任务目标
对MNIST手写数字数据集进行训练和评估,最终使得模型能够在测试集上达到\(98\%\)的正确率。(最终本文达到了\(99.36\%\))
使用的库的版本:
- python:3.8.12
- pytorch:1.5.1
代码地址GitHub:https://github.com/xiaohuiduan/deeplearning-study/tree/main/手写数字识别
数据集介绍
MNIST数字数据集来自MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges。
在torchvision中自带了关于MNIST的数据集。如果直接使用自带的数据集,能方便不少。关于具体使用,可参考:PyTorch初探MNIST数据集 - 知乎 (zhihu.com)
在Lecun的提供的MNIST数据集,有如下4个文件(images文件和labels文件):


training set包含了60000张手写数字图片,test set包含了10000张图片。在images文件和labels文件中,数据是使用二进制进行保存的。
图像文件的二进制储存格式如下(参考python处理MNIST数据集 - 简书 (jianshu.com)):
-
第1-4个byte(字节,1byte=8bit),即前32bit存的是文件的magic number,对应的十进制大小是2051;
-
第5-8个byte存的是number of images,即图像数量60000;
-
第9-12个byte存的是每张图片行数/高度,即28;
-
第13-16个byte存的是每张图片的列数/宽度,即28。
-
从第17个byte开始,每个byte存储一张图片中的一个像素点的值。
标签文件的二进制储存格式如下(参考python处理MNIST数据集 - 简书 (jianshu.com)):
-
第1-4个byte存的是文件的magic number,对应的十进制大小是2049;
-
第5-8个byte存的是number of items,即label数量60000;
-
从第9个byte开始,每个byte存一个图片的label信息,即数字0-9中的一个。
二进制文件的Python处理代码:
import numpy as np
def read_image(file_path):
"""读取MNIST图片
Args:
file_path (str): 图片文件位置
Returns:
list: 图片列表
"""
with open(file_path,'rb') as f:
file = f.read()
img_num = int.from_bytes(file[4:8],byteorder='big') #图片数量
img_h = int.from_bytes(file[8:12],byteorder='big') #图片h
img_w = int.from_bytes(file[12:16],byteorder='big') #图片w
img_data = []
file = file[16:]
data_len = img_h*img_w
for i in range(img_num):
data = [item/255 for item in file[i*data_len:(i+1)*data_len]]
img_data.append(np.array(data).reshape(img_h,img_w))
return img_data
def read_label(file_path):
with open(file_path,'rb') as f:
file = f.read()
label_num = int.from_bytes(file[4:8],byteorder='big') #label的数量
file = file[8:]
label_data = []
for i in range(label_num):
label_data.append(file[i])
return label_data
train_img = read_image("mnist/train/train-images.idx3-ubyte")
train_label = read_label("mnist/train/train-labels.idx1-ubyte")
# test_img = read_image("mnist/test/t10k-images.idx3-ubyte")
# test_label = read_label("mnist/test/t10k-labels.idx1-ubyte")
数据集部分数据如下所示:

数据集划分
在深度学习中,需要将trainset划分成训练集,验证集。最终使用测试集去验证模型的结果。
训练集:用来训练模型参数。
验证集:验证模型的状况和收敛情况。
测试集:验证模型结果。
形象上来说训练集就像是学生的课本,学生 根据课本里的内容来掌握知识,验证集就像是作业,通过作业可以知道 不同学生学习情况、进步的速度快慢,而最终的测试集就像是考试,考的题是平常都没有见过,考察学生举一反三的能力。
来源:训练集(train)验证集(validation)测试集(test)与交叉验证法 - 知乎 (zhihu.com)
因此,需要将上文中的train_img,train_label进行划分,划分为训练集和验证集。这里使用sklearn中的train_test_split进行划分,训练集和测试集的比例为\(8:2\)。
from sklearn.model_selection import train_test_split
train_img,valid_img,train_label,valid_label = train_test_split(train_img,train_label,test_size=0.2,shuffle=True)
网络结构
根据网络的权重,Netron生成的网络结构图如下,图中详细的介绍了每一层的结构参数。

