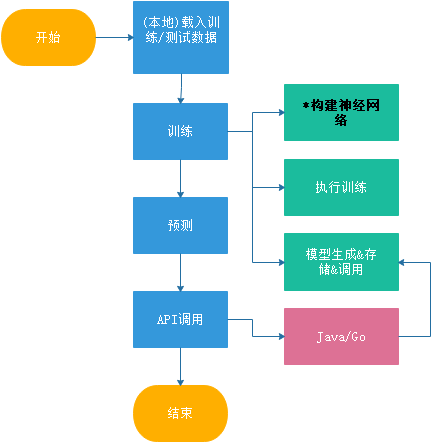
1 简单的深度学习过程常规流程:
PS: 标*的 构建神经网络是最重要的。

2 本demo功能:基于TensorFlow Keras来建立模型、训练(喂给它已经分类好的人脸表情图片)和预测 人脸表情图片。
上代码:
1 import os 2 import sys 3 from PIL import Image # 使用第三方包Pillow来进行图像处理 4 import numpy as np 5 import tensorflow.contrib.keras as k 6 import scipy.spatial.distance as distance # 使用第三方包scipy来进行向量余弦相似度判断 7 import pandas as pd 8 9 10 # 这是一个自定义函数,用于把图片按比例缩放到最大宽度为maxWidth、最大高度为maxHeight 11 def resizeImage(inputImage, maxWidth, maxHeight): 12 originalWidth, originalHeight = inputImage.size 13 14 f1 = 1.0 * maxWidth / originalWidth 15 f2 = 1.0 * maxHeight / originalHeight 16 factor = min([f1, f2]) 17 18 width = int(originalWidth * factor) 19 height = int(originalHeight * factor) 20 return inputImage.resize((width, height), Image.ANTIALIAS) 21 22 23 ifRestartT = False 24 roundCount = 20 25 learnRate = 0.01 26 trainDir = "./imagedata/" # 用于指定训练数据所在目录 27 trainResultPath = "./imageClassifySave/" # 用于指定训练过程保存目录 28 optimizerT = "RMSProp" # 用于指定优化器 29 lossT = "categorical_crossentropy" # 用于指定误差函数 30 #predictFile = None # 用于指定需预测的新图像文件,如果为None则表示不预测 31 predictFile = "./predictFile/xx.jpg" 32 33 # 读取meta.txt文件内容:分类 34 #metaData = pd.read_csv(trainDir + "meta.txt", header=None).as_matrix() 35 metaData = pd.read_csv(trainDir + "meta.txt", header=None).iloc[:,:].values 36 37 # maxTypes表示种类个数 38 maxTypes = len(metaData) 39 print("maxTypes: %d" % maxTypes) 40 41 argt = sys.argv[1:] 42 print("argt: %s" % argt) 43 44 for v in argt: 45 if v == "-restart": 46 print("我打印了吗?") 47 ifRestartT = True 48 if v.startswith("-round="): 49 roundCount = int(v[len("-round="):]) 50 if v.startswith("-learnrate="): 51 learnRate = float(v[len("-learnrate="):]) 52 if v.startswith("-dir="): # 用于指定训练数据所在目录(不使用默认目录时才需要设置) 53 trainDir = v[len("-dir="):] 54 if v.startswith("-optimizer="): 55 optimizerT = v[len("-optimizer="):] 56 if v.startswith("-loss="): 57 lossT = v[len("-loss="):] 58 if v.startswith("-predict="): 59 predictFile = v[len("-predict="):] 60 61 print("predict file: %s" % predictFile) 62 63 xData = [] 64 yTrainData = [] 65 fnData = [] 66 predictAry = [] 67 68 listt = os.listdir(trainDir) # 获取变量trainDir指定的目录下所有的文件 69 70 lent = len(listt) 71 72 # 循环处理训练目录下的图片文件,统一将分辨率转换为256*256, 73 # 再把图片处理成3通道(RGB)的数据放入xData,然后从文件名中提取目标值放入yTrainData 74 # 文件名放入fnData 75 for i in range(lent): 76 v = listt[i] 77 if v.endswith(".jpg"): # 只处理.jpg为扩展名的文件 78 print("processing %s ..." % v) 79 img = Image.open(trainDir + v) 80 w, h = img.size 81 82 img1 = resizeImage(img, 256, 256) 83 84 img2 = Image.new("RGB", (256, 256), color="white") 85 86 w1, h1 = img1.size 87 88 img2 = Image.new("RGB", (256, 256), color="white") 89 90 img2.paste(img1, box=(int((256 - w1) / 2), int((256 - h1) / 2))) 91 92 xData.append(np.matrix(list(img2.getdata()))) 93 94 tmpv = np.full([maxTypes], fill_value=0) 95 tmpv[int(v.split(sep="_")[0]) - 1] = 1 96 yTrainData.append(tmpv) 97 98 fnData.append(trainDir + v) 99 100 rowCount = len(xData) 101 print("rowCount: %d" % rowCount) 102 103 # 转换xData、yTrainData、fnData为合适的形态 104 xData = np.array(xData) 105 xData = np.reshape(xData, (-1, 256, 256, 3)) 106 107 yTrainData = np.array(yTrainData) 108 109 fnData = np.array(fnData) 110 111 # 使用Keras来建立模型、训练和预测 112 if (ifRestartT is False) and os.path.exists(trainResultPath + ".h5"): 113 # 载入保存的模型和可变参数 114 print("模型已经存在!!!!!!!!...") 