深度学习是什么?
深度学习既指深度神经网络,也指机器学习的其他分支,如深度强化学习。一般来说,它通常指的是深度神经网络。
神经网络是一组算法,大致模仿人脑,旨在识别模式。他们通过一种机器感知,标记或聚类原始的输入来解释感官数据。它们识别的模式是数字的,包含在矢量中。所有现实世界的数据,无论是图像、声音、文本还是时间序列,都必须转换成矢量。
神经网络可以帮助我们聚类和分类。您可以将它们看作是存储和管理数据之上的群集和分类层。它们依据与输入样例之间的相似性,对未标记的数据进行分组。当有足够的标记好的数据集时,它们可以根据这些数据集对未标记的数据进行分类。(更准确地说,神经网络提取的特征被馈送给其他算法进行聚类和分类,所以你可以把深度神经网络看作是大型机器学习应用程序的组成部分,包括强化学习、分类和回归算法。)
“深层”指的是具有多个隐藏层的神经网络。
神经网络的深度允许它构建一个越来越抽象的特征层次结构,每个后续层都充当一个过滤器,过滤越来越多的复杂特征,这些特征结合了前一层的特征。当深度网络学会重构无监督数据时,这种特征层次结构和对数据重要性建模的过滤器会自动创建。由于深度网络可以处理非监督数据,而非监督数据构成了世界上的大部分数据,因此它可以比传统的ML算法更加精确,因为传统的ML算法无法处理非监督数据。也就是说,能够访问更多数据的算法胜出。
深度学习可以将输入映射到输出,然后发现其相关性。
这种方式被称为“通用近似器”,因为它可以学习在任意输入x和任意输出y之间近似函数f(x) = y,假设它们之间存在相关性或因果关系,深度学习可以找到它,从而根据这种因果关系,给定输入后预测出结果。

