1}} \right)$
于是,我们得到$dl = tr\left( {\left( {\frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \odot \sigma^{\'}\left( \boldsymbol{z}_{k}^{l - 1} \right)} \right)^{T}d\boldsymbol{z}_{k}^{l - 1}} \right)$的结论,所以
$\boldsymbol{\delta}_{k}^{l - 1} = \frac{\partial l}{\partial\boldsymbol{a}_{k}^{l - 1}} \odot \sigma^{\'}\left( \boldsymbol{z}_{k}^{l - 1} \right) = upsample\left( \boldsymbol{\delta}_{k}^{l} \right) \odot \sigma^{\'}\left( \boldsymbol{z}_{k}^{l - 1} \right)$
至此,我们已经知道误差逆着经过$pooling$层会发生什么了,经过前梯度矩阵为$\boldsymbol{\delta}_{k}^{l}$,经过后梯度矩阵变成了$\boldsymbol{\delta}_{k}^{l - 1} = upsample\left( \boldsymbol{\delta}_{k}^{l} \right) \odot \sigma^{\'}\left( \boldsymbol{z}_{k}^{l - 1} \right)$
3.2.2 已知卷积层的$\delta^{l}$,推导前一隐藏层的$\delta^{l-1}$
接下来我们要看看误差逆着经过卷积层会发生什么事情。
我们首先回忆下卷积层的前向传播公式:
$\boldsymbol{a}^{l} = \sigma\left( \boldsymbol{z}^{l} \right) = \sigma\left( {\boldsymbol{a}^{l - 1}*\boldsymbol{W}^{l} + \boldsymbol{b}^{l}} \right)$
因此要推导出$\boldsymbol{\delta}^{l - 1}$和$\boldsymbol{\delta}^{l}$的递推关系,必须计算$\frac{\partial\boldsymbol{z}^{l}}{\partial\boldsymbol{z}^{l - 1}}$。
注意:这里实际上只推导了$\boldsymbol{\delta}^{l}$梯度矩阵反向经过某个卷积核中的某个子矩阵$\boldsymbol{W}^{l}$所得到的上$\boldsymbol{\delta}^{l - 1}$梯度矩阵。假设前传流程如下:

那么在反向传播时,我们所讨论的是:
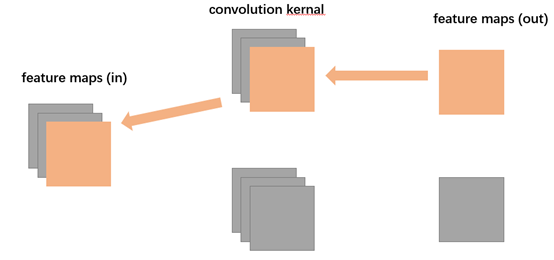
下面正式开始。
我们注意到:
$\boldsymbol{z}^{l} = \boldsymbol{a}^{l - 1}*\boldsymbol{W}^{l} + \boldsymbol{b}^{l} = \sigma\left( \boldsymbol{z}^{l - 1} \right)*\boldsymbol{W}^{l} + \boldsymbol{b}^{l}$
这里先给出下面这个等式,然后说明怎么是得到:
$\boldsymbol{\delta}^{l - 1} = \left( \frac{\partial\boldsymbol{z}^{l}}{\partial\boldsymbol{z}^{l - 1}} \right)^{T}\boldsymbol{\delta}^{l} = \boldsymbol{\delta}^{l}*rot180\left( \boldsymbol{W}^{l} \right) \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)$
对比DNN中的$\boldsymbol{\delta}^{l - 1} = \left( \boldsymbol{W}^{l} \right)^{T}\delta^{l} \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)$两者还是挺相似的。
现在开始证明$\boldsymbol{\delta}^{l - 1} = \left( \frac{\partial\boldsymbol{z}^{l}}{\partial\boldsymbol{z}^{l - 1}} \right)^{T}\boldsymbol{\delta}^{l} = \boldsymbol{\delta}^{l}*rot180\left( \boldsymbol{W}^{l} \right) \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)$:
首先给出二维卷积公式:
$\boldsymbol{C}\left( {i,j} \right) = \left( {\boldsymbol{X}*\boldsymbol{W}} \right)\left( {i,j} \right){\sum\limits_{m}{\sum\limits_{n}{w\left( {m,n} \right)x\left( {i - m,j - m} \right)}}}$
在CNN中,虽然我们也是说卷积,但是我们的卷积公式和严格意义数学中的定义稍有不同,比如对于二维的卷积,定义为:
$\boldsymbol{C}\left( {i,j} \right) = \left( {\boldsymbol{X}*\boldsymbol{W}} \right)\left( {i,j} \right){\sum\limits_{m}{\sum\limits_{n}{w\left( {m,n} \right)x\left( {i + m,j + m} \right)}}}$
数学上和CNN上的卷积操作的区别是,卷积核在前者需要翻转180度。
根据CNN中的二维卷积定义,对$\boldsymbol{z}^{l} = \boldsymbol{a}^{l - 1}*\boldsymbol{W}^{l} + \boldsymbol{b}^{l} = \sigma\left( \boldsymbol{z}^{l - 1} \right)*\boldsymbol{W}^{l} + \boldsymbol{b}^{l}$进行元素级的展开,我们得到:
$z_{x,y}^{l} = \left( {\boldsymbol{a}^{l - 1}*\boldsymbol{W}^{l}} \right)_{x,y} + b_{x,y}^{l} = {\sum\limits_{m}{\sum\limits_{n}{w_{m,n}^{l}\sigma\left( z_{x + m,y + n}^{l - 1} \right)}}}{+ b}_{x,y}^{l}$
由1.7.3(详情见《神经网络的梯度推导与代码验证》之数学基础篇:矩阵微分与求导)的标量对多个矩阵的链式求导法则$\frac{\partial z}{\partial x_{ij}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial z}{\partial Y_{kl}}\frac{\partial Y_{kl}}{\partial X_{ij}}}}}$可得$\boldsymbol{\delta}^{l}$中的元素$\delta_{x,y}^{l}$
满足以下式子:
$\delta_{x,y}^{l - 1} = \frac{\partial l}{\partial z_{x,y}^{l - 1}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{z_{x,y}^{l - 1}}}}}$
联立上面两个等式,我们可以展开$z_{k,l}^{l}$从而得到:
$\delta_{x,y}^{l - 1} = \frac{\partial l}{\partial z_{x,y}^{l - 1}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{z_{x,y}^{l - 1}}}}} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}\frac{\partial z_{k,l}^{l}}{{\partial z}_{x,y}^{l - 1}} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}\frac{\partial\left( {{\sum\limits_{m}{\sum\limits_{n}{w_{m,n}^{l}\sigma\left( z_{k + m,l + n}^{l - 1} \right) +}}}b_{x,y}^{l}} \right)}{\partial z_{x,y}^{l - 1}}}}}}}}$
上式看着挺恶心的,但仔细分析$\frac{\partial\left( {{\sum\limits_{m}{\sum\limits_{n}{w_{m,n}^{l}\sigma\left( z_{k + m,l + n}^{l - 1} \right) +}}}b_{x,y}^{l}} \right)}{\partial z_{x,y}^{l - 1}}$可以发现虽然分子是个mn项的累加,但因为要对$z_{x,y}^{l - 1}$进行偏微分,所以显然最后保留下来的,只有同时满足$x = k + m$,$y = ~l + n$两个约束的项。所以有:
$\delta_{x,y}^{l - 1} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}\frac{\partial\left( {{\sum\limits_{m}{\sum\limits_{n}{w_{m,n}^{l}\sigma\left( z_{k + m,l + n}^{l - 1} \right) +}}}b_{x,y}^{l}} \right)}{\partial z_{x,y}^{l - 1}}}}} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}\frac{\partial\left( {w_{x - k,y - l}^{l}\sigma\left( z_{x,y}^{l - 1} \right)} \right)}{\partial z_{x,y}^{l - 1}}}}} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}w_{x - k,y - l}^{l}\sigma^{\'}\left( z_{x,y}^{l - 1} \right) =}}}\sigma^{\'}\left( z_{x,y}^{l - 1} \right){\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}w_{x - k,y - l}^{l}}}}$
观察$\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}w_{x - k,y - l}^{l}}}$这一项可以发现,这就是一般数学上的卷积运算,而如果我们统一用CNN上的卷积定义来表示这一项,根据之前所提到的两者的联系,这两种卷积操作的区别是卷积核相差个rot180操作,所以有:
$\boldsymbol{\delta}^{l - 1} = \boldsymbol{\delta}^{l}*rot180\left( \boldsymbol{W}^{l} \right) \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)$
注意到$\boldsymbol{\delta}^{l - 1}$与$\boldsymbol{\delta}^{l}$的尺寸是不同的,从$l - 1$层到$l$层进行的卷积操作叫“valid convolution” (更多不同的卷积模式可参考:https://www.cnblogs.com/itmorn/p/11179448.html),如下图所示:
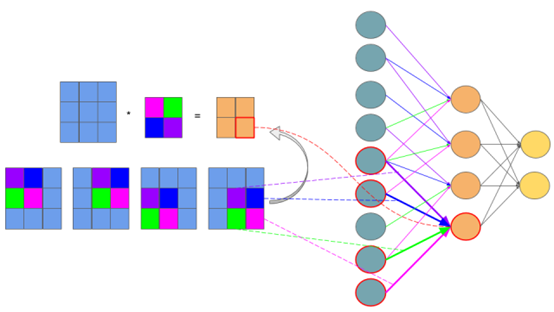
