下面是关于“浅谈sklearn中predict与predict_proba区别”的完整攻略。
问题描述
在机器学习领域中,常需要使用模型进行预测,以便于对新数据进行分类或回归。那么,在sklearn中,predict和predict_proba有什么区别?
解决方法
示例1:在sklearn中使用predict方法
以下是在sklearn中使用predict方法的示例:
- 首先,导入必要的库:
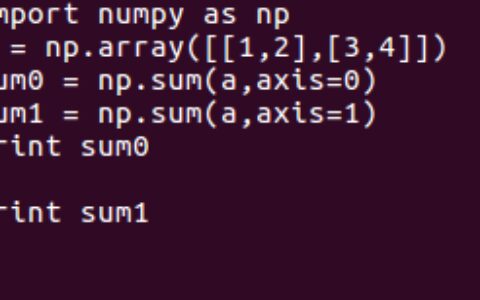
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
- 然后,加载数据集并进行数据预处理:
python
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
- 接着,定义模型并进行训练:
python
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
- 然后,使用predict方法进行预测:
python
y_pred = clf.predict(X_test)
在上面的示例中,我们使用了sklearn中的DecisionTreeClassifier模型,并使用predict方法进行预测。首先,我们加载了iris数据集并进行了数据预处理。然后,我们定义了模型并进行了训练。最后,我们使用predict方法对测试集进行预测。
示例2:在sklearn中使用predict_proba方法
以下是在sklearn中使用predict_proba方法的示例:
- 首先,导入必要的库:
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
- 然后,加载数据集并进行数据预处理:
python
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
- 接着,定义模型并进行训练:
python
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
- 然后,使用predict_proba方法进行预测:
python
y_pred_proba = clf.predict_proba(X_test)
在上面的示例中,我们使用了sklearn中的DecisionTreeClassifier模型,并使用predict_proba方法进行预测。首先,我们加载了iris数据集并进行了数据预处理。然后,我们定义了模型并进行了训练。最后,我们使用predict_proba方法对测试集进行预测。
结论
在本攻略中,我们介绍了在sklearn中predict和predict_proba的区别,并提供了两个示例说明。predict方法用于对新数据进行分类预测,返回的是预测的类别标签;而predict_proba方法用于对新数据进行分类预测,返回的是每个类别的概率值。可以根据具体的需求来选择不同的方法,并根据需要调整模型、数据集和超参数。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:浅谈sklearn中predict与predict_proba区别 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