本来就想着是对自己第一次跑yolov5的coco128的一个记录,没想到现在准备总结一下的时候,一方面是继续学习了一些,另一方面是学长的一些任务的要求,挖出了更多的东西,所以把名字改为了“从入门到出土“。
00 GitHub访问加速
首先我们要把yolov5框架从GitHub上拉下来,国内如果要快速访问GitHub的话呢,需要把Github的相关域名写入Hosts文件。
00-1 修改hosts的原理
-
hosts文件原理
hosts文件是一个用于储存计算机网络中各节点信息的计算机文件。这个文件负责将主机名映射到相应的IP地址。hosts文件通常用于补充或取代网络中DNS的功能。
和DNS不同的是,计算机的用户可以直接对hosts文件进行控制。
关于DNS解析,我在CTF的学习中有所记录
https://www.cnblogs.com/Roboduster/p/15575207.html 00-03浏览器。
-
作用过程
当我们在浏览器中输入一个需要登录的网址时,系统会先检查系自己的Hosts文件中是否有这个域名和IP的映射关系。
如果有,则直接访问这个IP地址指定的网络位置;
如果没有, 再向已知的DNS(Domain Name System,域名系统)服务器提出域名解析请求。
也就是说Hosts的IP解析优先级比DNS解析要高。
-
我们把github相关IP写入hosts,就能在DNS解析之前通过hosts文件的IP解析访问我们想要访问的域名。
00-2 修改hosts文件
了解了原理,其实就很简单,我们在域名解析网站上搜github相关的IP,找到ttl值小的写入hosts即可。
我们选用http://tool.chinaz.com/dns/这个网站。
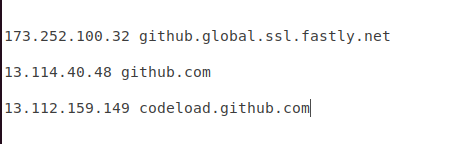
搜索以下域名
1 github.global.ssl.fastly.net 2 3 github.com 4 5 codeload.github.com
找到比较小的ttl值的ip,放入hosts文件:
1 sudo gedit /etc/hosts

1 # 然后更新配置 2 sudo /etc/init.d/networking restart
注意ip每隔一段时间会变动,所以每隔一段时间需要更新。
01 YOLOv5框架获取
1 # 用git获取源码 在上一步配置好的情况下 会很快 2 git clone https://github.com/ultralytics/yolov5 3 # 进入yolov5文件夹下 4 cd yolov5 5 # 依据包里的requirements.txt安装 需要的库 6 # 优先考虑清华源下载 不然可能会很慢 7 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 8 9 # 这种办法在windows下也可以,通过pycharm打开终端进行命令行的输入
