1.什么是Scrapy-Redis
- Scrapy-Redis是scrapy框架基于redis的分布式组件,是scrapy的扩展;分布式爬虫将多台主机组合起来,共同完成一个爬取任务,快速高效地提高爬取效率。
- 原先scrapy的请求是放在内存中,从内存中获取。scrapy-redisr将请求统一放在redis里面,各个主机查看请求是否爬取过,没有爬取过,排队入队列,主机取出来爬取。爬过了就看下一条请求。
- 各主机的spiders将最后解析的数据通过管道统一写入到redis中
- 优点:加快项目的运行速度;单个节点的不稳定性不影响整个系统的稳定性;支持端点爬取
- 缺点:需要投入大量的硬件资源,硬件、网络带宽等
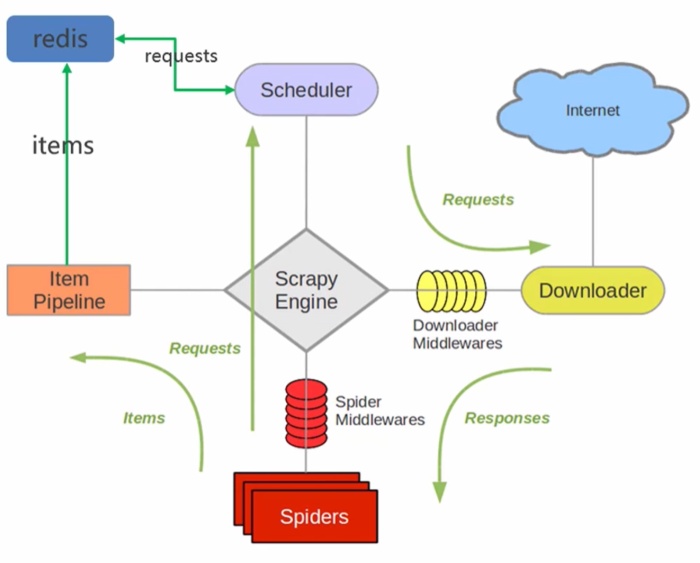
- 在scrapy框架流程的基础上,把存储request对象放到了redis的有序集合中,利用该有序集合实现了请求队列
- 并对request对象生成指纹对象,也存储到同一redis的集合中,利用request指纹避免发送重复的请求
2.Scrapy-Redis分布式策略
假设有三台电脑:Windows 10、Ubuntu 16.04、Windows 10,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
- Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储。
- Slaver端(爬虫程序执行端) :使用 Ubuntu 16.04、Windows 10,负责执行爬虫程序,运行过程中提交新的Request给Master。
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
3.Scrapy-Redis的安装和项目创建
3.1.安装scrapy-redis
pip install scrapy-redis
3.2.项目创建前置准备
- win 10
- Redis安装:redis相关配置参照这个https://www.cnblogs.com/gltou/p/16226721.html;如果跟着笔记学到这的,前面链接那个redis版本3.0太老了,需要重新安装新版本,新版本下载链接:https://pan.baidu.com/s/1UwhJA1QxDDIi2wZFFIZwow?pwd=thak,提取码:thak;
