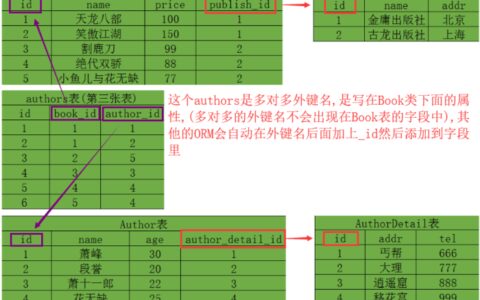
一、queryset
Queryset是django中构建的一种数据结构,ORM查询集往往是queryset数据类型,我们来进一步了解一下queryset的特点。
1、可切片
使用Python 的切片语法来限制查询集记录的数目。它等同于SQL 的LIMIT 和OFFSET 子句。
>>> Entry.objects.all()[:5] # (LIMIT 5) >>> Entry.objects.all()[5:10] # (OFFSET 5 LIMIT 5)
不支持负的索引(例如Entry.objects.all()[-1])。通常,查询集的切片返回一个新的查询集(它不会再执行sql查询语句)。
2、可迭代
articleList = models.Article.objects.all() for article in articleList: print(article.title)
3、惰性查询
查询集是惰性执行的 —— 创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整天,直到查询集需要求值时,Django 才会真正运行这个查询。
queryResult = models.Article.objects.all() # not hits database print(queryResult) # hits database for article in queryResult: print(article.title) # hits database
一般来说,只有在“请求”查询集的结果时才会到数据库中去获取它们。当你确实需要结果时,查询集通过访问数据库来求值。
4、缓存机制
每个查询集都包含一个缓存来最小化对数据库的访问。理解它是如何工作的将让你编写最高效的代码。
在一个新创建的查询集中,缓存为空。首次对查询集进行求值 —— 同时发生数据库查询 ——Django 将保存查询的结果到查询集的缓存中并返回明确请求的结果(例如,如果正在迭代查询集,则返回下一个结果)。接下来对该查询集的求值将重用缓存的结果。
请牢记这个缓存行为,因为对查询集使用不当的话,它会坑你的。例如,下面的语句创建两个查询集,对它们求值,然后扔掉它们:
print([a.title for a in models.Article.objects.all()]) print([a.create_time for a in models.Article.objects.all()])
这意味着相同的数据库查询将执行两次,显然倍增了你的数据库负载。同时,还有可能两个结果列表并不包含相同的数据库记录,因为在两次请求期间有可能有Article被添加进来或删除掉。为了避免这个问题,只需保存查询集并重新使用它,如下:
queryResult = models.Article.objects.all() print([a.title for a in queryResult]) print([a.create_time for a in queryResult]
何时查询集不会被缓存?
查询集不会永远缓存它们的结果。当只对查询集的部分进行求值时会检查缓存,如果这个部分不在缓存中,那么接下来查询返回的记录都将不会被缓存。所以,这意味着使用切片或索引来限制查询集将不会填充缓存。例如,重复获取查询集对象中一个特定的索引将每次都查询数据库,如下:
>>> queryset = Entry.objects.all() >>> print queryset[5] # Queries the database >>> print queryset[5] # Queries the database again
然而,如果已经对全部查询集求值过,则将检查缓存,如下:
>>> queryset = Entry.objects.all() >>> [entry for entry in queryset] # Queries the database >>> print queryset[5] # Uses cache >>> print queryset[5] # Uses cache
下面是一些其它例子,它们会使得全部的查询集被求值并填充到缓存中:
>>> [entry for entry in queryset] >>> bool(queryset) >>> entry in queryset >>> list(queryset)
注意:简单地打印查询集不会填充缓存,如下:
queryResult = models.Article.objects.all() print(queryResult) # hits database print(queryResult) # hits database
5、exists()与iterator()方法
(1)exists()
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些数据!为了避免这个,可以用exists()方法来检查是否有数据,如下:
if queryResult.exists(): # SELECT (1) AS "a" FROM "blog_article" LIMIT 1; args=() print("exists...")