深度神经网络原理
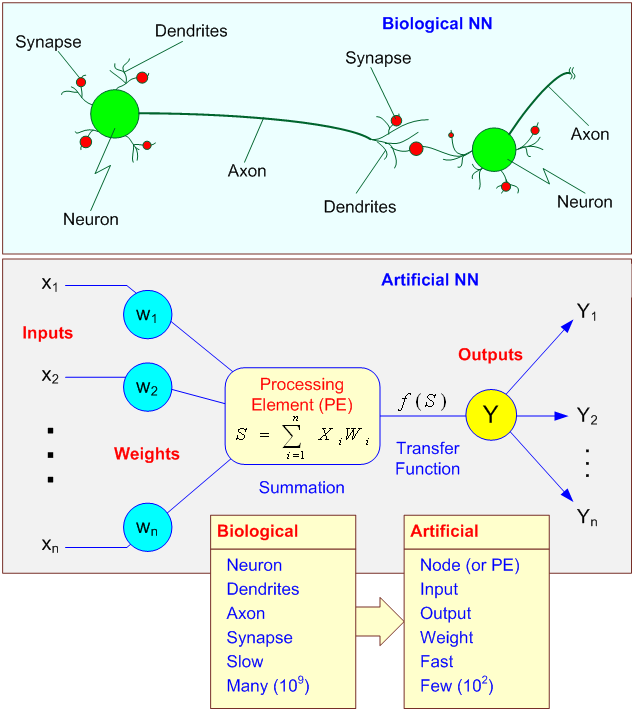
在机器学习和认知科学中,人工神经网络(ann)是一组受生物神经网络(动物的中枢神经系统,特别是大脑)启发的模型,它依赖于大量的输入数据,以此预估未知的事物。
人工神经网络通常表现为相互连接的“神经元”系统,它们在彼此之间交换信息。这些连接具有数字权重,可以根据经验进行调整,使神经网络能够适应输入并具有学习能力。
为什么“深度学习”被称为深度?这是因为人工神经网络的结构。
早在40年前,神经网络只有2层深度,因为在计算上无法构建更大的网络。现在有10层以上的神经网络,甚至100层以上的人工神经网络正在被尝试。
你可以把神经元层层叠加在一起。最低层接收原始数据,如图像、文本、声音等,然后每个神经元存储它们遇到的数据的一些信息。这一层的每一个神经元都将信息发送到下一层的神经元,这些神经元学习下一层数据的更抽象的版本。所以你爬得越高,你学到的抽象特征就越多。你可以在下图中看到有5个层,其中3个是隐藏层。
深度学习能解决什么问题?
深度学习可以解决机器学习必须人工开发特征工程的痛点!
在我们以往的文章中,一直强调一个事实:让机器自我学习,是通往人工智能的必经之路。
“机器学习”正是由此而来。传统的机器学习需要大量人工参与,如果你是一名数据科学家,在使用传统的机器学习方法处理工作时,你大量的时间都会花费在开发特征工程上。
例如,你首先需要将数据转换成计算机能够理解的形式,为此,你会使用R语言或Python或Excel软件来将数据量化,转换成包含样例和特征的行和列的大型数字电子表格。然后你把这些数据输入机器学习算法,它会尝试从这些数据中学习。
这时你主要的工作内容是设计特征,以便改进机器学习模型,但一方面这是一项耗时的任务,一方面,在您训练或改进测试模型之前,您并不知道这些特性的有效性,您就陷入了开发新特性、重建模型、度量结果和重复直到您对结果满意的恶性循环中。
这是一项非常耗时的任务,会占用你大量的时间。而深度学习恰恰可以解决这个问题!
深度学习可以自动提取特征
在深度学习中,人工神经网络自动提取特征,而不是特征工程中的人工提取。仅从这一点来看,就能为您节省大量时间。
以图像作为输入为例。传统的机器学习需要我们获取一张图像并手工计算颜色分布、图像直方图、不同颜色计数等特征。
但在深度学习中,我们只需要在人工神经网络中输入原始图像即可。
近几年,人工神经网络在处理图像方面已经证明了它们的价值,现在它们正被应用于所有其他类型的数据集,如原始的文本、数字等。这有助于数据科学家摒弃低效率的工作内容,更专注于构建深度学习算法。
深度学习依赖大数据
很快,特征工程可能会过时,但深度学习算法将需要大量数据来输入我们的模型。幸运的是,我们现在有20年前没有的大数据来源——facebook、twitter、维基百科、古腾堡计划等。然而,瓶颈仍然在于清理并将这些数据处理成机器学习模型所需的格式。在不久的将来,将有越来越多的大数据供公众消费。
可以从哪里学习深度学习的知识?
深度学习领域的知识,大多数都是开源的。Tensorflow、Torch、keras、Big Sur硬件、DIGITS和Caffe都是大规模深度学习项目中的一部分。
在学术研究中,有很多论文都有算法的源代码,以及他们的新发现。Arvix.org已经开放了超过100万篇关于深度学习的论文。
通过这些途径,您可以深入学习深度学习相关的知识,并保证您的知识一直在流行趋势的最前沿。
学习深度学习是否需要计算机专业知识?
学习深度学习并不需要严格的计算机专业知识。
如果你学过任意的数据科学相关的语言,如“R”或“Python”,或者电子表格,如“Excel”或任何其他基础编程,并学习过“STEM”,那么你就精通深入学习。
深度学习的优势是什么?
我们已经解释过的一个优点是,您不必提前弄清楚功能细节。另一个优点是我们可以使用相同的神经网络方法来解决许多不同的问题,如支持向量机、线性分类器、回归、贝叶斯、决策树、聚类和关联规则。它具有容错性和伸缩性。许多感知任务都是在cnn的帮助下完成的。
如何将使用特征工程的经典ML与使用CNN的深度学习进行比较?通过这些图片就能看出来。
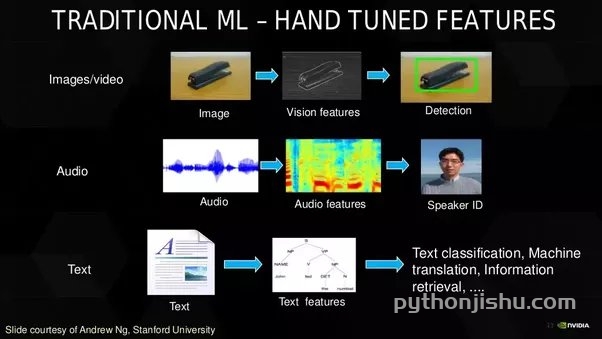

从这些图片中,你可以看到深度学习在生活各个方面的广泛适用性。我认为这足以激励你开始深度学习,并在数据科学和机器学习技能方面表现出色。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:什么是深度学习?它能解决什么问题? - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

评论列表(1条)
[…] 推荐阅读:《什么是深度学习?它能解决什么问题?》 […]