

程序简介
图像语义分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。本文提供了一个可进行自定义数据集训练基于pytorch的deeplabv3+图像分割模型的方法,训练了一个动漫人物分割模型,不过数据集较小,仅供学习使用
程序输入:动漫图片
程序输出:分割好的动漫人物图片
deeplabv3+是一种比较流行的图像语义分割模型,本文经过多次实验,对比了deeplabv3+、pspnet和unet,查看效果后,最终选择了deeplabv3+,下图是程序生成结果


程序/数据集下载

数据集准备
在VOCdevkit/VOC2007/JPEGImages文件夹中,放入原图

在VOCdevkit/VOC2007SegmentationClass文件夹中,放入mask图片

mask图片虽然看起来是全黑色的,但它实际上是单通道的、像素值记录了分类id的图片,它的本质类似于下图,即每个点都被分类,不同数据集转换得到mask图片的方法不同,所以这一步需要自行处理

训练步骤
在voc_annotation.py中,可更换下列参数,其中最值得注意的是RATIO,当这个参数等于[0.1, 0.85]时,如果目标占据整张图片小于10%或者大于85%时,图片会被过滤掉,不被计入数据集
trainval_percent = 1#参与训练和验证的数据集比例
train_percent = 0.8#训练集比例
RATIO = [0.1, 0.85]#目标大小不在这个范围会被过滤掉
运行voc_annotation.py,数据集被分割成训练和验证集

修改train.py下的参数,本文提供的程序只有基于mobilenet主干网络的预训练模型,相比xception,它更小且性能减少不大,适合大多数人的电脑设备,所以我们主要修改的参数主要如下,其中num_classes是加上背景的分类数,比如本文的分类就是背景、动漫人物,所以是2类,其他参数最好不要改
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
Cuda = True
#-------------------------------#
# 训练自己的数据集必须要修改的
# 自己需要的分类个数+1,如2+1
#-------------------------------#
num_classes = 2
运行train.py,可以看到mIOU在一直上升,mIOU可以理解为模型分割部分和正确分割部分的重合程度,是语义分割模型的一个重要指标,最终训练集mIOU为90%,验证集mIOU为84%
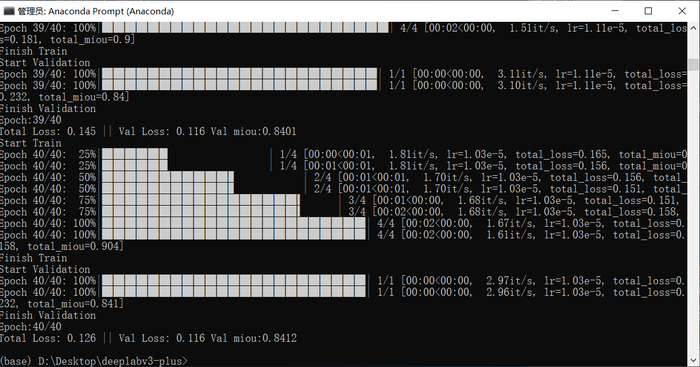
程序会记录loss,并绘图,在logs/loss文件夹可找到

每次迭代,最新模型和最佳模型也会保存在logs文件夹下,last.pth为最新模型,best.pth为最佳模型
预测演示步骤
修改deeplab.py中的参数,除了model_path其他参数保证它跟train.py中的一样就行,如果已经是按本文的数据集进行学习的话,不需要修改,logs/best.pth是训练好的模型,本文会提供下载,如果按照上述步骤自行训练,因为模型和数据集较小,使用3070显卡训练只需要2分钟,就算是用CPU,时间也不会太久
_defaults = {
#----------------------------------------#
# model_path指向logs文件夹下的权值文件
#----------------------------------------#
"model_path" : \'logs/best.pth\',
#----------------------------------------#
# 所需要区分的类的个数+1
#----------------------------------------#
"num_classes" : 2,
#----------------------------------------#
# 所使用的的主干网络:mobilenet、xception
#----------------------------------------#
"backbone" : "mobilenet",
#----------------------------------------#
# 输入图片的大小
#----------------------------------------#
"input_shape" : [400, 400],
#----------------------------------------#
# 下采样的倍数,一般可选的为8和16
# 与训练时设置的一样即可
#----------------------------------------#
"downsample_factor" : 16,
#--------------------------------#
# blend参数用于控制是否
# 让识别结果和原图混合
#--------------------------------#
"blend" : True,
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
"cuda" : True,
}
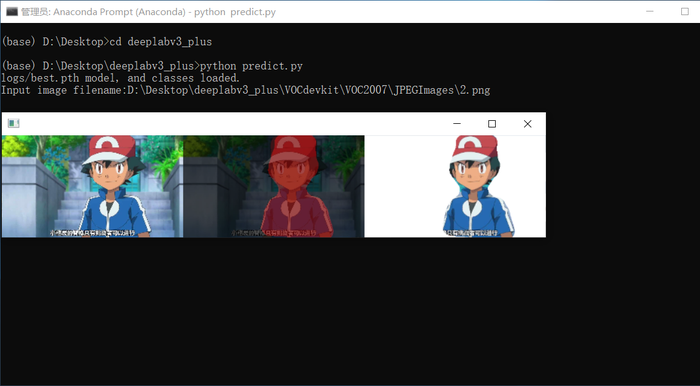
运行predict.py,程序就会提示输入图片,将图片拖入终端回车就能看到图像分割结果

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python调用pytorch实现deeplabv3+图像语义分割——以分割动漫人物为例 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 