02 测试 / 预测
02-0 目录框架
对于初学者而言,把YOLOv5跑起来的难点之一就是目录结构,这里我简单介绍以下我的项目的目录结构:
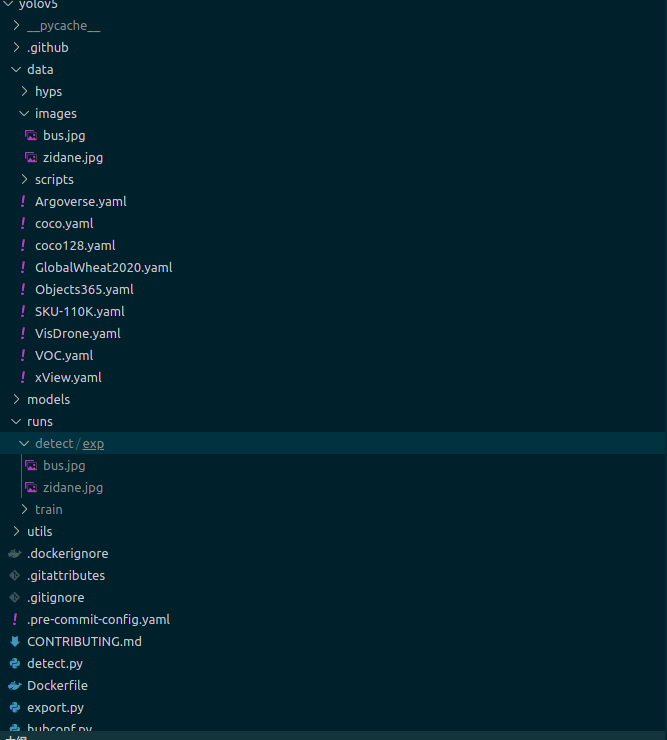
再来重点看一下yolov5目录下的data和runs目录,这两个目录下的内容前者将成为yolo框架的输入,后者将作为输出。
02-1 对于图片的detect
在yolov5的目录下(画重点)执行:
1 # 运行detect.py 2 python detect.py 3 # 或者 4 python detect.py --source data/images/ --weights ./yolov5s.pt 5 # 解释: 使用权重文件为yolov5s.pt的模型,使用data/images下的图片作为推理图片 6 7 #或者 8 python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/ 9 # 解释:使用权重文件为yolov5s.pt的模型,推理图片为640(pixels),最小置信度为0.25,使用yolov5文件夹中data/images文件夹下的文件作为处理图片(默认保存到yolov5/runs/detect/exp文件夹下)
实际上官网给出的命令参数为:
python detect.py --source 0 # webcam img.jpg # image video.mp4 # video文件 path/ # directory path/*.jpg # 所有jpg文件 'https://youtu.be/Zgi9g1ksQHc' #指定链接 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream #备注 # rtsp等是各种传输协议,将摄像头等设备连接到电脑,通过一些方式获得这种链接,作为参数成为输入,进而可以实现实时检测。 # 除了source参数,还有weights,用于指定不同的权重模型,具体模型在04部分
执行完毕后输出:
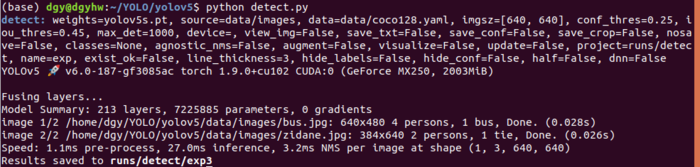
这里我已经跑过一次了,所以终端里输出的东西少了很多。下图是我保存的当时跑的截图,图片里是正在下载5s权重文件。
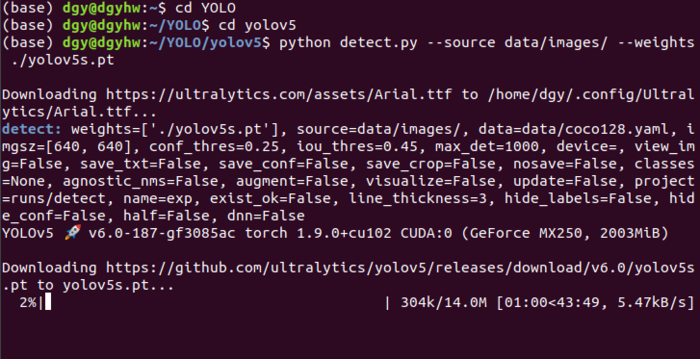
按照终端最后的提示,结果被保存在runs/detect/exp3,此外source源下的两张图片中的目标情况也被终端列出,比如bus.jpg中是4个人、1个bus。
我们在上面提到的目录下就可以找到检测之后的结果
ps:
在windows下用pycharm或是在ubuntu下使用pycharm图形化界面的话,其实也可以使用pycharm里的终端进行命令行的输入。
