

Stable Diffusion 图生图功能是Stable Diffusion中一个强大的图像生成和编辑功能,它能够通过随机过程将一张图像转换为另一张具有不同风格和特征的图像。
在本篇Stable Diffusion 图生图教学中,我将带领你探索这一强大的图像生成和编辑技术。img2img图改图功能以其高质量的图像生成、风格转换和编辑能力受到广泛关注。你将学会如何有效地使用Stable Diffusion 图生图功能来满足自己的图像创作和编辑需求。无论是专业人士还是初学者,本教学会为你提供实用的知识和技巧,在图像处理领域更上一层楼。
Stable Diffusion AI绘画有哪些有价值的应用?
Stable Diffusion在图像生成、风格转换和图像编辑等领域具有广泛的应用,有相当大的应用价值。以下是针对这些领域的具体应用说明:
1.图像元素替换
使用Stable Diffusion生成图像,可以根据指定的条件和约束生成高质量的图像。它可以用于创建合成图像、生成特定主题的图像,例如人脸、风景或动物等,或者生成独特风格的艺术作品。通过合理调整相关参数,可以生成具有不同细节、颜色和风格的图像。
以下图为例,左边是用prompts生出的原图,中间与右边是透过图生图功能,创作出同一个主角,不一样的背景、发型、服装。在文章接下来的部分,我会提供详细教学。

2.图像风格转换
Stable Diffusion还可以实现风格转换,将一张图像的风格应用到另一张图像上。例如,可以将梵高的星空风格应用到一张风景照片上,使该风景照片呈现出独特的艺术风格。通过调整参数,可以控制风格转换的程度和效果,实现不同程度的风格融合。
3.图像编辑
Stable Diffusion在图像编辑方面也具有很大的潜力。它可以用于图像修复、图像去噪、对比度增强、图像分割等任务。利用遮罩功能,可以针对图像的特定区域进行编辑,例如修复受损区域、去除水印或背景替换。同时,通过调整降噪强度、CFG缩放因子等参数,可以实现不同程度的图像编辑效果。
因此,Stable Diffusion在图像生成、风格转换和图像编辑等领域也具有广泛的应用和价值。
接下来我们重点学习Stable Diffusion的图生图功能,在此之前,我们先了解图生图的应用场景有哪些:
Stable Diffusion 图生图的应用场景
Stable Diffusion的图生图功能是一种强大的图像生成和编辑技术,它可以通过一个随机过程将一张图像转换为另一张图像。利用这一功能,用户可以根据需求生成新的图像或对现有图像进行编辑,例如替换图片背景或更改人物服装。
这个功能非常适合大量替换图片背景或人物服装的场景。通过使用适当的遮罩,用户可以选择保留图像的某些部分,例如人物或物体,同时替换其他部分,如背景或服装。此外,通过调整相关参数,用户可以控制生成图像的细节程度和风格,实现最佳的视觉效果。
Stable Diffusion 图生图应用场景
根据图生图的强大功能,在以下场景中可以发挥更大的价值:
- 广告业:在广告设计中,可以使用Stable Diffusion 图生图功能为产品或品牌打造不同风格的视觉形象,例如替换广告背景,更改人物服装等,以满足不同市场需求。
- 电商平台:电商平台可以使用Stable Diffusion 图生图功能对产品图片进行批量编辑,例如替换背景、更改颜色等,以提高产品在线展示的吸引力。
- 视频后期制作:Stable Diffusion 图生图功能可以应用于影片后期制作,例如替换场景背景、更改角色服装等,以实现更高品质的视觉效果。
- 社交媒体:用户可以使用Stable Diffusion 图生图功能对个人照片进行编辑,例如替换背景、更改服装等,以创建具有个性化风格的社交媒体图片。
- 艺术创作:艺术家可以使用Stable Diffusion 图生图功能将自己的作品转换成不同风格,并尝试新的创作理念和技巧。
总而言之,Stable Diffusion 图生图功能在图像生成和编辑方面具有很高的应用价值,尤其适合大量替换图片背景或人物服装的。
以下就是本篇将用来手把手教学的案例,从换背景到换服装,到整个图片风格换掉,一次学会。完成这过程只要15分钟!

