

导读:DeepRec从2016年起深耕至今,支持了淘宝搜索、推荐、广告等核心业务,沉淀了大量优化的算子、图优化、Runtime优化、编译优化以及高性能分布式训练框架,在稀疏模型的训练方面有着优异性能的表现。并且沉淀了稀疏场景下的动态弹性特征、动态维度弹性特征、多Hash弹性特征等功能,能够不同程度的提高稀疏模型的效果。作为阿里巴巴集团内稀疏场景的统一训练引擎,是AOP团队、XDL团队、PAI团队、AIS团队合作共建的项目。除此之外,DeepRec得到了Intel、NV相关团队的支持,针对稀疏场景下的算子、子图、以及针对硬件特点进行了深度定制优化。
本文将围绕下面三点展开:
-
DeepRec背景
-
DeepRec功能介绍
-
DeepRec开源
--
01
DeepRec背景
1. 为什么需要稀疏模型训练引擎

首先是DeepRec的背景,做搜索推广的同学肯定感同身受,流行的Tensorflow、PyTorch等,其实有很多痛点,这些痛点也就是我们为什么需要做稀疏模型的训练引擎,我们这边总结了主要分为三个方面:
第一个方面,已有的这些开源的深度学习引擎缺少了对这种稀疏模型训练功能的支持,大家也都知道像基础的这种动态弹性特征,也是在稀疏场景里常用的一个功能,这种功能在模型效果上其实会有很好的补充和提升。
第二就是训练性能,已有的一些开源深度学习框架并没有特别针对稀疏模型的训练有很好的优化。无论是在PS/worker模式还是AllReduce模式,以及不同的device CPU、GPU上的训练,大家都做了非常多的工作,而这些工作也源于我们在使用开源深度学习框架训练稀疏模型时遇到的一些问题。
第三点就是稀疏模型很具有特点、部署和Serving,稀疏模型的部署跟其他的像CV类、NLP类的一些模型的部署区别比较大,像ODL这种场景下,模型的更新很可能是需要分钟级别的、甚至秒级别的,而这些模型通常可能是几百GB、几个TB、10TB的这种超大模型,这种模型在分钟级别模型更新或者秒级别模型更新时使用开源的框架其实是没有办法做到的。
2. 什么是DeepRec

针对上面提到的问题,我们是在基于Tensorflow上面构建了这种稀疏模型的训练引擎,并且在这三个方面进行了很多优化和功能的沉淀,其实这些也是基于阿里巴巴内部的各大核心业务方的一些功能的沉淀。下面我分别来先简单说一下这三个方面分别有什么样的功能。
① 稀疏功能