所以$\boldsymbol{\delta}^{l - 1}$的尺寸要小于$\boldsymbol{\delta}^{l}$,而如今误差要逆着反传回去,显然不是做“valid convolution”因为这样只会让尺寸更小。所以我们要做的是“full convolution”,一种直观的解释是,feature map经过valid convolution后尺寸会缩小,而对于同样大小的卷积核和步长,如果接下来使用full convolution的话就能让尺寸恢复成原来的大小。
我们可以通过一个简单的例子直观感受一下为啥卷积核要翻转,为啥相对于前传的valid convolution,反传要做full convolution。
假设第$l - 1$层的输出$\boldsymbol{a}^{l - 1}$是一个3 x 3的矩阵,第$l$层的卷积核$\boldsymbol{W}^{l}$是一个2 x 2的矩阵,采用1像素的步幅,激活函数用的是线性函数,输出的$\boldsymbol{z}^{l}$是一个2 x 2的矩阵。我们简化$\boldsymbol{b}^{l}$成都是0,则有:
$\boldsymbol{z}^{l} = conv2D\left( {\boldsymbol{a}^{l - 1},\boldsymbol{W}^{l},\'valid\'} \right)$
对上述式子展开,进行元素级分析:
$\left\lbrack \begin{array}{ll} z_{11} & z_{12} \\ z_{21} & z_{22} \\ \end{array} \right\rbrack = \left\lbrack \begin{array}{lll} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{array} \right\rbrack*\left\lbrack \begin{array}{l} \begin{array}{ll} w_{11} & w_{12} \\ \end{array} \\ \begin{array}{ll} w_{21} & w_{22} \\ \end{array} \\ \end{array} \right\rbrack$
其中卷积符号代表CNN中的卷积操作,利用该定义,我们得到:
$z_{11} = a_{11}w_{11} + a_{12}w_{12} + a_{21}w_{21} + a_{22}w_{22}$
$z_{12} = a_{12}w_{11} + a_{13}w_{12} + a_{22}w_{21} + a_{23}w_{22}$
$z_{21} = a_{21}w_{11} + a_{22}w_{12} + a_{31}w_{21} + a_{32}w_{22}$
$z_{22} = a_{22}w_{11} + a_{13}w_{12} + a_{32}w_{21} + a_{33}w_{22}$
接着我们模拟反向求导:
根据链式法则:$\frac{\partial l}{\partial a_{x,y}^{l - 1}} = {\sum\limits_{i}{\sum\limits_{j}{\frac{\partial l}{\partial z_{i,j}^{l}}\frac{\partial z_{i,j}^{l}}{a_{x,y}^{l - 1}}}}}$我们得到:
$\frac{\partial l}{\partial a_{11}^{l - 1}} = {\sum\limits_{i}{\sum\limits_{j}{\frac{\partial l}{\partial z_{i,j}^{l}}\frac{\partial z_{i,j}^{l}}{a_{x,y}^{l - 1}}}}} = \frac{\partial l}{\partial z_{11}^{l}}\frac{\partial z_{11}^{l}}{a_{11}^{l - 1}} + \frac{\partial l}{\partial z_{12}^{l}}\frac{\partial z_{12}^{l}}{a_{11}^{l - 1}} + \frac{\partial l}{\partial z_{21}^{l}}\frac{\partial z_{21}^{l}}{a_{11}^{l - 1}} + \frac{\partial l}{\partial z_{22}^{l}}\frac{\partial z_{22}^{l}}{a_{11}^{l - 1}}$
对$z$展开后我们得到:
$\frac{\partial l}{\partial a_{11}^{l - 1}} = \frac{\partial l}{\partial z_{11}^{l}}w_{11} = \delta_{11}^{l}w_{11}$
同理,我们可以得到:
$\frac{\partial l}{\partial a_{12}^{l - 1}} = \delta_{11}^{l}w_{12} + \delta_{12}^{l}w_{11}$
$\frac{\partial l}{\partial a_{13}^{l - 1}} = \delta_{12}^{l}w_{12}$
$\frac{\partial l}{\partial a_{21}^{l - 1}} = \delta_{11}^{l}w_{21} + \delta_{21}^{l}w_{11}$
$\frac{\partial l}{\partial a_{22}^{l - 1}} = \delta_{11}^{l}w_{22} + \delta_{12}^{l}w_{21} + \delta_{21}^{l}w_{12} + \delta_{22}^{l}w_{11}$
$\frac{\partial l}{\partial a_{23}^{l - 1}} = \delta_{12}^{l}w_{22} + \delta_{22}^{l}w_{12}$
$\frac{\partial l}{\partial a_{31}^{l - 1}} = \delta_{21}^{l}w_{21}$
$\frac{\partial l}{\partial a_{32}^{l - 1}} = \delta_{21}^{l}w_{22} + \delta_{22}^{l}w_{21}$
$\frac{\partial l}{\partial a_{33}^{l - 1}} = \delta_{22}^{l}w_{22}$
这上面9个式子其实可以用一个矩阵卷积的形式表示,即:
$\left\lbrack \begin{array}{ll} \begin{array}{ll} 0 & 0 \\ 0 & \delta_{11}^{l} \\ \end{array} & \begin{array}{ll} 0 & 0 \\ \delta_{12}^{l} & 0 \\ \end{array} \\ \begin{array}{ll} 0 & \delta_{21}^{l} \\ 0 & 0 \\ \end{array} & \begin{array}{ll} \delta_{22}^{l} & 0 \\ 0 & 0 \\ \end{array} \\ \end{array} \right\rbrack*\left\lbrack \begin{array}{ll} w_{22} & w_{21} \\ w_{12} & w_{11} \\ \end{array} \right\rbrack = \left\lbrack \begin{array}{lll} \frac{\partial l}{\partial a_{11}^{l - 1}} & \frac{\partial l}{\partial a_{12}^{l - 1}} & \frac{\partial l}{\partial a_{13}^{l - 1}} \\ \frac{\partial l}{\partial a_{21}^{l - 1}} & \frac{\partial l}{\partial a_{22}^{l - 1}} & \frac{\partial l}{\partial a_{23}^{l - 1}} \\ \frac{\partial l}{\partial a_{31}^{l - 1}} & \frac{\partial l}{\partial a_{32}^{l - 1}} & \frac{\partial l}{\partial a_{33}^{l - 1}} \\ \end{array} \right\rbrack$
可以看到$\delta$周围都包围着0,这叫做full模式的卷积运算,因为只有这样才能让$\boldsymbol{\delta}^{l}$矩阵扩展到$\frac{\partial l}{\partial\boldsymbol{a}^{l - 1}}$的大小。而且我们还能发现,现在的卷积核跟前向传播时候的卷积核对比确实是发生了180度旋转,即:
$\frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} = conv2D\left( {\boldsymbol{\delta}^{l},rot180\left( \boldsymbol{W}^{l} \right),\'full\'} \right)$
一个结论是如果前向传播是valid模式的卷积运算,那么反向传播就需要做full模式的卷积操作。
接着让我们再看一个更通用的例子2:
假设第$l - 1$层的输出$\boldsymbol{a}^{l - 1}$是一个5 x 5的矩阵,第$l$层的卷积核$\boldsymbol{W}^{l}$是一个3x3的矩阵,采用2像素的步幅,激活函数用的是线性函数,输出的$\boldsymbol{z}^{l}$是一个2 x 2的矩阵。我们简化$\boldsymbol{b}^{l}$成都是0,则有:
$\boldsymbol{z}^{l} = conv2D\left( {\boldsymbol{a}^{l - 1},\boldsymbol{W}^{l},^{\'}valid^{\'},~stride = 2} \right)$
对上述式子展开,进行元素级分析:
$\left\lbrack \begin{array}{ll} z_{11} & z_{12} \\ z_{21} & z_{22} \\ \end{array} \right\rbrack = \left\lbrack \begin{array}{ll} \begin{array}{lll} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{array} & \begin{array}{ll} a_{14} & a_{15} \\ a_{24} & a_{25} \\ a_{34} & a_{35} \\ \end{array} \\ \begin{array}{lll} a_{41} & a_{42} & a_{43} \\ a_{51} & a_{52} & a_{53} \\ \end{array} & \begin{array}{ll} a_{44} & a_{45} \\ a_{54} & a_{55} \\ \end{array} \\ \end{array} \right\rbrack*\left\lbrack \begin{array}{ll} \begin{array}{l} w_{11} \\ w_{21} \\ \end{array} & \begin{array}{l} \begin{array}{ll} w_{12} & w_{13} \\ \end{array} \\ \begin{array}{ll} w_{22} & w_{23} \\ \end{array} \\ \end{array} \\ w_{31} & \begin{array}{ll} w_{32} & w_{33} \\ \end{array} \\ \end{array} \right\rbrack$
其中卷积符号代表CNN中的卷积操作,利用该定义,我们得到:
$z_{11} = a_{11}w_{11} + a_{12}w_{12} + a_{13}w_{13} + a_{21}w_{21} + a_{22}w_{22} + a_{23}w_{23} + a_{31}w_{31} + a_{32}w_{32} + a_{33}w_{33}$
$z_{12} = a_{13}w_{11} + a_{14}w_{12} + a_{15}w_{13} + a_{23}w_{21} + a_{24}w_{22} + a_{25}w_{23} + a_{33}w_{31} + a_{34}w_{32} + a_{35}w_{33}$
$z_{21} = a_{31}w_{11} + a_{32}w_{12} + a_{33}w_{13} + a_{41}w_{21} + a_{42}w_{22} + a_{43}w_{23} + a_{51}w_{31} + a_{52}w_{32} + a_{53}w_{33}$
