1. 框架介绍
Easy-Classification是一个应用于分类任务的深度学习框架,它集成了众多成熟的分类神经网络模型,可帮助使用者简单快速的构建分类训练任务。
1.1 框架功能
1.1.1 数据加载
- 文件夹形式
- 其它自定义形式,在项目应用中,参考案例编写DataSet自定义加载。如基于配置文件,csv,路径解析等。
1.1.2 扩展网络
本框架扩展支持如下网络模型,可在classification_model_enum.py枚举类中查看具体的model。
- Resnet系列,Densenet系列,VGGnet系列等所有[pretrained-models.pytorch]支持的网络
- ShuffleNetV2,[MicroNet]
1.1.3 优化器
- Adam
- SGD
- AdaBelief
- AdamW
1.1.4 学习率衰减
- ReduceLROnPlateau
- StepLR
- MultiStepLR
- SGDR
1.1.5 损失函数
- 直接调用PyTorch相关的损失函数
- 交叉熵
- Focalloss
1.1.6 其他
- Metric(acc, F1)
- 训练结果acc,loss过程图片保存
- 交叉验证
- 梯度裁剪
- Earlystop
- weightdecay
- 冻结/解冻 除最后的全连接层的特征层
1.2 框架设计
Easy-Classification是一个简单轻巧的分类框架,目前版本主要包括两大模块,框架通用模块和项目应用模块。为方便用户快速体验,框架中目前包括简单手写数字识别和验证码识别两个示例项目。
1.2.1 通用模块设计
Easy-Classification通用模块整体结构如下:
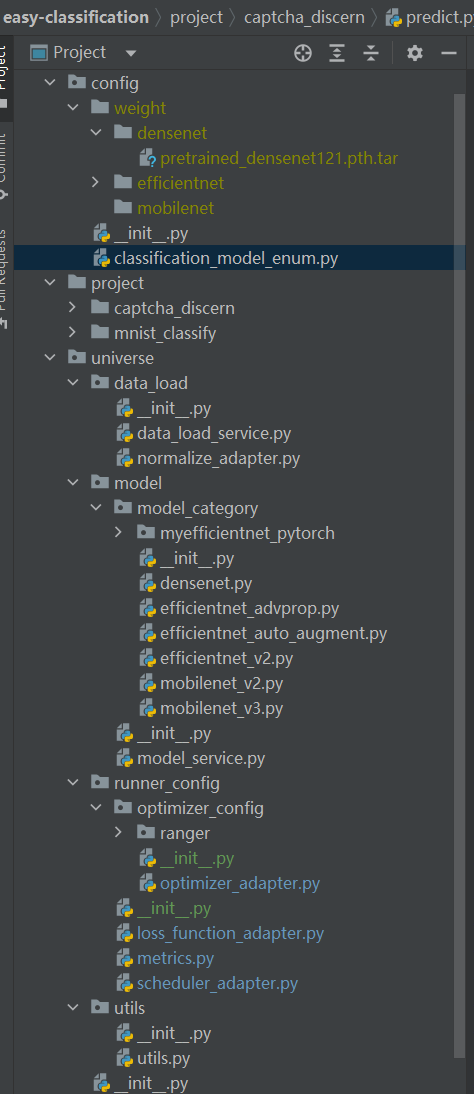

通用模块核心类/文件介绍说明:
|
目录
|
子项
|
功能说明
|
扩展说明
|
|
config
|
|
框架基础配置目录
|
|
|
|
weight
|
预训练权重模型存储目录
|
各种神经网络的模型文件,下载后存储在该目录下
|
|
|
classification_model_enum.py
|
列举出当前分类框架,目前支持的分类神经网络模型。
枚举中的神经网络名称,与配置文件中的名称一样,表示加载对应的网络模型。
|
后续新增网络时,需在该枚举类中注入
|
|
project
|
|
分类框架下的项目应用模块,详细使用参考后续项目应用模块。
|
分类项目目录名称如:验证码识别,简单手写数字识别
|
|
universe
|
|
框架通用模块主目录。
|
后续通用的功能,均可放在该目录下。
|
|
|
data_load
|
基础数据加载类
|
加载训练数据,验证数据,预测数据等
|
|
|
data_load_service.py
|
基于配置文件,加载配置路径下的基础数据,返回对应的张量信息。
不同的分类任务,用户构建DataSet模式不同,该模块提供函数,接收用户构建的DataSet对象。做统一数据加载处理。
|
目前支持目录模式加载。
|
|
|
normalize_adapter.py
|
归一化配置类
|
其他新增网络的归一化参数,可配置在此类中。
|
|
|
model
|
定义目前框架中,支持的所有分类网络模型。
|
新增网络放入到model_category目录下。
|
|
|
model_service.py
|
分类网络模型的对外暴露类,基于配置文件,可指定具体使用哪个分类网络,项目应用时,只需调用moel_service。
moel_service.py:代理者的角色。类似于java中的代理模式。
|
新增的分类网络,要注入到moel_service.py中,对所有分类网络的统一拦截,加日志等功能可在model_service中实现。
|
|
runner_config
|
|
训练配置的目录,定义训练过程中的一些配置信息。
|
定义如优化器,学习率调整,损失函数等。
深度学习运行前,配置相关的模块均可放在该目录下。
|
|
|
optimizer_adapter.py
|
优化器适配类,根据配置文件,可返回一个具体的优化器。
|
常用优化器如:Adam,AdamW,SGD,AdaBelief,Ranger
|
|
|
