参考资料:
1、https://github.com/dragen1860/TensorFlow-2.x-Tutorials
2、《Generative Adversarial Net》
直接介绍GAN可能不太容易理解,所以本次会顺着几个具体的问题讨论并介绍GAN(个人理解有限,有错误的希望各位大佬指出),本来想做代码介绍的,但是关于eriklindernoren的GAN系列实现已经有很多博主介绍过了,所以就不写了。
如果你对GAN的基本知识不太了解,建议先看看莫烦的介绍:https://mofanpy.com/tutorials/machine-learning/gan/
注:图片刷不出来可能需要fq,最近jsdelivr代理好像挂了。
1、什么是GAN
GAN是一种生成网络
区别于以往使用的RNN、CNN等网络,GAN不是将数据与结果根据某种关系联系起来,而是使用一堆随机数去生成想要的结果
GAN中同时训练着两个模型:一个是生成器(Generator),另一个是判别器(Discriminator)。
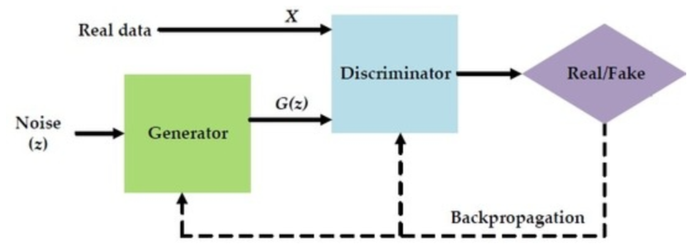
生成器通过随机数来生成结果(有可能是图片,也有可能是其他的),这里我们把生成的结果称为"生成数据",我们的目标结果称为"真实数据"。
之后,生成数据和真实数据会被同时送给判别器进行区分。
GAN的训练
整体结构如下
2、GAN有什么问题
研究数据的特点是解决问题的一个前提,数据分布会直接影响到我们算法的结果
对于“通过训练,从噪声数据生成一副图片”这个问题来说,里面涉及到两种数据:噪声和真实图片
这两种数据在分布上来说是没有重合部分的
例如,真实的图片是“手写数字1”,而还没经过训练的生成器用噪声生成的图片是类似老电视上的那种白色雪花噪点(我的理解,不知道恰不恰当)
显然两者不会有数据上的重合(overlapped),在这种情况下无论生成多少张图片,我们人去看的时候总是能够区分假图片
具体来说就对应成下面的两种分布:P、Q

省略KL与JS的推导过程直接看结论:
当θ≠0(数据分布没有重合时),使用KL散度(相对熵)和JS散度不能够很好地量化训练结果
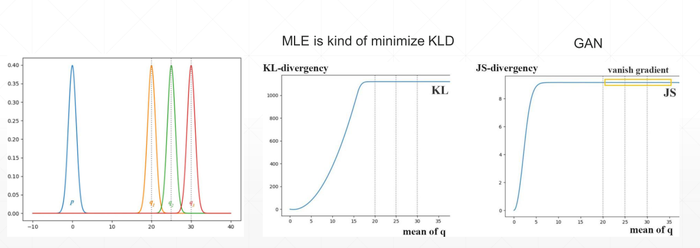
例如上图,在均值达到某一大小时,两者会变成固定常数(也就是不起作用,并且JS比KL出现时间更早),对应到现象就是出现梯度消失,没办法继续更新梯度。
再换个角度看