$z_{22} = a_{33}w_{11} + a_{34}w_{12} + a_{35}w_{13} + a_{43}w_{21} + a_{44}w_{22} + a_{45}w_{23} + a_{53}w_{31} + a_{54}w_{32} + a_{55}w_{33}$
接着我们模拟反向求导过程:
根据链式法则:$\frac{\partial l}{\partial a_{x,y}^{l - 1}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{a_{x,y}^{l - 1}}}}}$,我们得到:
$\frac{\partial l}{\partial a_{11}^{l - 1}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{a_{x,y}^{l - 1}}}}} = \frac{\partial l}{\partial z_{11}^{l}}\frac{\partial z_{11}^{l}}{a_{11}^{l - 1}} + \frac{\partial l}{\partial z_{12}^{l}}\frac{\partial z_{12}^{l}}{a_{11}^{l - 1}} + \frac{\partial l}{\partial z_{21}^{l}}\frac{\partial z_{21}^{l}}{a_{11}^{l - 1}} + \frac{\partial l}{\partial z_{22}^{l}}\frac{\partial z_{22}^{l}}{a_{11}^{l - 1}}$
于是我们得到:
$\frac{\partial l}{\partial a_{11}^{l - 1}} = \frac{\partial l}{\partial z_{11}^{l}}w_{11} = \delta_{11}w_{11}$
同理,我们可以得到(同一个$\frac{\partial l}{\partial a_{xy}^{l - 1}}$的下标规律是$\delta$的下标$\pm 1$则$w$的下标$\mp 2$):
$\frac{\partial l}{\partial a_{12}^{l - 1}} = \delta_{11}w_{12}$
$\frac{\partial l}{\partial a_{13}^{l - 1}} = \delta_{11}w_{13} + \delta_{12}w_{11}$
$\frac{\partial l}{\partial a_{14}^{l - 1}} = \delta_{12}w_{12}$
...其他的$\frac{\partial l}{\partial a_{xy}^{l - 1}}$以此类推。
实际我们可以用下面这个卷积运算来表示上面这些海量的偏导数:
$\left\lbrack \begin{array}{lll} \begin{array}{ll} 0 & 0 \\ 0 & 0 \\ \end{array} & \begin{array}{lll} 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} & \begin{array}{ll} 0 & 0 \\ 0 & 0 \\ \end{array} \\ \begin{array}{ll} 0 & 0 \\ 0 & 0 \\ \end{array} & \begin{array}{lll} \delta_{11} & 0 & \delta_{12} \\ 0 & 0 & 0 \\ \delta_{21} & 0 & \delta_{22} \\ \end{array} & \begin{array}{ll} 0 & 0 \\ 0 & 0 \\ \end{array} \\ \begin{array}{ll} 0 & 0 \\ 0 & 0 \\ \end{array} & \begin{array}{lll} 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} & \begin{array}{ll} 0 & 0 \\ 0 & 0 \\ \end{array} \\ \end{array} \right\rbrack*\left\lbrack \begin{array}{ll} \begin{array}{l} w_{33} \\ w_{23} \\ \end{array} & \begin{array}{l} \begin{array}{ll} w_{32} & w_{31} \\ \end{array} \\ \begin{array}{ll} w_{22} & w_{21} \\ \end{array} \\ \end{array} \\ w_{13} & \begin{array}{ll} w_{12} & w_{11} \\ \end{array} \\ \end{array} \right\rbrack = \left\lbrack \begin{array}{lll} \frac{\partial l}{\partial a_{11}^{l - 1}} & \cdots & \frac{\partial l}{\partial a_{15}^{l - 1}} \\ \vdots & \ddots & \vdots \\ \frac{\partial l}{\partial a_{51}^{l - 1}} & \cdots & \frac{\partial l}{\partial a_{51}^{l - 1}} \\ \end{array} \right\rbrack$
由上式可知,在例子二中卷积核确实也旋转了180度。但是跟第一个例子相比,这里的$\delta_{ij}$是散开了的。分析其原因,我认为解释是这样的:从我们的数学推导过程来看,我们是在默认stride=1的情况下推导的,而紧接着所举的例子1也是在stride=1的情况证明推导的正确性,所以自然也是没什么问题。而在例子2中,stride=2了,如果我们不让$\delta_{ij}$散开,那么最后左边这个矩阵与卷积核进行卷积之后是无法得到右边矩阵的那种尺寸的。
那么当stride>1时,$\delta_{ij}$需要散得多开呢?