(2)iterator()
当queryset非常巨大时,cache会成为问题。
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法来获取数据,处理完数据就将其丢弃。如下:
objs = Book.objects.all().iterator() # iterator()可以一次只从数据库获取少量数据,这样可以节省内存 for obj in objs: print(obj.title) # BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了 for obj in objs: print(obj.title)
当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询。
总结:queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能会造成额外的数据库查询。因此,要根据场景灵活使用。
二、二级菜单的默认显示
1、修改my_tags.py文件,代码如下:
@register.inclusion_tag("menu.html") def get_menu_styles(request): permission_menu_dict = request.session.get("permission_menu_dict") print("permission_menu_dict", permission_menu_dict) for val in permission_menu_dict.values(): for item in val["children"]: val["class"] = "hide" ret = re.search("^{}$".format(item["url"]), request.path) if ret: val["class"] = "" return {"permission_menu_dict": permission_menu_dict}
2、修改menu.html文件,代码如下:
<div class="multi-menu"> {% for item in permission_menu_dict.values %} <div class="item"> <div class="title"> <i class="{{ item.menu_icon }}"></i>{{ item.menu_title }} </div> <div class="body {{ item.class }}"> {% for foo in item.children %} <a href="{{ foo.url }}">{{ foo.title }}</a> {% endfor %} </div> </div> {% endfor %} </div>
三、动态显示按钮权限
除了菜单权限,还有按钮权限,比如添加用户(账单),编辑用户(账单),删除用户(账单),这些不是菜单选项,而是以按钮的形式在页面中显示,但不是所有的用户都有所有的按钮权限,我们需要在用户不拥有这个按钮权限时就不要显示这个按钮,下面介绍一下思路和关键代码。
1、在permission表中增加一个字段name,permission模型类如下:
class Permission(models.Model): """ 权限表 """ url = models.CharField(verbose_name='含正则的URL', max_length=32) title = models.CharField(verbose_name='标题', max_length=32) menu = models.ForeignKey(verbose_name='标题', to="Menu", on_delete=models.CASCADE, null=True) name = models.CharField(verbose_name='url别名', max_length=32, default="") def __str__(self): return self.title
2、将权限别名列表注入session,setsession.py中代码如下:
def initial_session(user_obj, request): """ 将当前登录人的所有权限url列表和 自己构建的所有菜单权限字典和 权限表name字段列表注入session :param user_obj: 当前登录用户对象 :param request: 请求对象HttpRequest """ # 查询当前登录人的所有权限列表 ret = Role.objects.filter(user=user_obj).values('permissions__url', 'permissions__title', 'permissions__name', 'permissions__menu__title', 'permissions__menu__icon', 'permissions__menu__id').distinct() permission_list = [] permission_names = [] permission_menu_dict = {} for item in ret: # 获取用户权限列表用于中间件中权限校验 permission_list.append(item['permissions__url']) # 获取权限表name字段用于动态显示权限按钮 permission_names.append(item['permissions__name']) menu_pk = item['permissions__menu__id'] if menu_pk: if menu_pk not in permission_menu_dict: permission_menu_dict[menu_pk] = { "menu_title": item["permissions__menu__title"], "menu_icon": item["permissions__menu__icon"], "children": [ { "title": item["permissions__title"], "url": item["permissions__url"], } ], } else: permission_menu_dict[menu_pk]["children"].append({ "title": item["permissions__title"], "url": item["permissions__url"], }) print('权限列表', permission_list) print('菜单权限', permission_menu_dict) # 将当前登录人的权限列表注入session中 request.session['permission_list'] = permission_list # 将权限表name字段列表注入session中 request.session['permission_names'] = permission_names # 将当前登录人的菜单权限字典注入session中 request.session['permission_menu_dict'] = permission_menu_dict
3、自定义过滤器,my_tags.py中部分代码如下:
@register.filter def has_permission(btn_url, request): permission_names = request.session.get("permission_names") return btn_url in permission_names
4、使用过滤器,模板(如customer_list.html)中部分权限按钮代码如下:
<div class="btn-group"> {% load my_tags %} {% if "customer_add"|has_permission:request %} <a class="btn btn-default" href="/customer/add/"> <i class="fa fa-plus-square" aria-hidden="true"></i> 添加客户 </a> {% endif %} </div>
注意:permission表中新增name字段与url的别名没有关系,当然也可以起一样的名字,心里明白他们其实并无关系即可。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Django – 权限(4)- queryset、二级菜单的默认显示、动态显示按钮权限 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