在稀疏功能方面,像动态弹性特征,这其实是大家基础常用的一个功能,存在稀疏参数的维度特别大的情况。动态弹性特征在特征准入、特征淘汰上都能够在一定程度上解决过拟合、训练不充分的问题。特征淘汰也是稀疏场景特别有特点的,比如说某些商品下架,对应的特征就需要被淘汰掉。在DeepRec里面针对动态弹性特征,支持的是非常完备的,因为我们各大业务方,他们对于准入淘汰有各种不同的需求,比如我们是有基于布隆过滤器的准入,基于精准Counter的准入,种类是非常多的,也非常丰富。
此外,像基于特征频率的动态弹性维度,针对每个特征的冷热会自动地伸缩它的维度。训练不充分的时候,过拟合会相对比较严重,动态弹性的维度是根据参数出现的频度,自动的每个参数,每个特征都会有自己的维度,这样对于低频的特征,它可以用更低频的维度来表达,对高频特征可以用更高频的维度来表达。自适应的动态弹性特征,结合了有冲突和无冲突的参数,也是在一定程度上提高了模型的效果。此外,DeepRec还支持多个哈希的组合。
② 训练性能
在训练性能上,我们做了大量的工作,包括分布式训练框架,在异步训练上,我们在PS/worker上面支持超大规模的异步训练框架。同步训练,我们是基于GPU的一个硬件,实现的同步的训练框架HybridBackend。在Runtime上,我们对Tensorflow针对的稀疏模型的场景进行了一个深度的重写,包括内存、显存、执行、线程池。图优化上面,我们这边包括有自动的多阶段的pipeline,然后自动得像刚刚老师提到的这种maffer batch,包括结构化特征,然后子图的Fusion这些图优化的工作。算子优化的话包括了很多大量的feature OP的重写,以及大量稀疏算子的一些重写。
③ 部署及Serving
在模型部署和Serving上面,包括增量模型的导出加载,超大模型的Serving,以及多层的混合存储,还有多Backend的支持,以及ODL的支持。
3. DeepRec业务场景

DeepRec在阿里内部使用的核心的业务场景主要就是猜你喜欢、主搜索,还有广告的直通车和定向。
4. DeepRec研发团队
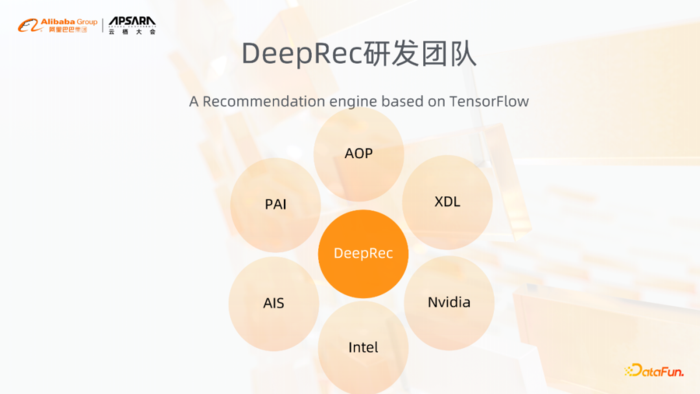
DeepRec项目其实是各个团队合作共建的。在开发团队上,主要有像主搜工程的公司,搜索工程团队的AOP团队,还有RTP、XDL、PAI、AIS,以及英特尔和英伟达都在参与DeepRec开发。
--
02
DeepRec功能介绍
1. 动态弹性特征
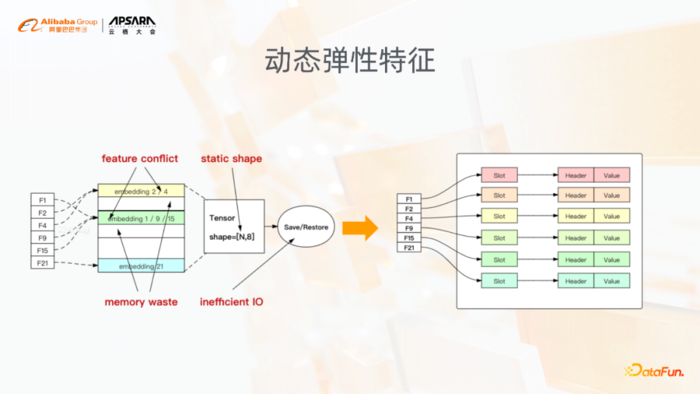
动态弹性特征是稀疏模型训练里面非常基础的一个功能,解决的就是像原生的Tensorflow里面,在训练的时候,固定的参数bucket size和固定dimension带来的问题。稀疏模型训练,通常这种增量训练可能一个模型要持续训练很久,模型参数固定之后,自然而然就有上图中列出的几个问题,像特征冲突、内存浪费,以及可能因为静态shape设置得比较大造成的无效的IO等问题。
