机器学习是个复杂性、专业性很强的技术领域,它大量应用到了概率论、统计学、逼近论、算法复杂度等多门学科的知识,也因此会出现很多专业性很强的词汇。
在我们探索机器学习的初级阶段,理解这些专业术语是学习过程中第一件重要任务,所以本章将详细介绍机器学习中常用的术语以及它的基本概念,为我们在后续的知识学习打下坚实的基础。
在此之前,建议大家收藏本章内容,以便在后续学习阶段复习巩固这些专业名词的含义。
机器学习术语
模型
“模型”这一名词是机器学习中最重要的核心概念。因为机器学习最终的目标就是训练出一个最优质的“模型”。可以说整个机器学习的过程都是围绕着“训练模型”这一主题展开的。
以下是机器学习整个模型训练的流程图:
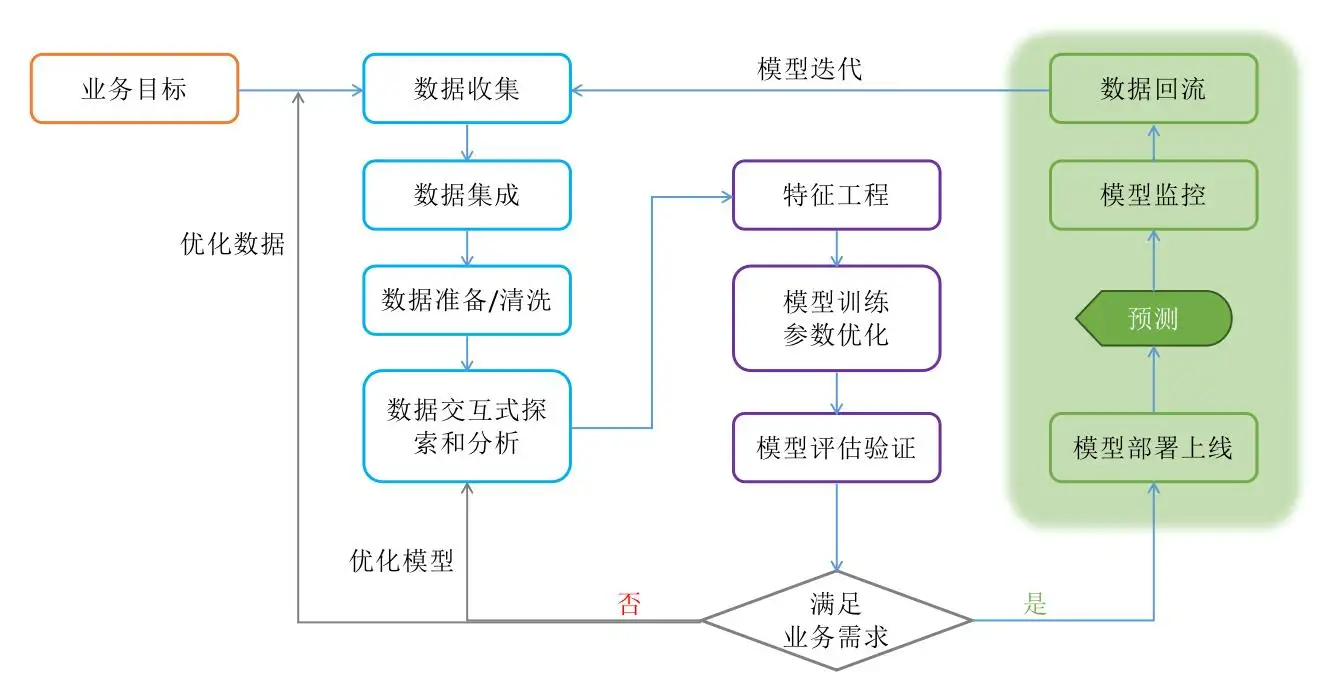
当模型训练完成后,你可以向它输入数据,它将帮你输出预测结果。预测结果越准确,说明这个模型越优质。
数据集
数据集就是一大堆数据集合,你可以把它理解成数据库层面的一个个数据表,它为训练模型提供基础数据。
根据机器学习需要,数据集分为了“训练集”和“测试集”,训练集提供机器学习训练阶段的基础数据,测试集提供机器学习预测阶段的基础数据。
样本、特征
“样本”指的是数据集中的具体数据。一条数据就是一个样本,“特征”分为“特征名”与“特征值”,是这个样本中数据的具体描述。
我们用以下用户信息数据为例。每一行都是一个样本,每一列指向这个样本的一个特征。
| 姓名 | 身高 | 年龄 |
|---|---|---|
| 张三 | 180 | 55 |
| 李四 | 175 | 23 |
由此可知,数据集的构成是“一行一样本,一列一特征”。
数学术语
矩阵
“矩阵”是一个常用的数学术语,它的作用很简单,就是将数据集以矩阵形式表现出来,你可以把它理解成电子表格,数据集的二维矩阵表现形式如下:
| 样本序号 | 特征A | 特征B | 特征C | 特征D | 结果 |
|---|---|---|---|---|---|
| 1 | a1 | a2 | a3 | a4 | b2 |
| 2 | a1 | a2 | a3 | a4 | b2 |
| 3 | a1 | a2 | a3 | a4 | b2 |
| 4 | a1 | a2 | a3 | a4 | b2 |
向量
“向量”是线性代数中的一个概念,指具有大小和方向的量。
而在机器学习中,“向量”本质上是一维数组,它用来存储某个具体实例的数据。
比如,二维空间具有x和y两个维度,那么位于其中的某个点就可以用向量存储为[x1,y1]。
同样,三维空间中的一个点具有x、y、z3个维度。二维的点可以被存储为长度为2的向量,相应地,三维的点也可以被存储为长度为3的向量,如[x1,y1,z1]。