115 print("Loading...") 116 model = k.models.load_model(trainResultPath + ".h5") 117 model.load_weights(trainResultPath + "wb.h5") 118 else: 119 # 新建模型 120 model = k.models.Sequential() 121 122 # 使用4个卷积核、每个卷积核大小为3*3的卷积层 123 model.add(k.layers.Conv2D(filters=4, kernel_size=(3, 3), input_shape=(256, 256, 3), data_format="channels_last", activation="relu")) 124 125 model.add(k.layers.Conv2D(filters=3, kernel_size=(3, 3), data_format="channels_last", activation="relu")) 126 127 # 使用2个卷积核、每个卷积核大小为2*2的卷积层 128 model.add(k.layers.Conv2D(filters=2, kernel_size=(2, 2), data_format="channels_last", activation="selu")) 129 130 model.add(k.layers.Flatten()) 131 # 此处的256没有改 132 model.add(k.layers.Dense(256, activation=\'tanh\')) 133 134 model.add(k.layers.Dense(64, activation=\'sigmoid\')) 135 136 # 按分类数进行softmax分类 137 model.add(k.layers.Dense(maxTypes, activation=\'softmax\')) 138 139 model.compile(loss=lossT, optimizer=optimizerT, metrics=[\'accuracy\']) 140 141 142 if predictFile is not None: 143 # 先对已有训练数据执行一遍预测,以便后面做图片相似度比对 144 print("preparing ...") 145 predictAry = model.predict(xData) 146 147 print("processing %s ..." % predictFile) 148 img = Image.open(predictFile) 149 150 # 下面是对新输入图片进行预测 151 img1 = resizeImage(img, 256, 256) 152 153 w1, h1 = img1.size 154 155 img2 = Image.new("RGB", (256, 256), color="white") 156 157 img2.paste(img1, box=(int((256 - w1) / 2), int((256 - h1) / 2))) 158 159 xi = np.matrix(list(img2.getdata())) 160 xi1 = np.array(xi) 161 xin = np.reshape(xi1, (-1, 256, 256, 3)) 162 163 resultAry = model.predict(xin) 164 print("x: %s, y: %s" % (xin, resultAry)) 165 166 # 找出预测结果中最大可能的概率及其对应的编号 167 maxIdx = -1 168 maxPercent = 0 169 170 for i in range(maxTypes): 171 if resultAry[0][i] > maxPercent: 172 maxPercent = resultAry[0][i] 173 maxIdx = i 174 175 # 将新图片的预测结果与训练图片的预测结果逐一比对,找出相似度最高的 176 minDistance = 200 177 minIdx = -1 178 minFile = "" 179 180 for i in range(rowCount): 181 dist = distance.cosine(resultAry[0], predictAry[i]) # 用余弦相似度来判断两张图片预测结果的相近程度 182 if dist < minDistance: 183 minDistance = dist 184 minIdx = i 185 minFile = fnData[i] 186 187 print("推测表情:%s,推断正确概率:%10.6f%%,最相似文件:%s,相似度:%10.6f%%" % (metaData[maxIdx][1], maxPercent * 100, minFile.split("\\")[-1], (1 - minDistance) * 100)) 188 189 sys.exit(0) 190 191 model.fit(xData, yTrainData, epochs=roundCount, batch_size=lent, verbose=2) 192 193 print("saving...") 194 model.save(trainResultPath + ".h5") 195 model.save_weights(trainResultPath + "wb.h5")
3 用于训练的图片:
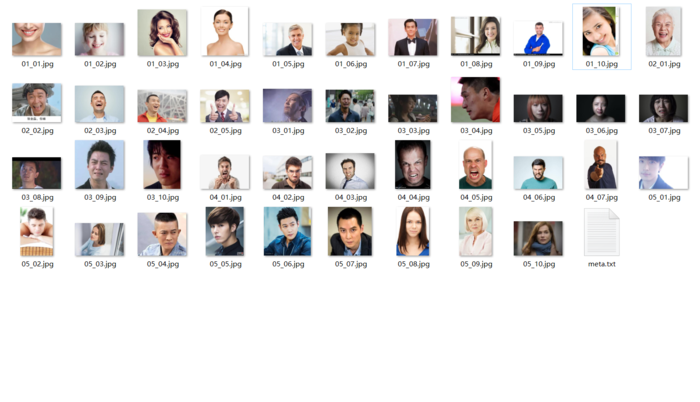
PS: 这些图是在网上随便找哒。这里需要注意图片的命名规则:eg: 01_06.jpg 01代表图片的类型,和meta.txt中的类型对应,06代表01类型下的第几张
meat.txt文件:
1 1,微笑 2 2,大笑 3 3,哭 4 4,愤怒 5 5,平静
4 预测:
用于预测的图片:小公举~~~

预测结果:
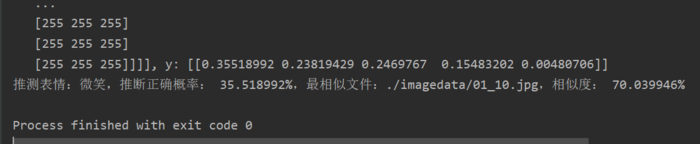
PS: 后续有需要会继续更新。。。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Tensorflow Keras基于深度学习的图像识别/人脸表情识别demo - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 