动态弹性特征,在底层使用了hashtable的结构,可以基于训练的情况,自动插入删除这种特征,这样的话底层的hashtable,自然而然就会解决掉像前面提到的这种问题。当然在动态弹性特征之上有一些基础的功能,比如特征的准入、特征的淘汰。
2. 基于特征频率的动态弹性维度
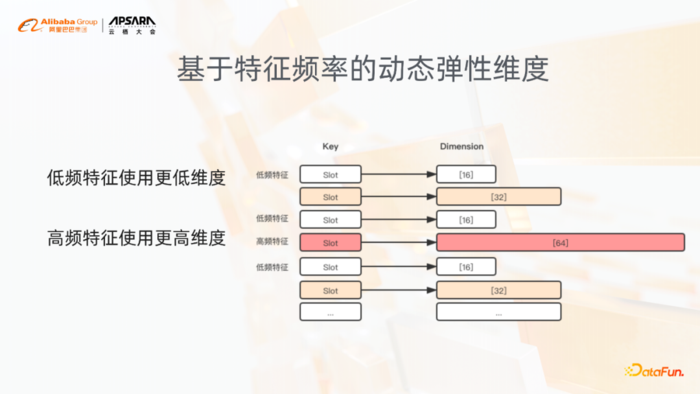
这个功能是在动态弹性特征基础之上,用户在使用的时候也不用配dimension,可以配一个最大可能出现的dimension上限,这样的话动态弹性维度功能会自动根据特征本身出现的频率,自动进行伸缩。
低频的特征像图中表示的就是这种用16位来表达,越高频的特征用更高的维度来表达,这样去解决低频特征,因为它更新的训练的几率、机会比较少,可能出现的这种过拟合问题,当然也是一定程度上提高高频特征本身的表达能力,这样的话,大家也都有一个common sense,就是在我们的稀疏模型里面,高频特征占比通常也是比较少的,但其实通过这个功能也一定程度上能够降低模型的size,在我们的一些场景里边模型size能够降低几倍。
3. 异步训练框架StarServer
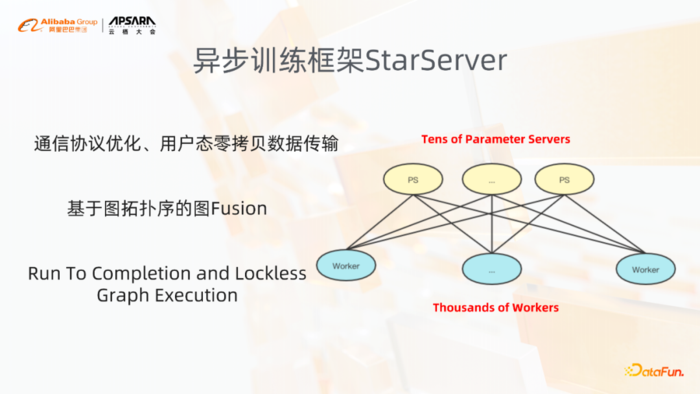
下面讲两个关于分布式训练框架的功能,一个是异步训练框架StarServer。
StarServer主要有四个特点,包括通信方面的优化,通信协议的优化,图层面的优化,以及Runtime执行引擎的优化。
第一个在通信协议上来讲,我们实现了Share Nothing的这种通信协议,并且实现了用户态的纯零拷贝的数据传输。此外我们会基于图的拓扑关系对图进行一些Fusion操作,然后将图做重新的partition。在Runtime,我们会在整个执行引擎的执行方式上进行变化,执行引擎在执行的过程中实现了Run To Completion的执行策略,以及整个图执行过程中的完全的无锁化。
异步训练框架StarServer,它整个支撑的规模是比较大。在超大规模worker的上面存在着过期梯度的问题,DeepRec里面也有一些Optimizer的实现来解决过期梯度的问题。
4. 同步训练框架HybridBackend
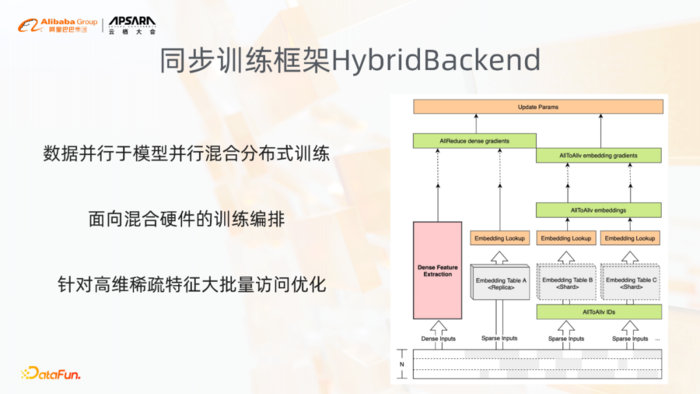
另一个分布式训练框架就是同步训练框架HybridBackend。它是基于GPU实现的一套同步的训练框架。
其有三个特点:
-
数据并行于模型并行混合分布式训练
-
面向混合硬件的训练编排
-
