
2. Defense-GAN:Protecting Classifiers Against Adversarial Attacks Using Generative Models
本文[3]基于生成对抗网络(GAN)提出了一种新的防御机制:Defense-GAN。这是一个这是一个利用生成模型的表达能力来保护深度神经网络免受对抗攻击的新框架。 GAN大家应该比较熟悉,因为在前面,我也讲过一篇基于GAN的防御方法。那种方法与本文中的方法有相似之处,也有不同之处,后面会对这两种方法比较分析。作者基于GAN来进行防御,是希望Defense-GAN经过训练构,可以模拟未受干扰图像的分布,然后在输入对抗样本时,会生成一个该对抗样本的满足干净样本分布的近似样本,然后再将该样本输入到分类器进行分类,这也意味着本文提出的方法可以与任何分类模型一起使用,并且不修改分类器结构或训练过程。它还可以用作抵御任何攻击的防御,因为它不会对生成对抗样本的攻击进行任何假设。这也是作者提出该方法的一个动机,因为目前的一些方法都有局限性,因为大多数方法对白盒攻击或黑盒攻击有效,但不是两者都有效。此外,其中一些防御设计时考虑了特定的攻击方式,并且无法有效抵御新的攻击。
我们来看看,具体的方法是怎样的。这里就不再介绍GAN的基础知识了,前面那篇文章已经讲的比较清楚了。不过有一点要说明,这里采用的生成对抗网络不是最原始的那个模型,而是改进过的WGAN,因为GAN的训练不稳定是一个众所周知的问题,所以为了能有更好的成功率,本文采用了经过改善的模型,训练更加稳定一些。
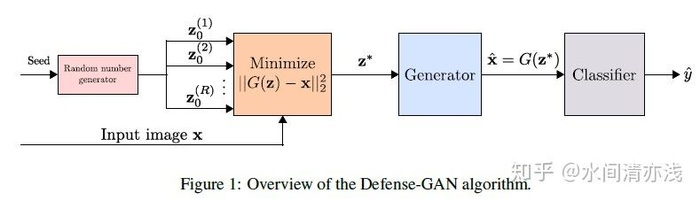
下图是模型的结构示意图,如图1所示。首先利用随机噪声生成器生成一组随机噪声向量,然后将这组随机噪声和干净样本输入到GAN里面,进行训练,直到生成器能够利用随机噪声生成满足干净样本的分布的图像,然后以噪声向量个数为循环变量进行循环训练,直到所有的噪声向量都能通过生成器生成符合要求的图像。然后选取其中表现最好的留下来。
训练目标的数学描述如下式
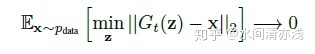
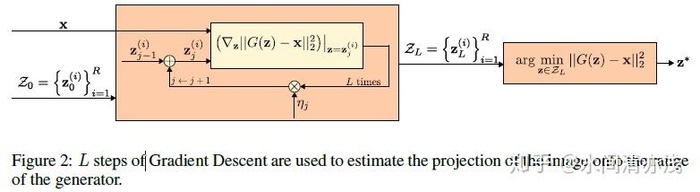
生成器的训练过程如下图所示
我们来分析对比一下,本方法和前面讲到过的APE-GAN方法的异同。两种方法,都是以GAN(WGAN)为基础,以利用生成器重构对抗样本为目的,来实现防御。但是两者的训练过程不同,APE-GAN是将干净样本和对抗样本分别输入判别器D和生成器G进行训练,而Defense-GAN在训练的时候并没有用到对抗样本,而是采用随机噪声输入,这也是一开始训练GAN所采用的输入,但是这里采用了多组噪声输入,进行循环训练。最大的不同,是一种用到了对抗样本进行训练,另一种没有用到。
方法的原理大概就是这些,接下来看一些实验。
作者在实验中设置了三种威胁级别,其中包括常见的白盒设置和黑盒设置,还设置了一种更强的白盒攻击,这种更强的白盒攻击的想法其实就是在使用攻击方法生成对抗样本之前,先向原始样本添加一个小的随机噪声,再将这个加了噪声后的样本作为生成对抗样本的输入样本,以FGSM为例,如下
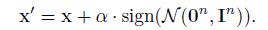
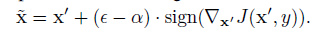
本文主要使用的攻击方法包括FGSM和C&W两种。
数据集为MNIST手写数字数据集和Fashion-MNIST(F-MNIST)时尚服装数据集,两个数据集均包含60,000个训练图像和10,000个测试图像。将训练图像分成50,000个图像的训练集,包含10,000个图像的验证集。对于白盒攻击,测试集保持不变(10,000个样本)。对于黑盒攻击,测试集分出一小组150个样本,用于替代模型训练,其余的9,850个样本用于测试不同的方法。
来看实验结果,首先来看黑盒设置下的结果。