在机器学习中,我们主要关注向量的运算。比如行列式、矩阵运算等运算规则。
假设函数&损失函数&成本函数
假设函数可以理解成一个预测方法,可用y=hθ(x)公式表达。hθ(x)函数内部使用了我们的训练模型,其中x表示输入数据,y表示输出的预测结果。
损失函数是用来判断假设函数的优劣性的。可以用L(y)表示。其中的参数y是假设函数的预测结果y,最终返回一个度量值,这个值越大表示预测结果与实际值偏差越大。
成本函数,用J表示,它用于评估一个模型的性能。
其他的还有:
-
监督学习(Supervised Learning):学习时提供有标记的数据,即数据和标签已知的数据集,以预测新数据的标签。常见的监督学习算法有线性回归、逻辑回归、决策树等。
-
无监督学习(Unsupervised Learning):学习时提供没有标记的数据,即数据没有标签的数据集,以发现数据的内在规律和结构。常见的无监督学习算法有聚类、降维等。
-
半监督学习(Semi-supervised Learning):学习时既有带标记的数据,也有没有标记的数据,以提高模型性能和泛化能力。半监督学习是监督学习和无监督学习的结合,常见的半监督学习算法有标签传播算法等。
-
强化学习(Reinforcement Learning):学习时通过观察环境和执行行动来学习如何做出最佳决策,以最大化累计奖励。强化学习是一种在动态环境中通过与环境的交互来学习的机器学习方法,常见的强化学习算法有Q-learning、深度强化学习等。
-
泛化(Generalization):模型在未见过的数据上的性能表现能力,即模型的泛化能力。
-
过拟合(Overfitting):模型过于复杂,过度拟合训练数据,在测试数据上表现不佳的现象。
-
欠拟合(Underfitting):模型过于简单,不能很好地拟合训练数据,在训练数据和测试数据上都表现不佳的现象。
-
特征(Feature):表示数据的属性,也称为属性、维度、变量等。特征的质量直接影响模型的性能。
-
样本(Sample):训练集中的单个数据点,也称为实例、数据点、观测等。
-
模型(Model):机器学习中使用的数学函数或算法,以将输入数据映射到输出数据。
-
损失函数(Loss Function):衡量模型预测值与真实值之间差异的函数,常用的损失函数有均方误差(MSE)、交叉熵等。
-
正则化:正则化是一种用于防止过拟合的技术,在损失函数中增加一个正则化项,以限制模型参数的复杂度。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:详解常用的机器学习专业术语! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