loss_function_adapter.py
|
自定义损失函数适配类,可基于配置文件,返回一个具体的损失函数。
|
损失函数也可使用 PyTorch中提供的。
|
|
|
scheduler_adapter.py
|
学习率调整适配类,可基于配置文件,返回具体的调整类。
|
扩展支持ReduceLROnPlateau,StepLR,MultiStepLR, SGDR
|
|
utils
|
utils.py
|
常用的工具函数,如加载文件,全连接处理等
|
一些项目通用的工具类函数,如保存acc,loss等记录。
|
配置文件是设置在具体应用项目的目录下,配置文件可根据项目需求自定义编写,但每个配置文件需包含如下关键key字段:
|
key字段
|
解释
|
参考值
|
|
model_name
|
分类网络模型名称,如mobilenetv3,efficientnet_advprop,具体值参考ClassificationModelEnum枚举类中定义的值
|
efficientnet_advprop
|
|
GPU_ID
|
多GPU时,设置的GPU编码,无GPU时,该值设置为空
|
0
|
|
class_number
|
目标输出分类数量,如简单数字识别,输出值10
|
10
|
|
random_seed
|
随机数种子
|
43
|
|
num_workers
|
DataLoad加载数据时,是否启用多个线程加载数据
|
4
|
|
train_path
|
训练图像对应的存储目录地址
|
"data/train"
|
|
val_path
|
验证图像对应的存储目录地址
|
"data/val"
|
|
test_path
|
预测图像对应的存储目录地址
|
"data/test"
|
|
pretrained
|
预加载模型权重的文件存储路径,无值时,设置为空‘’
|
'../../out/mobilenetv3.pth'
|
|
save_best_only
|
训练时,是否只保存最优的模型
|
true
|
|
target_img_size
|
图像转换为网络模型对应的目标图像尺寸,如mobilenet v3,接收图为:[224,224]
|
[224,224]
|
|
learning_rate
|
初始化学习率值
|
0.001
|
|
batch_size
|
训练时,DataLoad一次加载数据的批次数量
|
64
|
|
test_batch_size
|
预测时,DataLoad一次加载数据的批次数量
|
1
|
|
epochs
|
训练总次数
|
100
|
|
optimizer
|
优化器类型,枚举值:Ranger,AdaBelief,SGD,AdamW,Adam
|
SGD
|
|
scheduler
|
学习衰减率调整策略,枚举值:default,step,SGDR,multi
|
default
|
|
loss
|
损失函数,若使用pytorch提供的损失函数,可不管该值。使用框架提供的需配置。枚举值:CE,CE2,Focalloss
|
|
|
early_stop_patient
|
提前结束,当后续训练轮次出现N次,acc小于历史值时,就提前结束
|
7
|
|
model_path
|
模型预测时,训练生成的权重文件存储路径
|
'../../out/mobilenetv3_e22_0.97.pth'
|
|
dropout
|
为了防止过拟合,设置值,表示随机多少比例的神经元失效,取值服务[0,1]
|
0.5
|
|
class_weight
|
训练数据类别分配不均匀,防止过拟合等情况出现,设置的惩罚值。默认值设置为None。
|
调用:n.CroEntropyLoss(),设置不同类别的惩罚值,三个类别,如[0.8,0.1,0.1]。
|
|
weight_decay
|
在与梯度做运算时,当前权重先减去一定比例的大小。
|
0.01
|
1.2.2 项目应用模块设计
Easy-Classification项目应用模块整体结构如下:

项目应用模块核心类/文件介绍说明:
|
目录
|
子项
|
功能说明
|
扩展说明
|
|
mnist_caassify
|
|
分类项目主目录
|
表示一个具体的分类项目,本例为简单手写数字识别
|
|
|
data
|