网络结构的简洁图如下所示,网络一共由3层卷积层(每层卷积分别由Conv2d,BatchNorm2d,MaxPool2d和Dropout构成)和2个全连接层构成。
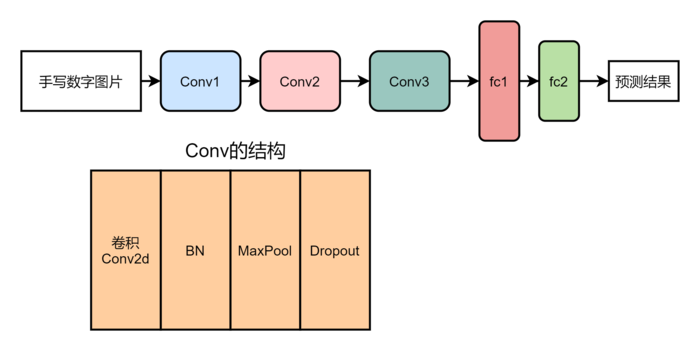
Pytorch代码如下:
class MyNet(nn.Module):
def __init__(self):
super(MyNet,self).__init__()
self.conv_1 = nn.Sequential(
nn.Conv2d(1,32,kernel_size=3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.MaxPool2d(2,2),
nn.Dropout(0.25)
)
self.conv_2 = nn.Sequential(
nn.Conv2d(32,64,kernel_size=3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2,2),
nn.Dropout(0.25),
)
self.conv_3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2,2),
nn.Dropout(0.25),
)
self.fc = nn.Sequential(
nn.Linear(512,128),
nn.Linear(128,10)
)
def forward(self,x): #x (3,28,28)
x = self.conv_1(x) #x (32,14,14)
x = self.conv_2(x) #x (64,7,7)
x = self.conv_3(x) #x (128,4,4)
x = x.view(x.size(0),-1)
x = self.fc(x)
return F.log_softmax(x,dim=1)
myNet = MyNet().to(device)
训练集以及验证集结果
大概经过300个epoch训练,验证集便能够达到\(99.9\%\)以上的正确率。
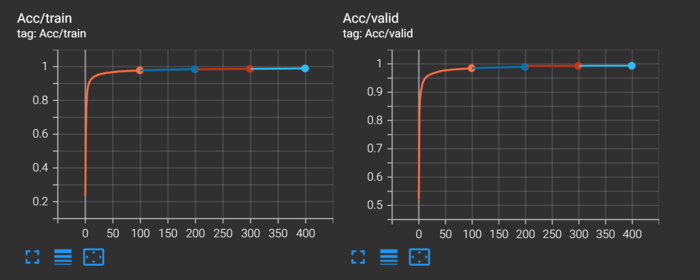
训练集的Loss曲线:
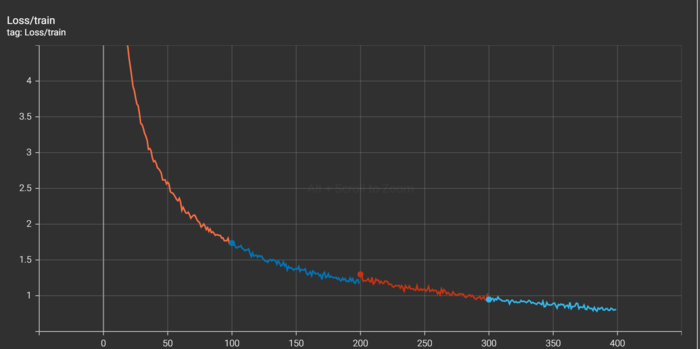
测试集结果
测试集使用训练400个epoch之后的模型进行预测。其最终预测的正确率为:\(99.36 \%\)。实际上,大概300个epoch就能够在测试集达到\(99\%\)以上的正确率。
参考
- MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
- MNIST — Torchvision 0.12 documentation (pytorch.org)
- python处理MNIST数据集 - 简书 (jianshu.com)
- 训练集(train)验证集(validation)测试集(test)与交叉验证法 - 知乎 (zhihu.com)
- sklearn.model_selection.train_test_split — scikit-learn 1.0.2 documentation
- Netron
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习(一)之MNIST数据集分类 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 