
-
循环神经网络(RNN) VS 卷积神经网络
- 卷积神经网络:输入输出之间相对独立(图像分类)
- 循环神经网络:处理上下文具有时序关系的任务;引入“记忆”的概念(机器翻译)
-
RNN的基本结构
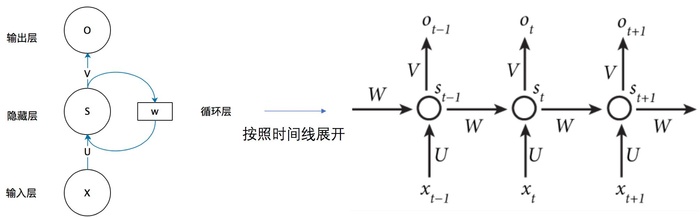

O[t] = g(V×S[t]) S[t] = f(U×X[t] + W×S[t-1])————W、U参数固定 注:RNN在不同时刻共享同一组权值数据(U,W,V),极大减小了参数量如上图:t时刻的输出O[t]由上一时刻(t-1)的记忆S[t-1]和t时刻的输入X[t]共同影响得到;而上一时刻(t-1)的记忆又会受到前面时刻的记忆和输入X的影响,共同构成上下文的时序关系。比如小明 的 宿舍号 是 123号,在RNN中,输入X2(宿舍号)的输出Y(123号)受上文X1(小明)的影响
当然,并非每个时刻都有输出,比如本文分类;也并非每个时刻都有输入。
-
双向RNN(BRNN)的基本结构
如图:单项RNN仅考虑了上文信息的影响,却忽视了下文信息的重要性。BRNN的输出同时考虑上文和下文的输入进行输出。如语句“苹果12 Pro Max预计在2020年发布”,仅仅考虑输入X1“苹果”的分类结果输出y1可能为“水果”,但是考虑下文信息X2“12 Pro Max”的结果分类y1则为“电子产品”了
-
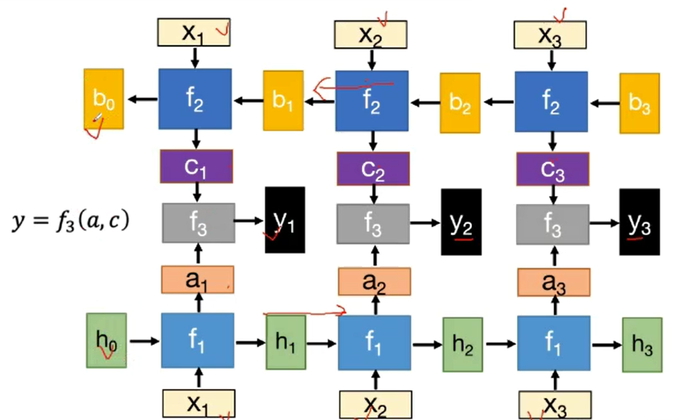
RNN的反向传播算法——BPTT算法
-
设RNN的基本公式: h[t] = tanh(U×x[t] + W×h[t-1]) y[t]' = softmax(V×h[t]) 若时间t时刻的损失: E[t] = E(y[t], y[t]') = -y[t] × log(y[t]') 则总损失: E = Σ Et 更新权重时:偏E / 偏W = Σt(偏E / 偏W)例:t = 3 时:
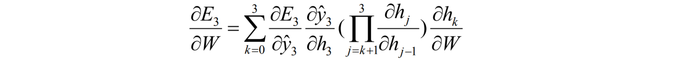
根据h(t)公式,上式的其中的连乘部分:

当W≠0时时,tanh'W<1,t较大时,上式趋于0,存在梯度消失的问题。具体如下图:tanh(x)——红线;tanh'(x)——绿线
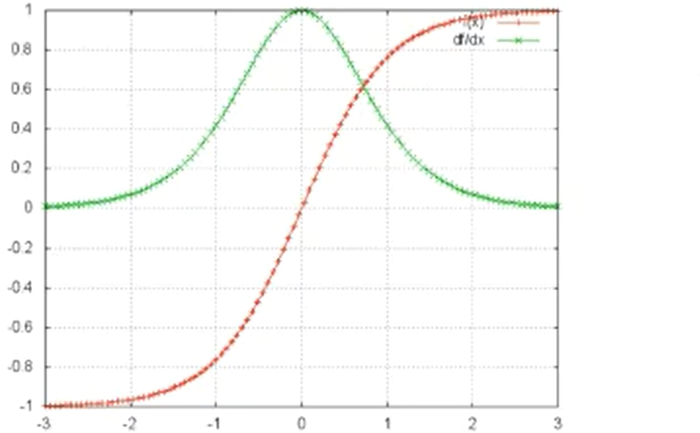
梯度消失出现的问题:

-
RNN的改进——LSTM
组成:遗忘门、输入门、输出门
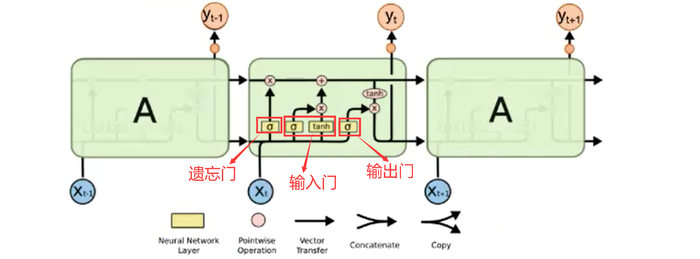
-
遗忘门(决定丢弃上一个memory中的信息):ft = σ ( Wf [ h(t-1) , xt ] + bf )
σ:Sigmoid函数——描述每个部分有多少量通过,0~1之间。0——不允许任意量通过
-
输入门(确认需要更新的信息):
i(t) = σ(Wi · [h(t-1), xt] + bi):决定什么信息需要更新 Ct‘ = tanh(Wc · [h(t-1), xt] + bc):备选的需要更新的内容 Ct = ft(遗忘门) × C(t-1) + i(t) × Ct’————忘记先前的一些信息,记住现有的重要信息(线性变化) -
输出门(输出信息):
o(t) = σ(Wo · [h(t-1), xt] + bo):确定哪些部分进行输出 ht = o(t) × tanh(Ct):输出确定的部分 -
RNN vs LSTM
-
RNN与LSTM对记忆的处理方式不同
RNN: h[t] = tanh(U×x[t] + W×h[t-1]) LSTM: Ct = ft(遗忘门) × C(t-1) + i(t) × Ct’ -
LSTM能解决上文RNN的BPTT中梯度消失问题
因为RNN的”记忆“在每个时间点都会被新的输入覆盖,但LSTM中”记忆“是与新的输入相加
-
LSTM学习率尽可能设置小
-
-
LSTM的简化——GRU
-
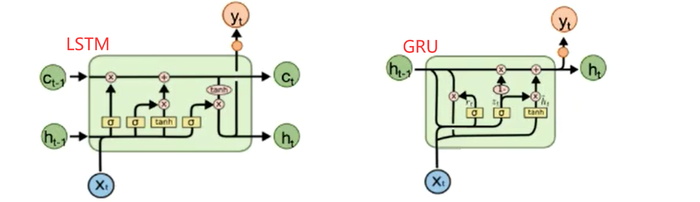
-
z(t) = σ ( Wz · [h(t-1), xt] ) r(t) = σ ( Wr · [h(t-1), xt] ) ht‘ = tanh ( Wc · [r(t) * h(t-1), xt] ) ht = ( 1 - z(t) ) * h(t-1) + z(t) * ht' -
重置门:控制忽略前一时刻的状态信息的程度,重置门越小说明忽略的越多
-
更新门:控制前一时刻的状态信息被带入到当前状态中的程度,更新门值越大表示前一时刻的状态信息带入越多
-
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:循环神经网络(RNN、LSTM) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 