此外我们可以在编辑器里查看detect.py的源码,里面在parse_opt()函数里设定了一些参数,比如源码中默认指定了yolov5s.pt作为权重文件......这也是为什么直接python detect.py可行的原因。这点后面再讲;
(使用yolov5的不同模型会出现不同的效果,这点后面04部分会讲解)
(注意我在里使用的是yolov5的v6.0分支的代码)
阅读这些源码我的感受之一就是python学的还不够,用法真挺多的。
02-2 对于视频的detect
对图片的检测其实没多大意思,我们可以看一看对于视频的检测。
我们可以在yolov5所在的文件夹YOLO里下载视频,这里我切换到了实验室的服务器上来做这件事情,因为服务器快且容量大。
服务器的目录架构如图:
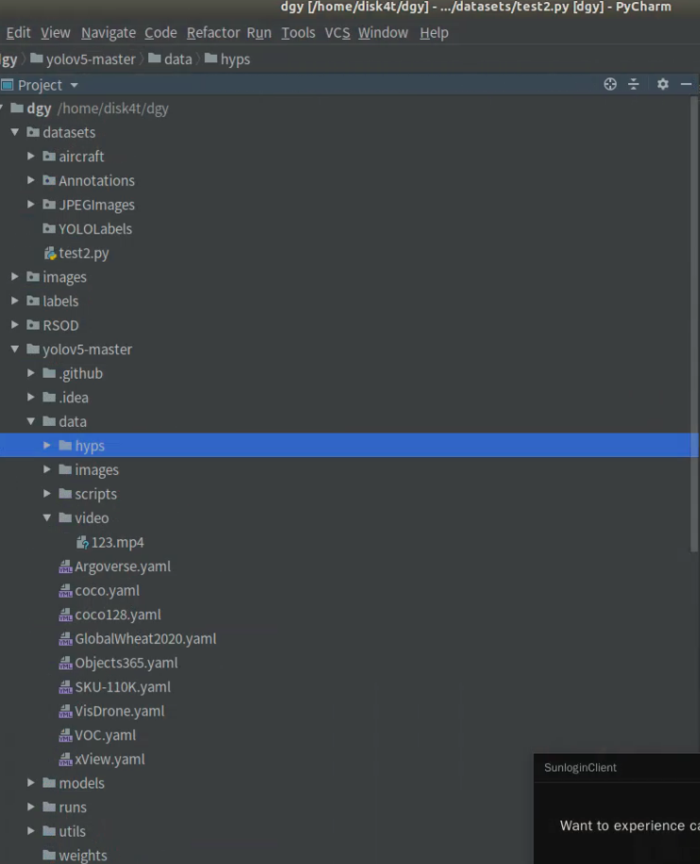
我在yolov5-master下的data里新建一个文件夹video,然后把我们下载的视频放进来。不会下载视频??这个我回头总结一下,有一个命令行神器是annie,当然也可以在b站解析工具上下载并另存为。这里放一个链接:
https://www.zhihu.com/question/290690588/answer/2005192819
这里我把放在yolov5-master/data/video下:
在yolov5-master(相当于我电脑上的yolov5)文件夹下打开终端
1 python detect.py --source data/video/123.mp4 2 3 # 实际上就是上面官方教程中的参数模型的套用 4 5 # 同样,这个参数可以在源码的对应位置进行修改
然后开始跑:对每一帧图片进行检测
程序结果保存在runs/detect/exp6
我们看一看效果。附一张截图:
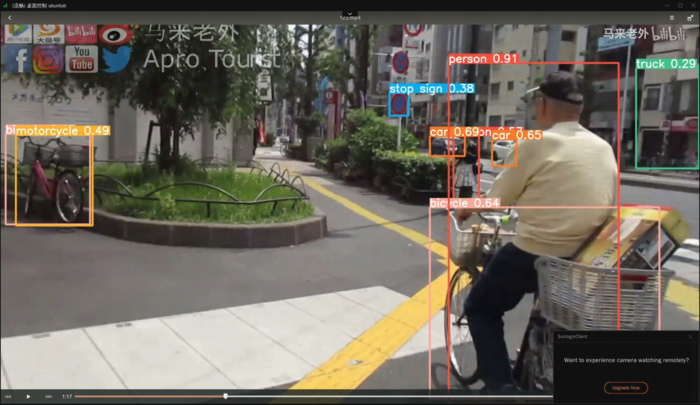
感觉海星,左侧有一辆自行车被认成了摩托车hhhh。
02-3 实时检测的detect
更有意义的莫过于实时检测了,yolov5的优势就正是实时检测的准确性。这个待我下次研究研究,目前尚未实现,涉及将摄像头信息转换成相关协议的流。
不过连接电脑本地的摄像头还是很容易实现的。
1 python detect.py --source 0
看见摄像头视频流的实时检测结果:
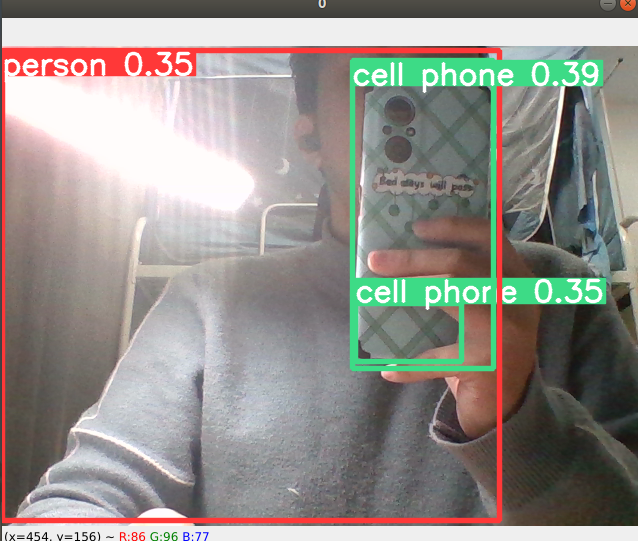
但是检测效果不太好,可能是寝室里光的影响,也有可能是只出现了半张人像,以及手完美遮挡了部分手机。
同时一个手机出现了两个同名框,如果细究的话是一些参数对于这种情景下默认设置的不够合适。
02-4 一些参数的理解
02-4-1 --img 640
这个640是指像素,是指传入yolo框架用于处理的图片大小,需注意我们传出的图片和原图片大小是一致的。可知这里这个参数设置了我们用yolo处理的图片的规模。
最后会对画出的框框进行再次缩放,标在原图片上。
02-4-2 --conf 0.25