针对高维稀疏特征大批量访问优化
展开讲一下混合并行的这种分布式训练。不同的稀疏特征,比如说ID类型的特征,相对来讲会非常大,对于有些特征,它的特征的量非常少,比如说省份、性别这种类型的特征。不同的特征,它的同步方式是有区别的,就像大的这种稀疏的特征,使用AllToAllv的方式进行同步;对于小size的特征列和稠密参数直接使用AllReduce进行同步梯度。此外会基于GPU的硬件特点,进行训练的编排,而这里其实主要还是基于硬件,GPU底下NVLink以及RDMA本身的硬件的排布,去做同步的方案。
此外,像高维特征的访问的优化,为什么大家逐渐利用GPU来做稀疏模型的训练,其实利用了几点:一个就是GPU的这种高并发,再就是HBM以及NVLink的这种高带宽,其中高维稀疏的批量的访问优化其实就是需要这种高并行、精确的高并发以及HBM的这种高的访存带宽,对于高维稀疏特征的访问优化是非常明显的。
5. Runtime优化-PRMalloc
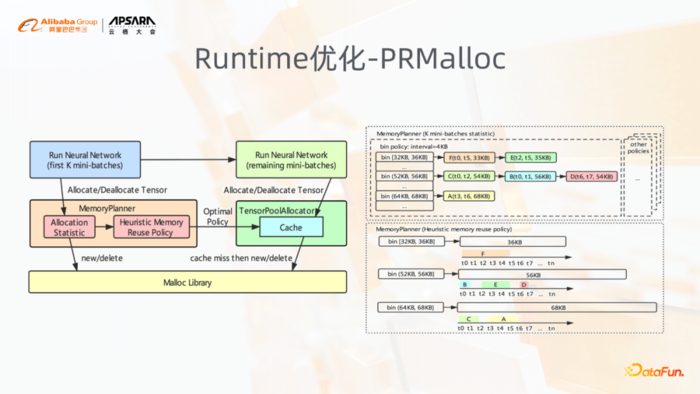
上图是挑选了Runtime优化中的PRMalloc工作,我们针对这种模型训练的一个特点,将模型的训练前面,比如训练过程前面的K轮进行一些统计,通过Malloc的这样一个模块,对内存的分配,包括分配的时间点、分配的大小,统计好分配的时间点和大小后,在K轮结束之后会使用启发式的一些算法规划出一个较优的缓存,而这个缓存会用于K轮之后的内存分配。
整个架构来讲,PRMalloc解决了在稀疏场景里面在访存上存在的一些问题,主要有几个问题,一个问题就是在稀疏场景里边,有大量的小内存的分配,这些小内存分配很可能就是特征的处理,包括一些特征的拼接,或者在做一些交叉特征,这里会存在大量的小内存的分配。同样在模型训练也存在很多大的内存,特别是像后面的一些结构,比如说从embedding层cat起来之后的一些结构里边,可能attention的、RNN的、或者说全连接的,它会有一些大内存的分配。
在这些小内存和大内存的分配上,传统的malloc库,比如jemalloc、tcmalloc,其实并不适用于深度学习的训练。PRMalloc一方面就是解决在小内存分配以及大内存分配上存在的这些问题,其实大家如果是稀疏模型训练,在CPU上有些很明显的特点就是可以使用我们PRMalloc,比如minor perfort比较高,说明有非常多大内存分配行为,这些分配行为源自于tcmalloc或者是jemalloc在大内存分配管理上存在的一些缺陷,导致每次分配后使用触发大量minor pagefault。
6. 图优化-结构化特征
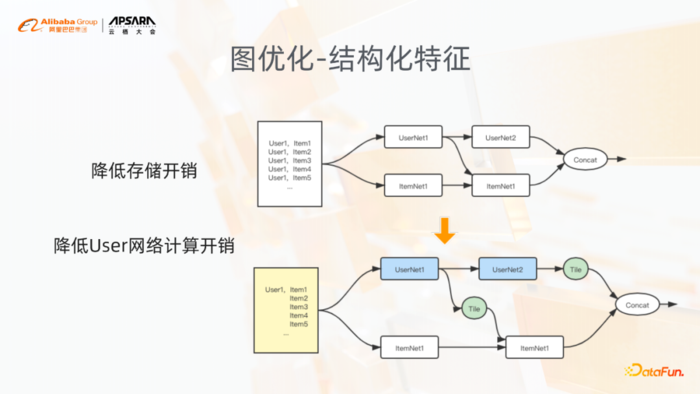