- Another Redis Desktop Manager:这个软件是用于查看redis中存储的数据,安装也很简单,一直下一步即可;下载链接:https://pan.baidu.com/s/18CC2N6XtPn_2NEl7gCgViA?pwd=ju81 提取码:ju81
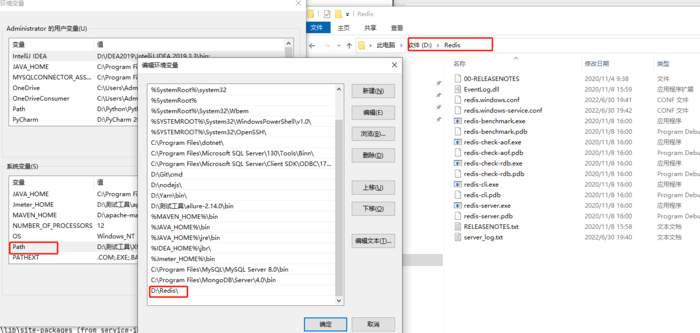
Redia安装简单讲解:安装包下载下来后,点击下一步一直安装就行,把安装路径记录好;注意安装好后需要将redis的安装目录添加到环境变量中;每当你修改了配置文件,需要重启redis时,要记得将服务重启下
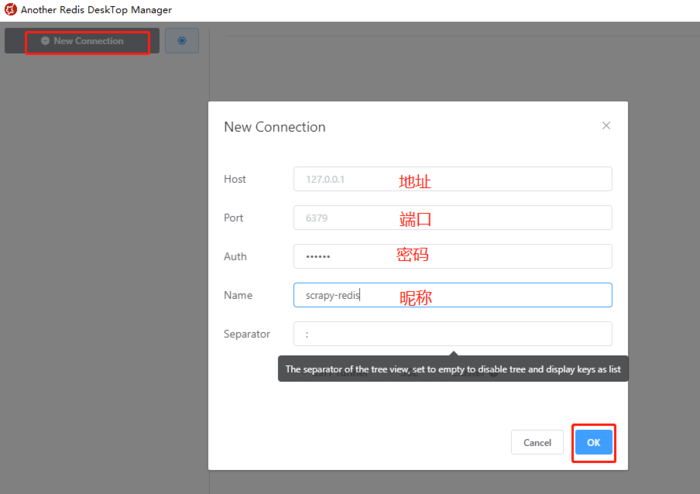
Another Redis Desktop Manager简单讲解:点击【New Connection】添加redis连接,连接内容如下(地址、端口等),密码Auth和昵称Name不是必填。
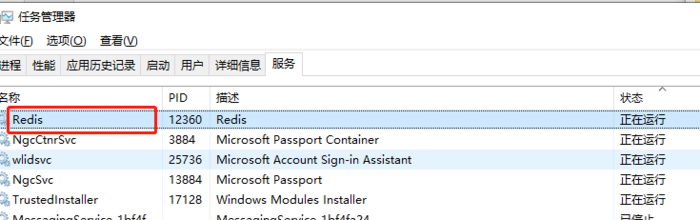
可以看到redis安装的环境、当前redis的版本、内存、连接数等信息。后面我们的笔记会讲解通过该软件查看待抓取的URL以及URL的指纹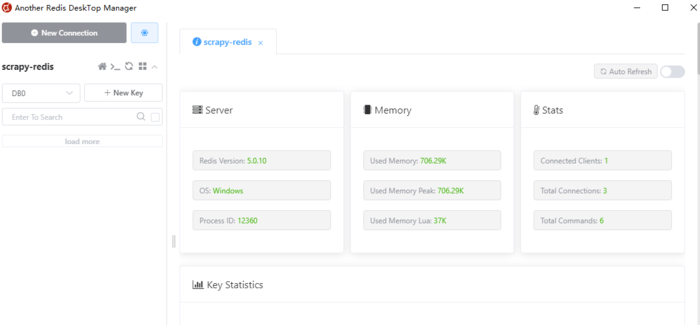
3.3.项目创建
创建普通scrapy爬虫项目,在普通的项目上改造成scrapy-redis项目;普通爬虫分为四个阶段:创建项目、明确目标、创建爬虫、保存内容;
scrapy爬虫项目创建好后,进行改造,具体改造点如下:
- 导入scrapy-redis中的分布式爬虫类
- 继承类
- 注释start_url & allowed_domains
- 设置redis_key获取start_urls
- 编辑settings文件
3.3.1.创建scrapy爬虫
step-1:创建项目
创建scrapy_redis_demo目录,在该目录下输入命令 scrapy startproject movie_test ,生成scrapy项目
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:爬虫(14) – Scrapy-Redis分布式爬虫(1) | 详解 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 