Stable Diffusion img2img(图生图)功能参数
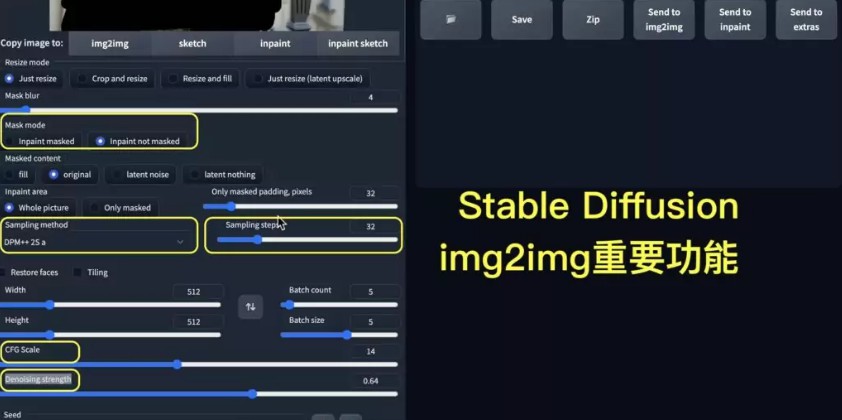
在进入手把手教学之前,先看看图生图功能种各种参数代表的涵义,这样一会实际创作时才不会摸不着头脑。接下来,我将为您解释图生图功能中的各个参数。
我们根据图中的顺序依次解释参数的涵义:
Mask mode(Mask遮罩)
遮罩是一个二值图像,它可以用于标示要保留的原始图像区域和需要生成或变换的区域。在遮罩中,使用inpaint masked表示圈选起来是要进行修改的区域;inpaint not masked则表示圈选部分是不要修改的区域。
简单来说,你想替换图片中哪些部分,用inpaint masked 圈起来就行,或者用inpaint not masked把不需要替换的部分圈住,一样的效果。
Sampling steps(采样步数)
与文生图功能一样,采样步数指的是在Stable Diffusion过程中使用的采样步数。随着采样步数的增加,图像生成的过程将更加细致,生成的图像质量可能更高。然而,过多的采样步数可能导致计算时间过长。
Sampling method(采样方法)
采样方法是指在Stable Diffusion过程中所使用的采样方式,通常我都选DPM++ 2S a Karras或是DPM++ 2S a。
一般来说,有两种主要的采样方法:Metropolis-Hastings (MH) 和Hamiltonian Monte Carlo (HMC)。MH是一个随机采样过程,而HMC则使用梯度信息来引导采样过程。选择不同的采样方法可能会影响生成图像的质量和计算时间。
CFG scale(缩放因子)
CFG缩放因子是一个用于控制图像生成过程中的细节程度的参数。当CFG scale 缩放因子较大时,生成的图像将具有更多你在提词关键字中的要求;相反,当CFG scale 缩放因子较小,生成的图像将更为简单,可能不会用到所有你指定的元素,但好处是可能整体画面比较协调。适当选择CFG缩放因子可以使生成的图像在保持细节的同时,避免出现噪点或过度渲染的现象。
Denoising strength(降噪强度)
降噪强度(Denoising strength)是Stable Diffusion 图生图功能中的一个重要参数,它用于控制生成图像的降噪程度,可以理解为让ai进行自由想像的程度。接下来我们了解下降噪强度的影响以及如何选择合适的降噪强度的方法。
降噪强度会影响哪些方面?