图优化方面,我挑了其中一个相对比较有特点的结构化特征,针对我们样本的一些特点,它包含两个层面的优化,一个就是样本的存储,另一个就是模型的训练性能。
样本存储,大家可以看到我们通常一次曝光,user测的这些特征是一样的,只有item和label会不一样,实际上在存储上面,当我们把user侧和item侧重新做一个存储格式的划分,我们可以存一条user对应多条item以及label,这样在存储上可以节省大量的user侧特征的存储。因为user侧特征存储,特别是用户的行为,它的量会比较大,尤其是随着用户行为序列越来越长,用户特征里面用户行为占比是非常多的。
在图优化层面,当我们把输入变成了一个user对多个item以及多个label的形式之后,user侧的网络其实也会简化,因为user侧网络的输入,它的user侧的特征可能变得很少,这个时候它的计算以及它的embedding lookup都会变得更少,当需要和item侧进行结合的时候,要做tensor的展开。
7. 模型增量导出及加载
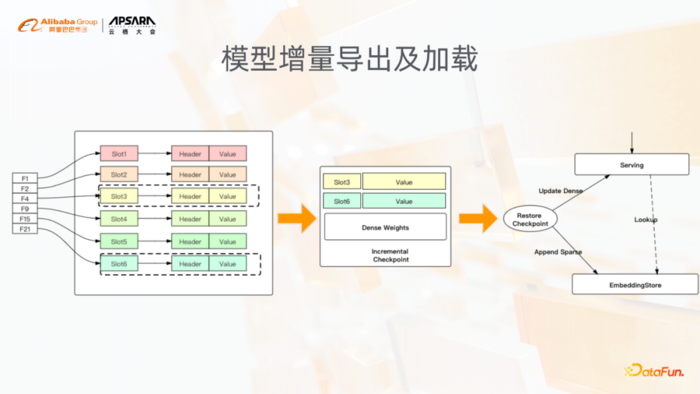
在模型的Serving和导出方面,我们支持模型的增量导出和加载,而这里是针对稀疏模型典型的一个需求,即每隔一段时间都需要去快速产生一个上线的模型,也就是像ODL。在ODL场景下,分钟级别秒级别的模型更新的时候,需要快速产生一个模型,并且这个模型首先要达到上线的需求,其次它的大小也应该是足够小的。增量模型就是记录了在一个时间段内的稀疏参数的变化情况,然后将变化的这些参数导出到模型中,这样增量的模型通常非常小。
8. Embedding多级混合存储
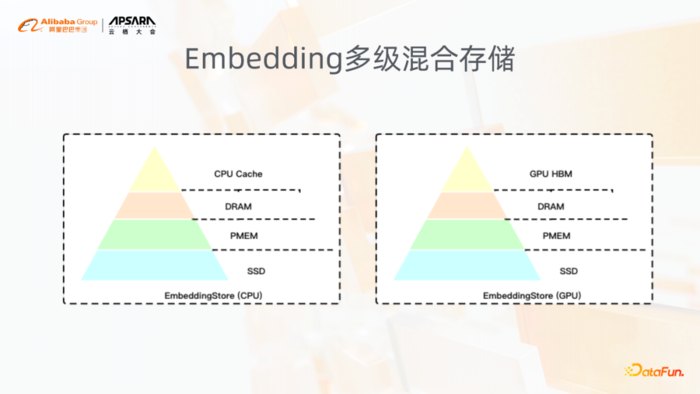
此外,在这种超大的embedding场景下,对于多级混合存储的需求是非常急迫的。因为本身embedding的这些特征,存在很明显的冷热区分。这种明显的冷热区分,可以通过多级混合存储既满足了性能的要求,同时满足了成本的需求。此外这种多级混合存储更好的一点就是它更能够大大地降低对分布式的依赖。
举个最简单的场景,比如说分布式Serving的一个场景,一个大模型的分布式Serving可能会增加很多的网络开销,但是通过多级混合存储去实现一个单节点的Serving,一个大模型通过单节点就可以Serving的话,其实在效率上要提高很多。此外在training阶段也是这样,当使用GPU进行稀疏模型训练的时候,也是需要多级混合存储去支持解决这种在GPU下,算力足够强、稀疏参数又太大的矛盾的问题。在DeepRec内部包括GPU上的多级混合存储,以及CPU上的多级混合存储,我们分四级,包括HBM、DRAM、PMEM以及SSD,这里其中HBM的管理以及PMEM的管理是和英特尔以及英伟达的相关的同学一起合作开发的。