该项目的训练数据,验证数据,推理数据等
|
与训练流程,推理流程等相关的数据,包括图片和label等配置信息。
|
|
|
output
|
项目的输出结果
|
训练过程中的acc,loss图,模型权重文件,预测结果等,全部输出到这个目录。
|
|
|
scripts
|
构建训练数据,验证数据等的脚本文件
|
基于脚本文件,生产对应的训练数据,验证数据到data目录下。主要功能如:
1.生产图片,生成label;
2.解析文件,并基于图像做一定的前期调整。清洗训练数据,提前加工部分数据。
|
|
|
service
|
分类任务,主要的项目应用模块,用户自定义代码存储目录。
|
|
|
|
xxx_config.py
|
分类项目的配置文件,每一个分类项目都存在一个单独的配置文件。
|
常用的配置参数,如指定使用什么模型,图像大小调整等,具体参考案例的配置文件
|
|
|
xxx_dataset.py
|
分类项目的数据加载类
|
每个分类任务的数据加载模式不一定完全一样,该模块属于用户自定义模块。可做图像的预处理,最终将图像转换为张量信息。
|
|
|
xxx_runner_service.py
|
分类项目的运行类
|
包括配置运行参数,训练流程定义,预测流程处理等。
|
|
|
train.py,prectict.py
|
训练类,预测类
|
主要是加载配置文件,获取训练数据,加载网络模型,初始化训练过程的配置参数,调用训练函数开始训练。
|
1.3 框架使用
1.3.1 基础使用
用户在简单使用Easy-Classification分类框架时,只需编写项目应用模块的代码,参考给出的两个案例,结合项目自身情况,需做如下步骤处理:
- 在project 目录下,创建一个目录作为项目名称,目录名称命名为项目名称,如mnist_classsify。
- 在mnist_classsify目录下,创建一个data目录,用于存储训练,验证,推理等相关的基础数。
- scripts目录,根据实际情况,若项目提前准备好数据了,可不编写。若需要通过一定的脚本预处理训练数据,可在该目录下编写脚本处理。
- 在mnist_classsify目录下,创建一个service目录。
- 编写配置文件,xxx_config.py,配置文件的key值一定要和案例中的配置key名称一样(不然通用模块无法加载)。
- 编写DataSet自定义类,xxx_dataset.py,参考案例中的DataSet类,编写自定义Dataset类时,初始化参数需定义为source_img, cfg。否则数据加载通用模块,data_load_service.py模块会报错。(source_img :传入的图像地址信息集合。基于配置文件,加载文件的路径信息。 cfg:传入的配置类,是配置文件xxx_config.py。)
- 编写项目运行类,xxx_runner_service.py,参考案例中的项目运行类,注意输出张量信息处理,acc计算等根据实际情况调整。
- 编写train.py,prectict.py,参考案例中的代码,加载数据时,传入编写的xxx_dataset类,调用xxx_runner_service.py中提供的训练函数,预测函数即可。
1.3.2 扩展使用
目前框架的功能还比较基础,若发现框架中有不支持的网络模型,或其他的一些优化器,学习率调整等,均可通过调整源码的模式自定义扩展增强。源码中关键类的功能参考章节1.2.1中的介绍。如自定义一个网络模型可通过如下流程:
- 在model/model_category目录下,添加对应的网络模型如:test_model.py。
- 在config/classification_model_enum.py文件中,添加新增的网络模型。
- 在model_service.py中,注入新增的网络模型。
- 在配置文件中,配置使用的模型名称,如:test_model。
2. 框架案例介绍
框架设计与案例参考文档:
3. 参考文献
2. warmup
4. 易大师
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Easy-Classification-分类框架设计 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 