如果我们想让stride>1时和stride=1时的结果能得到统一,我认为我们可以将stride>1的情况视为是stride=1的特殊情况,例如,stride=2的话,两个矩阵先按照stride=1那样进行卷积,在位移不能被2整除的地方,卷积结果就输出0。这样我们就得到下面这一对有趣的计算模式:
- 前向计算有:
$conv2D\left( {\boldsymbol{a}^{l - 1},\boldsymbol{W}^{l},^{\'}valid^{\'},~stride = 2} \right) = \left\lbrack \begin{array}{lll} z_{11} & 0 & z_{12} \\ 0 & 0 & 0 \\ z_{21} & 0 & z_{22} \\ \end{array} \right\rbrack\overset{down~sampling}{\rightarrow}\boldsymbol{z}^{l} = \left\lbrack \begin{array}{ll} z_{11} & z_{12} \\ z_{21} & z_{22} \\ \end{array} \right\rbrack$
- 计算反向梯度时有:
loss $l$对矩阵$\boldsymbol{z}^{l}$的导数,即$\boldsymbol{\delta}^{l}$,它经过上采样后再跟$rot180\left( \boldsymbol{W}^{l} \right)$进行stride=1的full模式的卷积运算的结果就是上面例子2的最终结果,即:
$\boldsymbol{\delta}^{l} = \left\lbrack \begin{array}{ll} \delta_{11} & \delta_{12} \\ \delta_{21} & \delta_{22} \\ \end{array} \right\rbrack\overset{up~sampling}{\rightarrow}\left\lbrack \begin{array}{lll} \delta_{11} & 0 & \delta_{12} \\ 0 & 0 & 0 \\ \delta_{21} & 0 & \delta_{22} \\ \end{array} \right\rbrack$
$\frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} = conv2D\left( {\left\lbrack \begin{array}{lll} \delta_{11} & 0 & \delta_{12} \\ 0 & 0 & 0 \\ \delta_{21} & 0 & \delta_{22} \\ \end{array} \right\rbrack,rot180\left( \boldsymbol{W}^{l} \right),\'full\'} \right)$
分析上面这个结果不禁让人思考深度学习框架里的conv函数是怎么实现的。出于方便进行梯度反向计算的目的,前向传播的任何stride>1的卷积操作,都应当看成是特殊的stride=1的卷积会更好,即stride>1的输出等于是对在stride=1下卷积得到的特征图的做subsampling,前一段时间在网上搜一些Conv2DTranspose相关的资料的时候也看到过这种说法,貌似conv函数的stride=2就是基于stride=1的特征图做下采样得到的。
回到正题,求得$\frac{\partial l}{\partial\boldsymbol{a}^{l - 1}}$进一步求$\frac{\partial l}{\partial\boldsymbol{z}^{l - 1}}$就非常简单了:
因为$dl = \left( \frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} \right)^{T}d\boldsymbol{a}^{l - 1}$,$\boldsymbol{a}^{l - 1} = \sigma\left( \boldsymbol{z}^{l - 1} \right)$
所以通过链式(套娃)法则有:
$dl = \left( \frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} \right)^{T}d\boldsymbol{a}^{l - 1} = \left( \frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} \right)^{T}d\sigma\left( \boldsymbol{z}^{l - 1} \right) = \left( \frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} \right)^{T}diag\left( {\sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)} \right)d\boldsymbol{z}^{l - 1} = \left( {diag\left( {\sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)} \right)\frac{\partial l}{\partial\boldsymbol{a}^{l - 1}}} \right)^{T}d\boldsymbol{z}^{l - 1} = \left( {\frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)} \right)^{T}d\boldsymbol{z}^{l - 1}$
所以求出$\frac{\partial l}{\partial\boldsymbol{z}^{l - 1}} = \frac{\partial l}{\partial\boldsymbol{a}^{l - 1}} \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)$,这就是本小节开头那个待说明的结论:
$\boldsymbol{\delta}^{l - 1} = \left( \frac{\partial\boldsymbol{z}^{l}}{\partial\boldsymbol{z}^{l - 1}} \right)^{T}\boldsymbol{\delta}^{l} = \boldsymbol{\delta}^{l}*rot180\left( \boldsymbol{W}^{l} \right) \odot \sigma^{\'}\left( \boldsymbol{z}^{l - 1} \right)$
3.2.3 已知卷积层的$\delta^{l}$,推导该层的$W$,$b$的梯度
我们现在已经可以递推出每一层的梯度误差$\boldsymbol{\delta}^{\boldsymbol{l}}$了,对于全连接层,如何求$\boldsymbol{W}$和$\boldsymbol{b}$这个问题已经讨论过了,而池化层是没有$\boldsymbol{W}$和$\boldsymbol{b}$,所以就剩下卷积层的$\boldsymbol{W}$和$\boldsymbol{b}$了。
所以我们把目光放到卷积层的$\boldsymbol{W}$和$\boldsymbol{b}$上:
类似于上一小节的分析思路,我们先根据链式法则写出下面这个等式:
$\frac{\partial l}{\partial w_{x,y}^{l - 1}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{w_{x,y}^{l - 1}}}}}$
然后对$z_{k,l}^{l}$进行展开,得到:
$\frac{\partial l}{\partial w_{x,y}^{l}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{w_{x,y}^{l}}}}} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}\frac{\partial\left( {{\sum\limits_{m}{\sum\limits_{n}{w_{m,n}^{l}\sigma\left( z_{k + m,l + n}^{l - 1} \right) +}}}b_{x,y}^{l}} \right)}{\partial w_{x,y}^{l}}}}}$
类似地,我们进一步得到:
$\frac{\partial l}{\partial\boldsymbol{W}^{l}} = {\sum\limits_{k}{\sum\limits_{l}\delta_{k,l}^{l}}}\sigma\left( z_{k + x,l + y}^{l - 1} \right) = conv2D\left( {\sigma\left( \boldsymbol{z}^{l - 1} \right),\boldsymbol{\delta}^{l}~,\'valid\'} \right)$
需要注意的是,对于stride>1的情况,如果要求$\frac{\partial\boldsymbol{l}}{\partial\boldsymbol{W}^{\boldsymbol{l}}}$和$\frac{\partial\boldsymbol{l}}{\partial\boldsymbol{b}^{\boldsymbol{l}}}$,我们需要将其$\boldsymbol{\delta}^{\boldsymbol{l}}$视为是stride=1的特殊情况,就像上一小节那样。
之所以是valid模式而不是前面反向传播那样用full,是因为这里$\sigma\left( z_{k + x,l + y}^{l - 1} \right)$的尺寸比$\frac{\partial l}{\partial w_{x,y}^{l - 1}}$大,所以不可能是full的。
类似地,对于$\frac{\partial l}{\partial b_{x,y}^{l}}$我们有:
$\frac{\partial l}{\partial b_{x,y}^{l}} = {\sum\limits_{k}{\sum\limits_{l}{\frac{\partial l}{\partial z_{k,l}^{l}}\frac{\partial z_{k,l}^{l}}{b_{x,y}^{l}}}}} = {\sum\limits_{k}{\sum\limits_{l}{\delta_{k,l}^{l}\frac{\partial\left( {{\sum\limits_{m}{\sum\limits_{n}{w_{m,n}^{l}\sigma\left( z_{k + m,l + n}^{l - 1} \right) +}}}b_{x,y}^{l}} \right)}{\partial b_{x,y}^{l}}}}} = {\sum\limits_{k}{\sum\limits_{l}\delta_{k,l}^{l}}}$
因为每张feature map的bias都是靠广播来扩散到所有元素上的,所以显然所有$\frac{\partial l}{\partial b_{x,y}^{l}}$都一样:
$\frac{\partial l}{\partial b^{l}} = \frac{\partial l}{\partial b_{x,y}^{l}} = {\sum\limits_{k}{\sum\limits_{l}\delta_{k,l}^{l}}}$
3.2.4 CNN反向梯度求导总结
现在我们总结下CNN的反向传播算法,以最基本的批量梯度下降法为例来描述反向传播算法。
输入:m个图片样本,CNN模型的层数L和所有隐藏层的类型。
-
对于卷积层,要定义卷积核的大小K,卷积核子矩阵的维度F,填充大小P,步幅S。
-
对于池化层,要定义池化区域大小k和池化标准(MAX或Average)。
- 对于全连接层,要定义全连接层的激活函数(输出层除外)和各层的神经元个数。