- 降噪强度对生成图像的维持原始图像或大幅改变原始图像,在一定程度上有很大影响;增加降噪强度可以使生成的图像更加具有想像力,换句话说就是让ai依照Stable Diffusion prompt关键字进行判断,可能会为图片带来大幅改动,也可能会损失图片原有细节。
- 适当选择降噪强度,建议0.3~0.5之间,可以在保持原图像细节,减少意外发生。不过在实际应用中,你需要根据生成图像的具体需求以及原始图像的特性来调整这些参数,以实现最佳的生成效果。
Stable Diffusion 图生图如何选择合适的降噪强度
选择合适的降噪强度取决于用户对生成图像的具体需求。以下是一些建议:
- 如果希望保留原始图像的细节,同时只对图像进行轻度修改,可以选择较低的降噪强度。
- 如果用户希望生成的图像具有较高变化度,并且对原始细节保留的要求不高,可以选择较高的降噪强度。
- 在某些情况下,用户可能需要在细节保留和平滑度之间达到平衡,此时可以尝试多个降噪强度值,并根据实际效果选择最佳参数。
选择合适的降噪强度是实现高质量图像生成的关键。通过根据用户需求和原始图像特性选择合适的降噪强度,用户可以在保留原图细节的同时,减少变化和不必要的纹理出现。
手把手 Stable Diffusion img2img(图生图)详细教程
接下来我将详细教大家通过Stable Diffusion的图生图功能,替换原始图像的背景、衣服。
以下教程需要时间大概: 15 分钟。
总结
从上述案例,我说明并展示了Stable Diffusion img2img功能的强大性能和优势,它具有广泛的应用,例如图像生成、风格转换和图像编辑。通过灵活使用Stable Diffusion img2img功能,你也可以创建高质量的图像,并其应用于各种场景,如广告、电商、影片制作和艺术创作等。
记得根据需求调整参数以实现最佳生成效果。你可以通过调整遮罩、采样步数、采样方法、CFG缩放因子和降噪强度等参数,来实现不同程度的图像编辑和风格转换。选择合适的参数值可以确保图像具有更高的清晰度和细节保留。
通过实际应用,你可以更好地理解Stable Diffusion img2img功能的潜力,并将其应用于自己的创作和编辑需求。在这个过程中,读者将能够发现新的创作灵感,并提高自己在图像处理领域的技能。
Stable Diffusion img2img(图生图功能)常见问题QA
什么是Denoising strength降噪强度,它如何影响图像生成,以及如何选择合适的降噪强度?
Denoising strength是Stable Diffusion img2img功能中的一个重要参数,用于控制生成图像的降噪程度,它可以理解为让AI进行想像的程度。降噪强度对生成图像的维持原始或大幅改变具有很大影响。增加降噪强度可以使生成的图像更具想像力,让AI依照Stable Diffusion关键字进行判断,可能带来大幅改动,但也可能损失图片原有细节。
适当选择降噪强度,建议在0.3到0.5之间,可以在保持原图像细节的同时,减少意外发生。然而,在实际应用中,您需要根据生成图像的具体需求以及原始图像的特性来调整这些参数,以实现最佳的生成效果。
什么是CFG scale,它在Stable Diffusion img2img功能中有什么作用?
CFG scale(配置缩放因子)是Stable Diffusion img2img功能中的一个参数,它用于控制生成图像的尺寸。CFG scale可以帮助用户调整生成图像的大小,以适应不同的应用场景和需求。较大的CFG scale值可以使生成图像具有更高的分辨率和细节,但计算成本可能较高;较小的CFG scale值则可以降低计算成本,但可能降低生成图像的分辨率和细节。
Mask遮罩功能在Stable Diffusion img2img中有什么用途?
Mask遮罩功能在Stable Diffusion img2img中起到控制图像生成区域的作用。遮罩允许用户在图像的指定区域进行生成或编辑,同时保留其他区域的原始信息。通过适当使用遮罩功能,用户可以实现更精确的图像编辑和风格转换,例如仅修改图片背景或人物服装等局部区域。这使得Stable Diffusion img2img技术在不同的应用场景中具有更大的灵活性和应用价值。
Stable Diffusion如何选择合适的sampling steps(采样步数)?
选择合适的sampling steps(采样步数)主要取决于生成图像的需求和原始图像的特性。较低的采样步数通常会导致较快的生成速度,但可能会损失部分细节。反之,较高的采样步数可以保留更多细节,但生成速度可能较慢。在实际应用中,建议从较低的采样步数开始尝试,并根据生成图像的效果和需求逐步调整,以达到最佳的生成效果。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Stable Diffusion img2img图生图高级教程:换脸、换服装、换背景、换风格案例精讲 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 