循环神经网络(RNN)是一种用于处理序列数据的人工神经网络,序列数据是相互依赖的(有限或无限)数据流,比如时间序列数据、信息性的字符串、对话等。
长短时记忆网络(LSTM)是一类特殊的循环神经网络,具有学习长时依赖关系的能力,是目前最常用的循环神经网络。
注意: 关于循环神经网络的介绍,可参考我们的教程深度学习 – 循环神经网络(RNN)。
我们的例子是训练一个LSTM模型,训练时模型会学习一段短文,完成训练后,模型可以在输入一个短句后,预测接下来的单词。
数据集
数据集是一段短文,《伊索寓言》中的老鼠给猫挂铃铛的故事:
long ago , the mice had a general council to consider what measures they could take to outwit their common enemy , the cat . some said this , and some said that but at last a young mouse got up and said he had a proposal to make , which he thought would meet the case . you will all agree , said he , that our chief danger consists in the sly and treacherous manner in which the enemy approaches us . now , if we could receive some signal of her approach , we could easily escape from her . i venture , therefore , to propose that a small bell be procured , and attached by a ribbon round the neck of the cat . by this means we should always know when she was about , and could easily retire while she was in the neighborhood . this proposal met with general applause , until an old mouse got up and said that is all very well , but who is to bell the cat ? the mice looked at one another and nobody spoke . then the old mouse said it is easy to propose impossible remedies .
这篇短文有112个不重复的符号,单词和标点符号都被认为是符号。
训练
如果我们向LSTM输入3个正确排序的符号,和一个标签符号,模型最终将学会正确预测下一个符号(图1)。
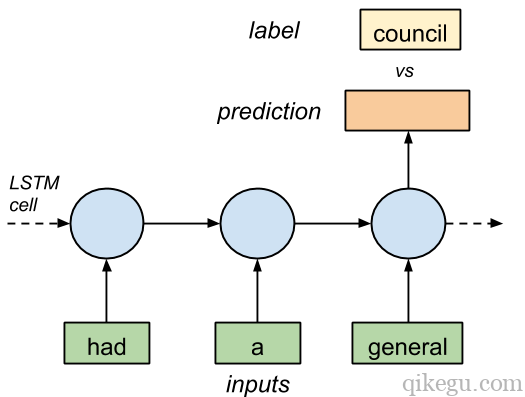

图1. 具有三个输入和一个输出的LSTM单元。
技术上来说,LSTM只能理解数字。因此,需要对上面的短文作一些处理,每个不重复的单词和标点都用数字代替,总共有112个不重复的符号。
我们将创建2个字典,一个可以从单词/标点映射到数字,另一个可以从数字映射到单词/标点(反向字典)。例如,上面的文本中有112个独特的符号,第一个字典包含以下条目[ “,” : 0 ] [ “the” : 1 ], …, [ “council” : 37 ],…,[ “spoke” : 111 ]。同时构建一个反向字典,将用于解码LSTM的输出。
LSTM输入输出都是数字,LSTM应该输出一个符号数字代号,用来表示符号。例如,如果输出是37,表示单词”council”。
但是,LSTM输出的实际上是一个112个元素的向量,每个元素值表示对应符号的概率,概率最大的符号就是最终符号(图2)。
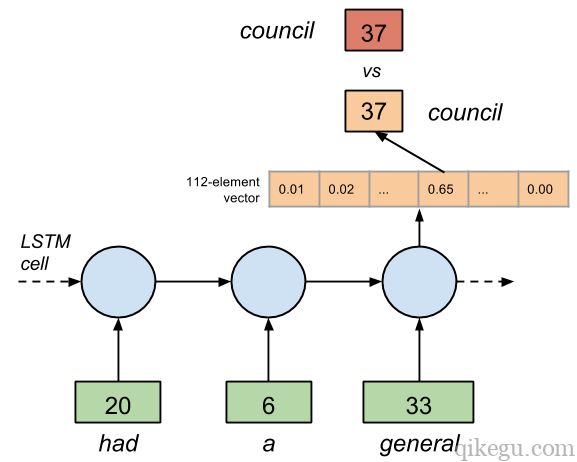
图2. 每个输入符号都被替换成数字代号。输出是一个表示本次输出各符号概率的向量,读取概率最大的符号代号,结合反向字典,最终查出符号。
实现
下面是实现代码:
from __future__ import print_function import numpy as np import tensorflow as tf from tensorflow.contrib import rnn import random import collections import time start_time = time.time() def elapsed(sec): if sec<60: return str(sec) + " sec" elif sec<(60*60): return str(sec/60) + " min" else: return str(sec/(60*60)) + " hr" # 日志目录 logs_path = './train/rnn_words' writer = tf.summary.FileWriter(logs_path) # 训练用的短文 training_file = 'belling_the_cat.txt' # 读取短文函数 def read_data(fname): with open(fname) as f: content = f.readlines() content = [x.strip() for x in content] content = [word for i in range(len(content)) for word in content[i].split()] content = np.array(content) return content training_data = read_data(training_file) print("Loaded training data...") # 短文符号->数字字典,数字->短文符号反向字典 def build_dataset(words): count = collections.Counter(words).most_common() dictionary = dict() for word, _ in count: dictionary[word] = len(dictionary) reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return