表中结果表明,Defense-GAN对两个数据集来说都减少了黑盒攻击的影响,提升了准确率。
表中的Defense-GAN-Rec和Defense-GAN-Orig表示的是用生成器生成的新的样本还是用原始样本对分类器进行训练,在GAN训练良好的理想情况下,应该是能达到同样的效果的。实验结果表现地几乎如此。另外,这里的Defense-GAN的参数(L和R)设置一样,后面作者也进行了参数的影响实验。实验结果如下

如图所示,增加R效果非常明显,这是由于MSE的非凸性质,增加R能够采样不同的局部最小值。而对FGSM攻击来说,L并不是越大越好,分类性能在某个L值之后会降低,这是因为G和D迭代次数太多,因此保留了一些对抗噪声分量。
另外,Defense-GAN还可以用来进行攻击检测,这是针对那些经过生成器重构以后仍然不是很符合原始数据分布的那些对抗样本,设置阈值,对这些样本进行检测,假设检验条件为

下图显示了不同Defense-GAN参数的接收器操作特性(ROC)曲线以及曲线下面积(AUC)度量的实验结果。

结果表明,这种攻击检测策略是有效的,特别是当参数L和R很大时。
最后来看白盒攻击的防御结果。
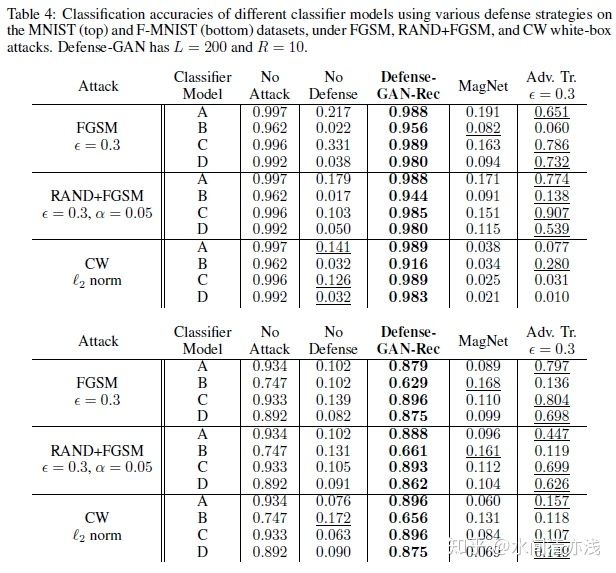
结果表明,Defense-GAN明显优于其他两个防御。甚至让对抗攻击者访问z的随机初始化。但是,这与当攻击者不知道初始化时,性能没有太大变化。
最后总结一下。在本文中,作者提出了Defense-GAN,一种利用GAN来增强分类模型对黑盒和白盒对抗性攻击的鲁棒性的新型防御策略。我们的方法不假设特定的攻击模型,并且被证明对最常见的攻击策略有效。我们凭经验表明,Defense-GAN始终为两个基准计算机视觉数据集提供足够的防御,而其他方法在至少一种类型的攻击中存在许多缺点。
在这里,有个问题要注意。Defense-GAN的成功依赖于GAN的表现力和生成力。然而,训练GAN仍然是一项具有挑战性的任务,也是一个活跃的研究领域,如果GAN没有得到适当的训练和调整,则Defense-GAN的性能将受到原始样本和对抗样本的影响。此外,超参数L和R的选择对于防御的有效性也是至关重要的,并且在不知道攻击的情况下调整它们可能是具有挑战性的。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Defense-GAN——防御对抗样本,本质上就是在用类似编码解码器(论文用了GAN)来进行表征学习,使得算法模型更健壮 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