这个参数的意思就是当某个区域的置信度>0.25的时候,程序才相信这是一个目标,才会把它作为目标框出来。
02-4-3 --iou 0.45
当多个框有重合时,我们需要有一个阀值来控制:大于某个阀值的重合框就应该算为一个框,而小于就算作两个框。
iou的计算公式就是交并比:两框交/两框并。默认阀值0.45。
02-4-4 --view-img
1 # 示例 2 python detect.py --view-img
这样可以显示正在检测的图片,这个就可以应用在视频的检测上,我们对视频进行这个参数的设置,就可以实时看到视频每一帧处理的情况。
1 # 具体参数 2 python detect.py --view-img --source data/video/123.mp4
02-4-5 --save-txt
把每一张源文件图片的目标检测结果保存为txt文件。
02-4-6 --classes 0
对于目标检测结果进行筛选,比如--classes 0就是只保留第一个类别的目标,其他类别的目标都不框出来。
02-4-7 --agnostic-nms | --augment
对数据进行增强的两种命令,使用它们会使我们的监测结果的值更优(即标注框的数字)。
02-4-8 --project | --name | --exist-ok
-
--project 把得到的结果存放到什么目录下;默认为runs/detect
-
--name 把结果保存在目录里的哪个位置;默认exp。
-
--exist-ok 打开这个参数(即为True),即每次训练的结果exp不再默认增加1,会保存在--name指定的位置。
03 训练
03-1 /本地训练
03-1-1 准备数据集
事实上因为coco128是官方例程,所以如果没有下载128,运行train.py会自动下载。
但是为了我们的经验更有普适性,我们把128下载到YOLO目录下,与yolov5同级,我在这里命名为datasets。大家可以通过我的vscode项目框架看一下这个结构:
03-1-2 运行train.py
(本地电脑)在YOLO/yolov5目录下,打开终端
python train.py --img 160 --batch 16 --cfg ./models/yolov5s.yaml --weights ''
注意这里的--img参数默认是640,而我改小为160,是因为640我的显存总是不够:RuntimeError: CUDA out of memory.
我调用nvidia-smi可以看出确实是显存不够,而不是N卡调用比例的问题。所以我决定更改命令参数,牺牲一些性能,先把模型跑通。当然推荐的做法是修改batch-size,把改动得小一点。
PS:
关于batch-size的设置问题,根据交流获知的情况,3060的显卡用的是8,普通显卡可以用4试一下。
0118补充:
下图也可以看出我的小破gpu显存极小,1G都不到..