--
03
DeepRec开源
下面我介绍一下DeepRec开源的状态和一些思考。
首先DeepRec在阿里内部已经在最核心的一些业务场景以及大量的稀疏场景下得到了很好的锤炼,并且沉淀了很多对于性能,包括对于模型效果都有提升的一些功能。
我们也希望后面在开源的过程中,能跟更多的公司去合作,去接触到更多的业务场景,把DeepRec用得更广。因为不同的业务场景对于模型的效果、模型的训练,以及他们的样本、模型差异都是非常大的。


现在我们跟英特尔、英伟达已经在DeepRec内部沉淀了非常多的功能,包括像稀疏分子的加速,HugeCTR也已经在DeepRec接入了。包括像GPU的一些OP,GPU的hashtable,以及Runtime优化、图优化算子优化的一些实现,以及软硬件一体化的一些设计,另外在稀疏场景模型训练中,也正在做一些硬件的工作。
总结:
大规模稀疏模型的应用是搜、推、广等多业务领域所面临的重要课题,阿里巴巴DeepRec模型在业界已有训练引擎、框架的基础上探索出了一套行之有效的实践方案,在特征使用、模型训练、线上推理、存储等方面都进行了一定的探索和优化。DeepRec希望在自身开源的过程中与业界伙伴一起更好地解决大规模稀疏模型应用的问题。
--
04
问答环节
Q:目前基于哪个TF的版本?
A:基于TF的1.15,并且加入了NV TF和Intel TF的功能。
Q:维度的动态变化会不会与TF网络层参数不匹配,或无法计算?
A:维度的变化,当Embedding被查出来要送入后面的网络层时,会padding到最高维度,在初始设置时一般会设置一个最高维度,动态维度在后续计算中会统一到一个最高维上。
今天的分享就到这里,谢谢大家。
阅读更多技术干货文章,请关注微信公众号“DataFunTalk”
关于我们:
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请近1000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章500+,百万+阅读,13万+精准粉丝。
注:欢迎转载,转载请留言或私信。

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:阿里巴巴稀疏模型训练引擎-DeepRec - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 