dictionary, reverse_dictionary # 创建字典与反向字典 dictionary, reverse_dictionary = build_dataset(training_data) # 符号数量 vocab_size = len(dictionary) # 参数 learning_rate = 0.001 training_iters = 50000 display_step = 1000 n_input = 3 # RNN cell中的神经数量 n_hidden = 512 # tf Graph input x = tf.placeholder("float", [None, n_input, 1]) y = tf.placeholder("float", [None, vocab_size]) # RNN 输出节点的 weights 与 biases weights = { 'out': tf.Variable(tf.random_normal([n_hidden, vocab_size])) } biases = { 'out': tf.Variable(tf.random_normal([vocab_size])) } def RNN(x, weights, biases): # reshape 到 [-1, n_input] x = tf.reshape(x, [-1, n_input]) # Generate a n_input-element sequence of inputs # (eg. [had] [a] [general] -> [20] [6] [33]) x = tf.split(x,n_input,1) # 2-layer LSTM, each layer has n_hidden units. # Average Accuracy= 95.20% at 50k iter rnn_cell = rnn.MultiRNNCell([rnn.BasicLSTMCell(n_hidden),rnn.BasicLSTMCell(n_hidden)]) # 1-layer LSTM with n_hidden units but with lower accuracy. # Average Accuracy= 90.60% 50k iter # Uncomment line below to test but comment out the 2-layer rnn.MultiRNNCell above # rnn_cell = rnn.BasicLSTMCell(n_hidden) # generate prediction outputs, states = rnn.static_rnn(rnn_cell, x, dtype=tf.float32) # there are n_input outputs but # we only want the last output return tf.matmul(outputs[-1], weights['out']) + biases['out'] pred = RNN(x, weights, biases) # 计算损失 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) # 优化 optimizer = tf.train.RMSPropOptimizer(learning_rate=learning_rate).minimize(cost) # 模型评估 correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 初始化变量 init = tf.global_variables_initializer() # 执行图 with tf.Session() as session: session.run(init) step = 0 offset = random.randint(0,n_input+1) end_offset = n_input + 1 acc_total = 0 loss_total = 0 writer.add_graph(session.graph) while step < training_iters: # Generate a minibatch. Add some randomness on selection process. if offset > (len(training_data)-end_offset): offset = random.randint(0, n_input+1) # 准备样本数据和标签 symbols_in_keys = [ [dictionary[ str(training_data[i])]] for i in range(offset, offset+n_input) ] symbols_in_keys = np.reshape(np.array(symbols_in_keys), [-1, n_input, 1]) symbols_out_onehot = np.zeros([vocab_size], dtype=float) symbols_out_onehot[dictionary[str(training_data[offset+n_input])]] = 1.0 symbols_out_onehot = np.reshape(symbols_out_onehot,[1,-1]) # 执行optimizer, accuracy, cost, pred _, acc, loss, onehot_pred = session.run([optimizer, accuracy, cost, pred], feed_dict={x: symbols_in_keys, y: symbols_out_onehot}) loss_total += loss acc_total += acc # 每过一定步数(display_step),打印信息 if (step+1) % display_step == 0: print("Iter= " + str(step+1) + ", Average Loss= " + "{:.6f}".format(loss_total/display_step) + ", Average Accuracy= " + "{:.2f}%".format(100*acc_total/display_step)) acc_total = 0 loss_total = 0 symbols_in = [training_data[i] for i in range(offset, offset + n_input)] symbols_out = training_data[offset + n_input] symbols_out_pred = reverse_dictionary[int(tf.argmax(onehot_pred, 1).eval())] print("%s - [%s] vs [%s]" % (symbols_in,symbols_out,symbols_out_pred)) # 递增step, offset step += 1 offset += (n_input+1) # 训练完成,打印输出 print("Optimization Finished!") print("Elapsed time: ", elapsed(time.time() - start_time)) print("Run on command line.") print("ttensorboard --logdir=%s" % (logs_path)) print("Point your web browser to: http://localhost:6006/") # 测试:接受用户输入,生成输出 while True: prompt = "%s words: " % n_input sentence = input(prompt) sentence = sentence.strip() words = sentence.split(' ') if len(words) != n_input: continue try: symbols_in_keys = [dictionary[str(words[i])] for i in range(len(words))] # 连续进行32次 for i in range(32): keys = np.reshape(np.array(symbols_in_keys), [-1, n_input, 1]) onehot_pred = session.run(pred, feed_dict={x: keys}) onehot_pred_index = int(tf.argmax(onehot_pred, 1).eval()) sentence = "%s %s" % (sentence,reverse_dictionary[onehot_pred_index]) symbols_in_keys = symbols_in_keys[1:] symbols_in_keys.append(onehot_pred_index) print(sentence) except: print("Word not in dictionary")
输出
Iter= 1000, Average Loss= 4.428141, Average Accuracy= 5.10% ['nobody', 'spoke', '.'] - [then] vs [then] Iter= 2000, Average Loss= 2.937925, Average Accuracy= 17.60% ['?', 'the', 'mice'] - [looked] vs [looked] Iter= 3000, Average Loss= 2.401870, Average Accuracy= 31.00% ['an', 'old', 'mouse'] - [got] vs [got] Iter= 4000, Average Loss= 2.079050, Average Accuracy= 46.10% ['when', 'she', 'was'] - [about] vs [about] Iter= 5000, Average Loss= 1.756826, Average Accuracy= 52.40% ['a', 'small', 'bell'] - [be] vs [be] Iter= 6000, Average Loss= 1.620517, Average Accuracy= 57.80% ['from', 'her', '.'] - [i] vs [cat] Iter= 7000, Average Loss= 1.410994, Average Accuracy= 61.50% ['some', 'signal', 'of'] - [her] vs [be] Iter= 8000, Average Loss= 1.340336, Average Accuracy= 65.60% ['enemy', 'approaches', 'us'] - [.] vs [,] ... Iter= 48000, Average Loss= 0.447481, Average Accuracy= 90.60% ['general', 'council', 'to'] - [consider] vs [consider] Iter= 49000, Average Loss= 0.527762, Average Accuracy= 89.30% ['ago', ',', 'the'] - [mice] vs [mice] Iter= 50000, Average Loss= 0.375872, Average Accuracy= 91.50% ['spoke', '.', 'then'] - [the] vs [the] Optimization Finished! Elapsed time: 31.482173871994018 min Run on command line. tensorboard --logdir=./train/rnn_words Point your web browser to: http://localhost:6006/ 3 words: the mice had the mice had a general council to said that is all a consider what measures they enemy , the cat . by this means we should always know when when when when when when when

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:人工智能深度学习入门练习之(28)TensorFlow – 例子:循环神经网络(RNN) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 