-
梯度迭代参数迭代步长$\alpha$,最大迭代次数MAX与停止迭代阈值$\epsilon$。
输出:CNN模型各隐藏层与输出层的$\boldsymbol{W}$,$\boldsymbol{b}$
1)初始化各隐藏层与输出层的各$\boldsymbol{W}$,$\boldsymbol{b}$的值为随机值。
2)for iter from 1 to MAX:
2-1)for i =1 to m:
a)将CNN输入$\boldsymbol{a}^{1}$设置为$\boldsymbol{x}_{i}$对应的张量
b)for $l=2$ to L-1,根据下面3中情况进行前向传播计算
- 如果当前是全连接层:有$\boldsymbol{a}^{i,l} = \sigma\left( \boldsymbol{z}^{i,l} \right) = \sigma\left( {\boldsymbol{W}^{l}\boldsymbol{a}^{i,l - 1} + b^{l}} \right)$
- 如果当前是卷积层:则有$\boldsymbol{a}^{i,l} = \sigma\left( \boldsymbol{z}^{i,l} \right) = \sigma\left( {conv2D\left( {\boldsymbol{W}^{l}{,\boldsymbol{a}}^{i,l - 1},\boldsymbol{\'}valid\boldsymbol{\'}} \right)} \right)$
- 如果当前是池化层:则有$\boldsymbol{a}^{i,l} = pool\left( \boldsymbol{a}^{i,l - 1} \right)$
c)对于输出层(即第L层):$\boldsymbol{a}^{i,L} = softmax\left( \boldsymbol{z}^{i,L} \right) = softmax\left( {\boldsymbol{W}^{L}\boldsymbol{a}^{i,L - 1} + b^{L}} \right)$
d)通过损失函数计算输出层的$\boldsymbol{\delta}^{i,L}$
e)for $l=L-1$ to 2,根据下面3种情况进行反向传播计算:
- 如果当前是全连接层:$\boldsymbol{\delta}^{i,l} = \left( \boldsymbol{W}^{l + 1} \right)^{T}\boldsymbol{\delta}^{i,l + 1} \odot \sigma^{\'}\left( \boldsymbol{z}^{i,l} \right)$
- 如果当前是卷积层:$\boldsymbol{\delta}^{i,l} = conv2D\left( {\boldsymbol{\delta}^{i,l + 1},rot180\left( \boldsymbol{W}^{l + 1} \right)~} \right) \odot \sigma^{\'}\left( \boldsymbol{z}^{i,l} \right)$
- 如果当前是池化层:$\boldsymbol{\delta}^{i,l} = upsample\left( \boldsymbol{\delta}_{k}^{l + 1} \right) \odot \sigma^{\'}\left( \boldsymbol{z}_{k}^{l} \right)$
2-2)for $l=2$ to L,根据下面2种情况更新第$l$层的$\boldsymbol{W}$,$\boldsymbol{b}$
- 如果当前是全连接层:$\boldsymbol{W}^{l} = \boldsymbol{W}^{l} - \alpha{\sum\limits_{i = 1}^{m}{\boldsymbol{\delta}^{i,l}\left( \boldsymbol{a}^{i,l - 1} \right)^{T}}}$,$\boldsymbol{b}^{l} = \boldsymbol{b}^{l} - \alpha{\sum\limits_{i = 1}^{m}\boldsymbol{\delta}^{i,l}}$
- 如果当前是卷积层,对于每个卷积核的每个子矩阵执行:$\boldsymbol{W}^{l} = \boldsymbol{W}^{l} - \alpha{\sum\limits_{i = 1}^{m}{\boldsymbol{\delta}^{i,l}*\left( \boldsymbol{a}^{i,l - 1} \right)^{T}}}$,$b^{l} = b^{l} - \alpha{\sum\limits_{i = 1}^{m}{\sum\limits_{u,v}\left( \boldsymbol{\delta}^{i,l} \right)_{u,v}}}$
2-3)如果所有$\boldsymbol{W}$,$\boldsymbol{b}$的变化值都小于$\epsilon$,则停止迭代。
3)输出各隐藏层与输出层的线性关系系数矩阵和偏置,$\boldsymbol{W}$,$\boldsymbol{b}$
如果本文对您有所帮助的话,不妨点下“推荐”让它能帮到更多的人,谢谢。
参考资料
- https://www.cnblogs.com/pinard/p/6489633.html
- https://www.cnblogs.com/pinard/p/6494810.html
- https://grzegorzgwardys.wordpress.com/2016/04/22/8/#unique-identifier
(欢迎转载,转载请注明出处。欢迎留言或沟通交流: lxwalyw@gmail.com)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:《神经网络的梯度推导与代码验证》之CNN(卷积神经网络)的前向传播和反向梯度推导 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 