蓝色的是分布1,红色的是真实数据分布,不管怎么移动,只要两者没有重合,那么JS永远是log2(同一值)
也就是说,如果刚开始训练时,数据分布处于一个不好的状态,那么训练很难再进行下去
再举个例子
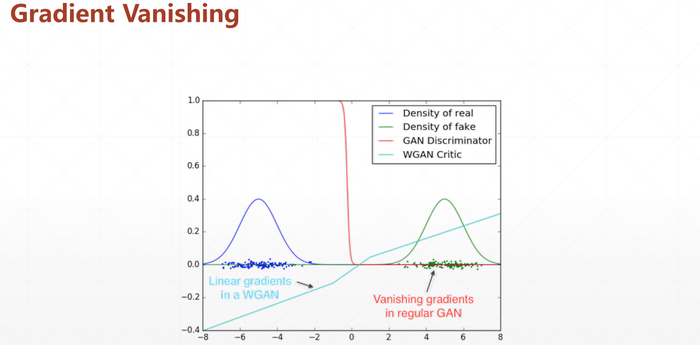
蓝色是真实数据,绿色是生成数据的分布,它们中间部分是没有重叠的
对于橙色线也就是判别器而言,他可以简单的区分出是或者不是真实数据(0/1)
但是如果一开始我们的数据分布就处于绿色区域(不利位置),那么是没办法进行判别的(无法更新)
而WGAN的评价标准(EM)可以解决这个问题,即使在不相交的位置,导数也可以起到引导作用
因此,使用EM距离来衡量训练结果便是对GAN的一个重要改进
Wasserstein距离(Wasserstei Distance)(也叫EM距离,Earth-Mover Distance)可以用于衡量两个分布之间的距离
对于没有重叠的分布同样适用,例如下面这种的
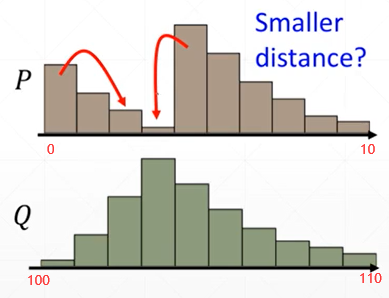
从横轴可以看出,这两个数据按照KL散度或者JS散度的标准,是完全没有重叠的
现在将问题转换一下,即使两种分布没有重叠,但是我们还可以让他们形式尽可能保持一致嘛
那么我们就可以通过"交换"上面的柱状体来实现这个目标
可以通过“交换次数”来衡量这个行为的效率
于是问题转换成了:“从P分布转换到Q分布需要几步?”
转换需要的“步数”就是代价,可以用来衡量P分布与Q分布到底有多相似
所以,即便是完全不重叠的分布,无非就是转换步骤很多而已,就说明他们非常不相关。
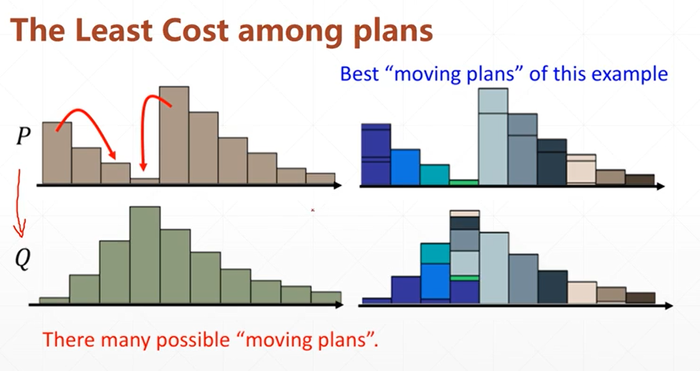
我们把柱形的移动转换类比成“铲土”,那么同样是铲,笨方法就铲的次数多,好方法步数少,于是我们会针对每个情况去计算最优的“铲土方法”,用来衡量P与Q的相似度。
所以Wasserstein距离也叫“推土机距离”
计算式如下

可以看到,GAN中使用"D"来衡量分布的接近程度
这个"D"其实就是一个使用JS散度构建的神经网络层(判别器层)
而WGAN中则是使用"f"来衡量分布
"f"则是使用WD来构建的判别器层(因为WD原来是在离散情况下的,所以这里在连续情况下使用相当于通过判别器来逼近理想的"f",因此有约束条件)
但是有个约束条件:在f上取任意的两个梯度x1、x2,他们的差必须小于1(图中经过化简了),即1-Lipschitz function
现在可以做个总结:
GAN与WGAN最主要的区别就是将JS散度换成Wasserstein距离(或者说EM距离),由此解决了GAN早期训练时因为数据重合(overlapped)度低而出现的梯度消失问题。
WGAN的训练
整体结构如下
注意:经典GAN的生成器与编码器均使用简单的全连接层构建,而其他衍生种类GAN一般使用卷积层/反卷积层代替全连接层
3、WGAN有什么问题
实现上面提到的设想的关键在于如何满足1-Lipschitz约束
WGAN 为了实现这个约束,使用了 clip 截断了判别器 weights
但这只有在权重恰好合适时能够实现(具体不推导了),并且这变相限制了这个网络的参数,进而约束了网络的表达能力。
在WGAN-gp论文中,它提到了WGAN使用clip方式所引发的问题。
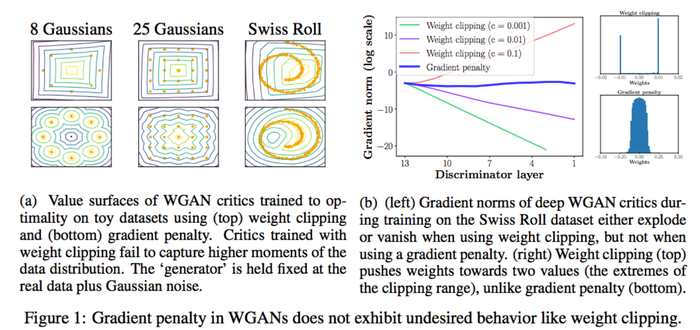
重点看看下面的右边(b)这张图,很多颜色线条那个是随着判别器层数增加, Clip 方案中梯度传导是有问题的,要么爆炸要么消失了,而 Gradient penalty 方案可以让每一层的梯度都比较稳定。
再来看看最右边的图, Clip 方案网络中 weights 参数都跑到的极端的地方,要么最大,要么最小,而 Gradient penalty 方案可以让 weights 比较均匀地分布。
WGAN-gp的训练
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【生成对抗网络学习 其一】经典GAN与其存在的问题和相关改进 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