所以拥有一个服务器的使用权,多是一件美事阿
下面是运行的截图:有一点点了解为啥别称炼丹了。
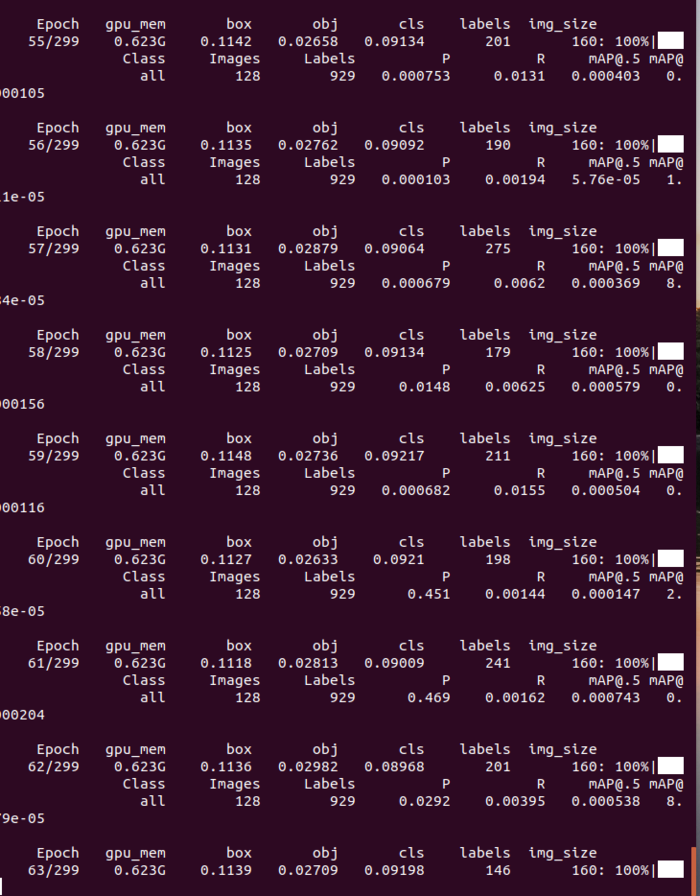
图中的Epoch299是训练轮次,这个可以在源码中见到这个参数。
记忆里跑了大概有快一个小时。结果出来了。放在YOLO/yolov5/runs/train/exp8里
03-1-3 一些分析
我们看看我们的run文件夹下都产生了点什么东西。
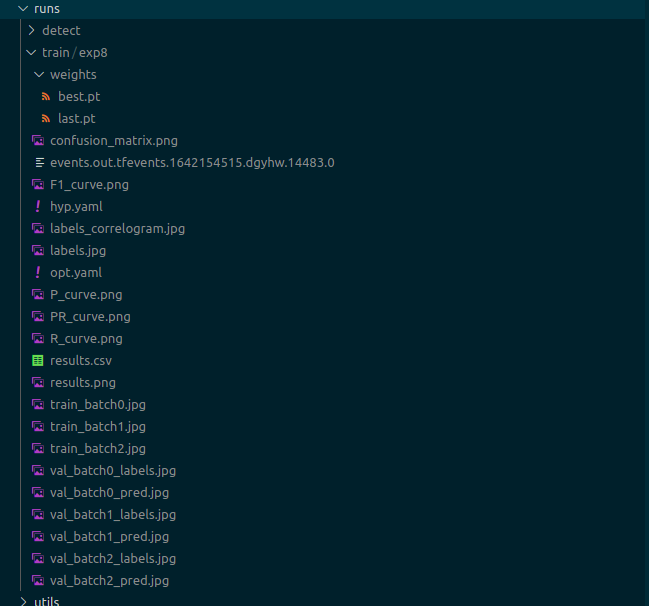
best.pt是选取的最优训练轮次的网络模型参数;同理last.pt是最后一个训练的轮次的网络模型参数。
hpy.yaml是训练过程中的一些超参数,一些图表图片是对目标分布、训练效果的描述。
result.csv是训练过程的一个记录。
最后的train_batchxxxx.jpg是训练图片的拼接,我们在这里可以看到训练图片的结果。
03-1-4 一些参数
A --weights | --cfg | --data
-
--weights
前面提到过,是选择使用哪个已有模型来初始化前面提到过的参数,有5s、5x、5n等等,当然如果我们有自己的模型(比如上一部分提到的best.pt),可以在命令行中,把这个模型的路径跟在后面,用自己的模型来赋值训练过程。
我们的训练一般上是 从头训练,所以这个参数一般初始化为空。
在程序中:
parser.add_argument('--weights', type=str, default='', help='initial weights path') -
--cfg
config的缩写,是关于模型的配置,存放在models/.yaml里,相当于C语言的开局define,为每个模型固定了一些参数,指定这些会固定训练的结构。
例如:(与上一个参数结合)
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')如果与上一个参数结合来看,就是我们使用yolov5s的模型,训练的初始化参数我们使用程序中给出的初始参数,不使用已经训练好的参数作为初始参数。
-
--data
指定数据集,比如源程序是coco128数据集,就要引入它的设定参数文件:
default=ROOT / 'data/coco128.yaml',
B --hyp | --epochs | batch-size | img-size
-
--hyp 使用哪一超参数进行初始化,我的文件夹下没有,但是刚才训练完成之后是产生了一个超参数文本,这个对于不同的数据集不同的训练自然是不一样的。
-
--epochs 训练轮次/迭代次数
-
--batch-size 把多少数据打包成一个batch送进网络中
-
--img-size 设置图片默认大小
C --rect | --resume
-
--rect 原本对于一个图片的处理,程序会默认填充为正方形,那么对于长条形的图片来说,填充的无效信息就很多,使用这个参数就可以对图片进行最小填充,加快推理过程。
-
--resume 管理是否以最近训练得到的模型为基础进行继续的训练。默认是False,但是要让其生效,要指定模型的位置。比如指定
runs/train/exp/weights/last.pt会接着迭代之前的过程。
D --nosave | --notest | --noautoanchor
-
--nosave 默认为false,如果设置为true,就只保留最后一次的迭代结果
-
--notest 只对最后一个epoch进行测试
-
--noautoanchor 锚点,目标检测模型包括有无锚点两种类型。这个参数默认开启(true)
E --evolve | --cache | --image-weights
