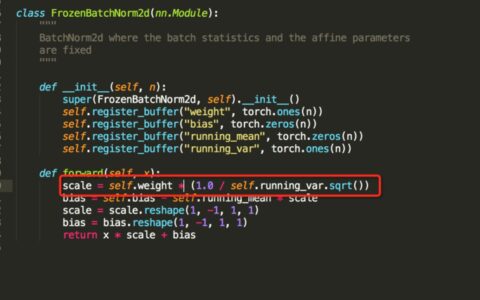
PyTorch多GPU并行运算的实现
在深度学习中,使用多个GPU可以加速模型的训练过程。PyTorch提供了多种方式实现多GPU并行运算,本文将详细介绍其中的两种方法,并提供示例说明。
1. 使用nn.DataParallel实现多GPU并行运算
nn.DataParallel是PyTorch提供的一种简单易用的多GPU并行运算方式。使用nn.DataParallel可以将模型自动划分到多个GPU上,并在每个GPU上运行相同的操作。以下是一个使用nn.DataParallel实现多GPU并行运算的示例代码:
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(128 * 8 * 8, 1024)
self.fc2 = nn.Linear(1024, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.max_pool2d(nn.functional.relu(self.conv2(x)), 2)
x = x.view(-1, 128 * 8 * 8)
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
# 加载数据集
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
# 将模型移动到GPU上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net().to(device)
# 使用nn.DataParallel实现多GPU并行运算
if torch.cuda.device_count() > 1:
net = nn.DataParallel(net)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
# 训练模型
for epoch in range(100):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
在上面的示例代码中,我们首先定义了一个名为Net的类,它继承自nn.Module。然后,我们加载CIFAR-10数据集,并将模型移动到GPU上。接着,我们使用nn.DataParallel实现多GPU并行运算,并定义损失函数和优化器。最后,我们训练模型并输出每个epoch的平均损失。
2. 使用torch.nn.parallel.DistributedDataParallel实现多GPU并行运算
torch.nn.parallel.DistributedDataParallel是PyTorch提供的一种更加灵活的多GPU并行运算方式。使用torch.nn.parallel.DistributedDataParallel可以将模型划分到多个进程中,并在每个进程中运行相同的操作。以下是一个使用torch.nn.parallel.DistributedDataParallel实现多GPU并行运算的示例代码:
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(128 * 8 * 8, 1024)
self.fc2 = nn.Linear(1024, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.max_pool2d(nn.functional.relu(self.conv2(x)), 2)
x = x.view(-1, 128 * 8 * 8)
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
# 定义训练函数
def train(rank, world_size):
# 初始化进程组
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', rank=rank, world_size=world_size)
# 加载数据集
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset, num_replicas=world_size, rank=rank)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=False, num_workers=2, sampler=train_sampler)
# 将模型移动到GPU上
device = torch.device("cuda:%d" % rank)
net = Net().to(device)
# 使用torch.nn.parallel.DistributedDataParallel实现多GPU并行运算
net = nn.parallel.DistributedDataParallel(net, device_ids=[rank])
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
# 训练模型
for epoch in range(100):
running_loss = 0.0
train_sampler.set_epoch(epoch)
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
# 释放进程组
dist.destroy_process_group()
# 启动多个进程进行训练
if __name__ == '__main__':
world_size = torch.cuda.device_count()
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
在上面的示例代码中,我们首先定义了一个名为Net的类,它继承自nn.Module。然后,我们定义了一个名为train的函数,它用于在每个进程中训练模型。在train函数中,我们首先初始化进程组,并加载CIFAR-10数据集。然后,我们将模型移动到当前进程对应的GPU上,并使用torch.nn.parallel.DistributedDataParallel实现多GPU并行运算。接着,我们定义损失函数和优化器,并训练模型。最后,我们释放进程组。在main函数中,我们启动多个进程进行训练。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:pytorch多GPU并行运算的实现 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