
大家看了之后,可以点一波关注或者推荐一下,以后我也会尽心尽力地写出好的文章和大家分享。
本文先导:在我们平时看NBA的时候,可能我们只关心球员是否能把球打进,而不太关心这个球的颜色,品牌,只要有3D效果,看到球员扣篮的动作就可以了,比如下图:


如果我们直接对篮球照片进行几百万像素的处理,会有几千维甚至几万维的数据要计算,计算量很大。而往往我们只需要大概勾勒出篮球的大概形状就可以描述问题,所以必须对此类数据降维,这样会使处理数据更加轻松。这个在人脸识别中必须要降维,因为我们在做特征提取的时候几万维的数据很难全部有效计算,PCA技术作为四大降维技术之一对于此类问题有很好的处理效果。
一 前瞻知识
向量的内积,矩阵的意义,矩阵特征值,正交基,方差,协方差。
二 降维的概念
降维通俗地说,就是把高维数据降成低维数据。因为对于机器学习算法,处理上万级别维数的数据是家常便饭的事情,但是处理是能处理,这会带来巨大的时间开销。影响算法的时间复杂度,降维就是在减少维数的前提下,尽量保证数据的完整性。这里需要说明的是,降维不是单纯的删除掉某些特征值,而是把高维数据通过一定的矩阵变换映射到低维空间,现在我们举一个例子。对于A(3,4),B(5,6),C(3,5)D(-1,2)四个点,如下图所示:

我们现在要把他投影在一维坐标上,我想大部分人都是想投影在x轴上,如图:

等等,不是应该四个点吗,怎么映射变成了三个点了,如果现实是这样,那岂不是丢失很多数据?那么我们的目标现在就是找到一条直线,让这四个点都能在投影在这个直线上,那么数据就不会缺少,而且让各个点之间的距离最大化。这个有点像我之前说的LDA,链接:
http://www.cnblogs.com/xiaohuahua108/p/5985826.html
思路如下:

要想让各个点映射到直线之后各个点之间的距离最大,我们不妨用方差来表示。
各个点的方差之和为:

其中ai表示各个点的向量表示,u表示各个点的平均坐标的向量表示,一般我们在处理pca的时候,会先减去平均值,得到下面式子:
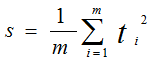
现在的优化目标就是找到一条直线,使二维上的点投影到这条直线上,使这些点在这条直线上的方差最大。
但是在三维甚至超维的空间中,我们先找到一条直线,让方差最大,这是第一个方向,接着我们找第二个方向,但是如果还是找方差最大的话,那么这个方向是不是和第一个方向重合了?这样一直找下去,所有点都集中在一起了,岂不是乱套了?所以我们希望这两个方向正交,这样每次找一条直线,都跟原来的方向正交这样就可以让数据最大化的显示在低维空间了。。
三PCA降维方法详解
1、主成分分析的数学模型及几何意义
设有n个样品,每个样品观测p项指标(变量):X1,X2, ….Xp,得到原始
数据资料阵:

其中

用数据矩阵X的p个向量(即p个指标向量)X1,X2,…Xp作线性组合(即
综合指标向量)为:
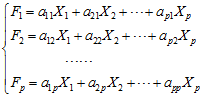
简写成

其中,Xi是n维向量,所以Fi也是n维向量。上述方程组要求:
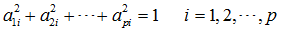
且系数aij由下列原则决定:
(1) Fi与Fj(i≠j,i,j=1,…p)不相关;
(2) F1是X1 ,X2,…,Xp的一切线性组合(系数满足上述方程组)中方差最大的,F2与F1不相关的X1 ,X2,…,Xp一切线性组合中方差最大的,…,Fp是与F1,F2,…,Fp-1都不相关的X1 ,X2,…,Xp的一切线性组合中方差最大的。
如何求满足上述要求的方程组的系数aij呢?下一节将会看到每个方程式中的系数向量(a1i,a2i, …,api),i=1,2, …,p不是别的而恰好是X的协差阵∑的特征值所对应的特征向量,也就是说,数学上可以证明使Var(F1)达到最大,这个最大值是在协方差阵∑的第一个特征值所对应特征向量处达到。依此类推使Var(Fp)达到最大值是在协方差阵∑的第p个特征值所对应特征向量处达到。
主成分的几何意义
从代数学观点看主成分就是p个变量X1 ,X2,…,Xp的一些特殊的线性组合,而在几何上这些线性组合正是把X1 ,X2,…,Xp构成的坐标系旋转产生的新坐标系,新坐标轴使之通过样品变差最大的方向(或说具有最大的样品方差)。下面以最简单的二元正态变量来说明主成分的几何意义。
设有n个样品,每个样品有p个变量记为X1 ,X2,…,Xp,它们的综合变量记为F1,F2,…,Fp 。当p=2时,原变量是X1,X2,它们有下图的相关关系:
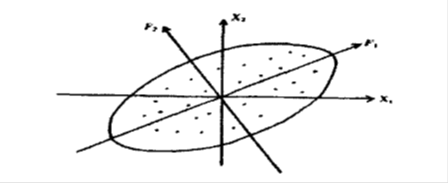
主成分的意义
对于二元正态分布变量,n个分散的点大致形成为一个椭圆,若在椭圆长轴方向取坐标轴F1,在短轴方向聚F2,这相当于在平面上作一个坐标变换,即按逆时针方向旋转θ角度,根据旋转轴变换公式新老坐标之间有关系:
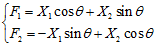
矩阵表示为:

显然UT=U-1且是正交矩阵,即UTU=I。
从上图还容易看出二维平面上的n个点的波动(可用方差表示)大部分可以归结为在F1轴上的波动,而在F2轴上的波动是较小的。如果上图的椭圆是相当扁平的,那么我们可以只考虑F1方向上的波动,忽略F2方向的波动。这样一来,二维可以降为一维了,只取第一个综合变量F1即可。而F1是椭圆的长轴。一般情况,p个变量组成p维空间,n个样品就是p维空间的n个点,对p元正态分布变量来说,找主成分的问题就是找P维空间中椭球体的主轴问题。
2、主成分分析的推导
在下面推导过程中,要用到线性代数中的两个定理:
定理一若A是p*p阶实对称阵,则一定可以找到正交阵U使
 ,其中λ1,λ2,…,λp是A的特征根。
,其中λ1,λ2,…,λp是A的特征根。
定理二若上述矩阵A的特征根所对应的单位特征向量为u1,u2,…,up令
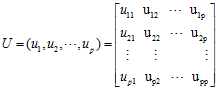
则实对称A 属于不同特征根所对应的特征向量是正交的,即
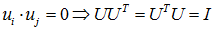
设 ,其中a=(a1,a2,…,ap)T,X=(X1,X2,…,Xp)T,求主成分就是寻找X的线性函数aTX使相应得方差尽可能地大,即使
,其中a=(a1,a2,…,ap)T,X=(X1,X2,…,Xp)T,求主成分就是寻找X的线性函数aTX使相应得方差尽可能地大,即使

达到最大值,且aTa=1。
设协方差矩阵∑的特征根为l1,l2,…,lp,不妨假设l1³l2³ …³lp>0,相应的单位特征向量为u1, u2,…, up。令
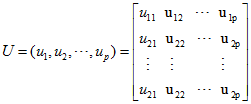
由前面线性代数定理可知:UTU=UUT=I,且
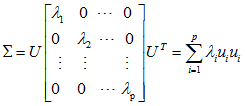
因此

所以
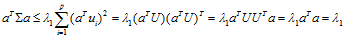
而且,当a=u1时有

因此,a=u1使Var(aTX)=aT∑a达到最大值,且
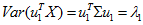
同理
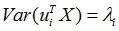
而且
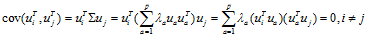
上述推导表明:X1,X2,…,Xp的主成分就是以E的特征向量为系数的线性组合,它们互不相关,其方差为∑的特征根。
由于∑的特征根l1³l2³ …³lp>0,所以有VarF1³ VarF2³ …³VarFp>0。了解这一点也就可以明白为什么主成分的名次是按特征根取值大小的顺序排列的。
在解决实际问题时,一般不是取p个主成分,而是根据累计贡献率的大小取前k个。称第一主成分的贡献率为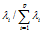 ,由于有,所以。因此第一主成分的贡献率就是第一主成分的方差在全部方差中的比值。这个值越大,表明第一主成分综合X1,X2,…,Xp信息的力越强。
,由于有,所以。因此第一主成分的贡献率就是第一主成分的方差在全部方差中的比值。这个值越大,表明第一主成分综合X1,X2,…,Xp信息的力越强。
前两个主成分的累计贡献率定义为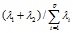 ,前k个主成分的累计贡献率定义为
,前k个主成分的累计贡献率定义为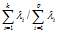 。如果前k个主成分的贡献率达到85%,表明取前 k个主成分包含了全部测量指标所具有的信息,这样既减少了变量的个数又便于对实际问题进行分析和研究。
。如果前k个主成分的贡献率达到85%,表明取前 k个主成分包含了全部测量指标所具有的信息,这样既减少了变量的个数又便于对实际问题进行分析和研究。
3、主成分分析的计算步骤
设x = ( x1 , x2 , ⋯, xn) T为n 维随机矢量,则PCA具体计算步骤如下:
(1) 将原始观察数据组成样本矩阵X ,每一列为一个观察样本x ,每一行代表一维数据。
(2) 计算样本的协方差矩阵:

(3) 计算协方差矩阵Cx的特征值λi及相应特征向量ui ,其中i = 1 ,2 , ⋯, n。
(4) 将特征值按由大到小顺序排列,并按照下式计算前m 个主元的累积贡献率:
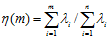
累积贡献率用于衡量新生成分量对原始数据的信息保存程度,通常要求其大于85%即可。
(5) 取前m 个较大特征值对应的特征向量构成变换矩阵TT:
TT= ( u1 , u2 , ⋯, um ) m < n
(6) 通过Y= TX 计算前m 个主成分,达到降低维数的目的。
四 代码实现
1、python 2.7代码实现
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
def loadDataSet(fileName,delim=\'\t\'):
fr=open(fileName)
stringArr=[line.strip().split(delim)for line in fr.readlines()]
dataArr=[map(float,line )for line in stringArr]
return mat(dataArr)
def pca(dataMat,topNfeat=9999999):
meanVals=mean(dataMat,axis=0)
meanRemoved=dataMat-meanVals
covMat=cov(meanRemoved,rowvar=0)
eigvals,eigVects=linalg.eig(mat(covMat))
eigValInd=argsort(eigvals)
eigValInd=eigValInd[:-(topNfeat+1):-1]
redEigVects=eigVects[:,eigValInd]
lowDDataMat=meanRemoved*redEigVects
reconMat=(lowDDataMat*redEigVects.T)+meanVals
return lowDDataMat,reconMat
def display():
import PCA
dataMat=PCA.loadDataSet(\'testSet.txt\')
lowDmat,reconMat=PCA.pca(dataMat,1)
print shape(lowDmat)
print dataMat
print reconMat
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],marker=\'^\',s=90)
ax.scatter(reconMat[:, 0].flatten().A[0], reconMat[:, 1].flatten().A[0], marker=\'o\', s=50,c=\'red\')
plt.show()
if __name__==\'__main__\':
d=loadDataSet("testSet.txt")
f=pca(d)
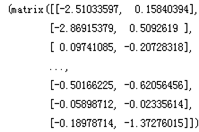
print f
上面是python 的代码实现,经过上面的推导说明大概大家都能看得懂。
实验效果图如下:
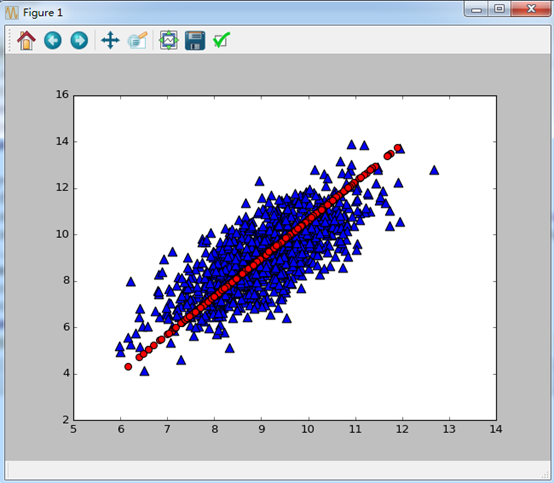
实验结果如下:
2、matlab代码实现
E=load(\'H:\operate\PCA\testSet.txt\');
covE=cov(E\'); %EΪÔʼ¾ØÕ󣬶ÔE½øÐÐÖ÷³É·Ö·ÖÎö·¨
[v,d]=eig(covE);
%%%%%%%%%%%%%%%%%%%%5
V_eig = v;
temp = sum(d);
D_eig = temp;
[m,n]=size(v);
for i=1:n
V_eig(:,i) = v(:,n-i+1);
end
[m,n]=size(temp);
for i=1:n
D_eig(:,i) = temp(:,n-i+1);
end
D_eig = D_eig\';
V=V_eig(:,1:4);%È¡Ç°Èý¸öÖ÷³É·Ö
V=V\';
T=V;
结果:

五 PCA的优缺点
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
六 说明
由于今天和女朋友吵架,把女朋友惹生气了。我心情也不是很好,在匆忙之中完成这篇博客,有什么错误地方还请大家指正。么么哒,爱你们的小花。
只想在这里和我漂亮可爱善良的女朋友说一句,我爱你。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:机器学习笔记—-四大降维方法之PCA(内带python及matlab实现) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 