-
--evolve 对参数进行进化,是寻找最优参数的一个方式。
-
--cache 是否对图片进行缓存,进行更好的训练,默认未开启。
-
--image-weights 对训练效果不佳的图片加一些权重
03-1-5 授人以渔 | 读代码的一些技巧
A 源码跟踪
如果对于一个参数进行分析,我们时常需要对一个参数在程序中起到的作用进行追踪。
可以选中一个变量,然后Ctrl + F,pycharm和Vscode都会出现一个框,点击框右侧的向上向下箭头,就能实现自动跳转。
参数传入一个模块函数,我们可以右键查看它的相关定义、引用、快速浏览等等,以了解具体的实现过程。
也可以按住Ctrl,点击这个函数,也会自动跳转代码到源码相关处。
B 浏览查询
看似困难实际上方便的一个做法是(比如YOLOv5),就在它的GIthub上的issues(https://github.com/ultralytics/yolov5/issues)进行查询,在closed板块查看相关话题,查看比较权威且经得起考验的回答。
03-2 /云端GPU
我是有本地GPU的,不过电脑是便携本,GPU配置不高,显存只有2G,所以高度依赖实验室的服务器,所以也想了解一下云端GPU的事情。
但是我现在的ubuntu空间不多了,所以不想下载Google来访问Colab(Colab本身也有不便之处),所以这件事情就先搁置,因为有实验室的服务器,暂时也用不着。可以回头再探索,先做事情要紧。
04 不同模型(models)对比
现在github上的预训练模型有如下这些(Github主页上也有):
| Model | size (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| 640 | 28.4 | 46.0 | 45 | 6.3 | 0.6 | 1.9 | 4.5 | |
| 640 | 37.2 | 56.0 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | |
| 640 | 45.2 | 63.9 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | |
| 640 | 48.8 | 67.2 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | |
| 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | |
| 1280 | 34.0 | 50.7 | 153 | 8.1 | 2.1 | 3.2 | 4.6 | |
| 1280 | 44.5 | 63.0 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | |
| 1280 | 51.0 | 69.0 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | |
| 1280 | 53.6 | 71.6 | 1784 | 15.8 | 10.5 | 76.7 | 111.4 | |
| 1280 1536 | 54.7 55.4 | 72.4 72.3 | 3136 - | 26.2 |
可见越往下,模型越复杂,花费时间会相对较多,但是效果相对会比较好,表格里面右侧就是一些指标,可以看出效果会好一些。

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:计算机视觉3-> yolov5目标检测1 |从入门到出土 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 