
摘要:智能把控大数据量查询,防患系统奔溃于未然。
本文分享自华为云社区《拒绝“爆雷”!GaussDB(for MySQL)新上线了这个功能》,作者:GaussDB 数据库。
什么是最大读取行
一直以来,大数据量查询是数据库DBA们调优的重点,DBA们通常十八般武艺轮番上阵以期提升大数据查询的性能:例如分库分表、给表增加索引、设定合理的WHERE查询条件、限定单次查询的条数……
然而,DBA再厉害,应用程序千千万,写代码的程序员万码奔腾,大数据量的查询像地雷,不定什么时候就爆了。比如隐藏在某段代码里的查询,因为一个新手程序员的经验不足,查询代码写得欠佳,没有WHERE子句或缺少索引引发了不必要的多行读取,甚至全表扫描,给服务器带来了过度的压力,导致业务执行缓慢,甚至最后服务器OOM崩溃。
为了避免这种“爆雷”,GaussDB(for MySQL)近期上线了最大读取行特性。优化器产生执行计划后,如果优化器预估的读取行数超过了所设置的最大读取行阈值,则自动中止查询,将雷的导火索切断。
这种机制的优点在于:执行计划阶段就对查询进行了干预,而不是语句开始执行后在执行过程中进行中断。既杜绝了劣质查询对服务器和业务运行造成的风险,又大大节省了时间和资源。
如何设置最大读取行
在GaussDB(for MySQL)中,设置rds_max_row_read,指定查询允许读取的最大行数。GaussDB(for MySQL)收到查询指令,执行查询之前,会对查询要读取的行数进行估计。当估值超过所设置的最大读取行时,将中止查询,即查询没有机会运行,提前规避不必要的资源消耗。
下面是一份测试数据,说明了开启最大读取行前后的差异。
假设表t1有4M大小的行,当开发人员或应用程序尝试运行以下查询时,运行需要7分钟。
mysql> SELECT * FROM t1;
WHERE子句的缺失致使需要全表扫描,查询耗时长。对于更大的表,这类查询将需要更多的耗时,使服务器消耗更多资源,查询耗时甚至可能高达数小时。
最大读取行特性的使用,可以节省宝贵的时间和资源。比如假设将最大读取行数指定为1000000:
mysql> set rds_max_row_read =1000000; Query OK, 0 rows affected (0.00 sec)
修改后,重新运行不含WHERE子句的查询,收到了读取行超限的提示,查询被停止。
mysql> SELECT * FROM t1;
ERROR HY000: Expected number of read rows exceeds the maximum allowed (see @@rds_max_row_read)
通过最大读取行,相当于拥有了一个工具,DBA或者软件工程师根据业务情况可以自如设置和调整限制规则,保证业务正常运行的同时,限制次优查询,避免性能异常。
适用范围
适用于SELECT、CREATE SELECT和INSERT SELECT。
功能开启
默认情况下,该功能是禁用的,只有当rds_max_row_read设置了值时,该功能才会被激活。
为了功能的稳定,避免无心的错误设置对业务造成不必要的影响,rds_max_row_read做了最低值限制,不允许用户设置比最低值更低的值。
实现原理
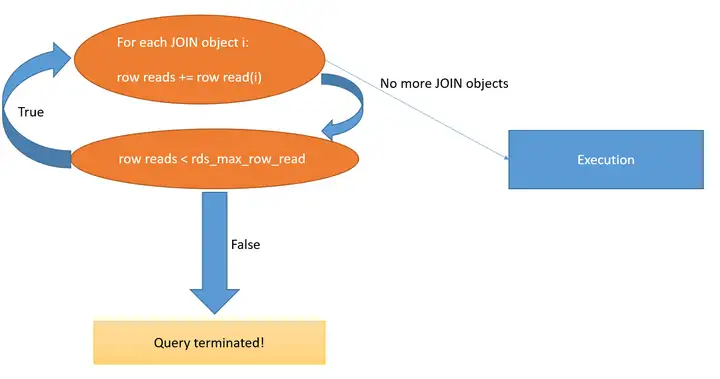
GaussDB(for MySQL)通过遍历每个查询块并聚合各查询块的贡献来整体评估查询的读取行数:也就是对各join对象的读取行数评估后累加。
如果在累加评估过程中的某一刻,估计值超过了所设置的限制,查询将被终止。
对于关联子查询,评估办法为:评估子查询的读取行数,然后乘以查询被执行的次数。
需要特别说明的是,对每个JOIN对象的估计是执行计划预估返回的行数,可能与真实执行返回的行数有偏差。这虽然是一个相对简单的评估模型,但是我们坚信其具有足够的鲁棒性。
对于复杂查询,GaussDB(for MySQL)还通过optimizer trace提供了更多信息以帮助您确定优化器做决策的原因及如何优化查询。
示例
示例1
mysql> EXPLAIN format=tree SELECT * FROM table_1, table_2; +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPLAIN | +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | -> Inner hash join (no condition) (cost=6.50 rows=54) -> Table scan on table_1 (cost=0.19 rows=9) -> Hash -> Table scan on table_2 (cost=0.85 rows=6) | +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SET rds_max_row_read =20; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM table_1, table_2; ERROR 1888 (HY000): The expected number of read rows exceeds the allowed maximum (see @@rds_max_row_read)
查询读取的行太多,我们尝试在optimizer trace的帮助下寻找原因:
SET optimizer_trace="enabled=on"; SELECT * from table_1, table_2; SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
在optimizer trace中,可以找到:
{ "Max_row_read": { "select#": 1, "current_estimate_of_rows": 54, "rows_contributed_by_this_query_block": 54 } }
这表示此查询中的唯一查询块,行读取数为54。
执行计划中的这个评估有多准确呢?
执行如下查询查看语句实际被执行的次数:
mysql> show status like "handler_read_rnd_next"; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | Handler_read_rnd_next | 17 | +----------------------------+-------+ 1 rows in set (0.00 sec)
handler_read_rnd_next显示实际上的读取是17行,而不是54行。
这个17是怎么来的呢?
这是一个哈希连接:
-遍历整张表时,左表有9行数据+1行额外行。
-右表有6行+1行额外行。
优化器中会预估返回读取行,例如,54。在这个示例中,它并没有很好地猜测到返回的行数,它高估了行读取的数量。在大多数情况下,读取行数的估计不够精确,但可以肯定的是,它是足够稳健的,能达到相应的目的。
示例2
创建例表t1:
mysql> CREATE TABLE t1(a INT);
在表中填充1536行数据后。将rds_max_row_read设置为500,进行以下测试查询:
mysql> SELECT * FROM t1 WHERE a>6; ERROR HY000: Expected number of read rows exceeds the maximum allowed (see @@rds_max_row_read)
在optimizer trac的帮助下,可以看到优化器估计的读取行数是512行,因此查询被终止。如果在a字段上添加索引(这是一件明智的事情),同一查询的估计读取行数是1,查询检测顺利通过。
这个简单的示例说明:最大读取行能帮助您编写更加优质的查询语句。
结论
最大读取行特性针对读取过多行的查询,识别和过滤出效率低下的查询。用户可以为读取行数设置阈值,超过该阈值则终止查询。为了识别此类查询,GaussDB(for MySQL)在优化器中进行了读取总行数的粗略估计。当查询终止时,可以检查optimizer trace,从中收集线索,以帮助重写更高效的查询。
简而言之,最大读取行为用户提供了一个工具,使他们可以更充分地利用手上的资源。
原文链接:https://www.cnblogs.com/huaweiyun/p/17268336.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:拒绝“爆雷”!GaussDB(for MySQL)新上线了这个功能 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 