一、普通RNN
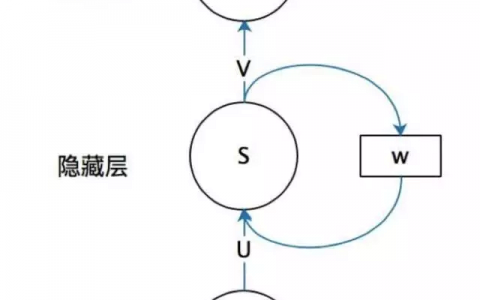
最简单的RNN网络可以看成,在全连接网络的基础上,在每一层网络中增加一个将自己层的输出连接到在自己层的输入,如下图:
")
")
对整个网络的计算方式与传统的神经网络略有不同。损失函数公式如下:就是在每个时间步计算网络输出和真实输出的损失值。所有样本、所有的时间步加起来作为征提的损失,最终的目标是使整体的损失值最小。
")
普通RNN的不足:
虽然普通的RNN结构可以得到前面时间步的信息,乐园处理序列化的数据,但目前在实际应用上,很少见到只使用基本的RNN结构,原因是普通RNN存在梯度消失和梯度爆炸的问题。
关于梯度消失和梯度爆炸,这又回到了求导链式法则上了。神经网络的在进行计算时,无非就是加法和乘法。设计网络的里面的3种计算情况:
1、函数合成
")
根据链式求导法则,求") 的导数:
的导数:
")
2、函数相加
")
根据链式求导法则,") 的导数:
的导数:
")
3、加权计算
")
求") 的导数:
的导数:
")
在反向传播残差的过程中,残差值会乘以当前节点的到数值。再有函数合成和惩罚计算的地方,残差值会发生变化,在计算假发的地方残差值不变。
") 时刻的隐藏层状态依赖于
时刻的隐藏层状态依赖于") 之前的所有时刻。在反向传播过程中,梯度需要通过所有的中间隐藏层逐时间步回传,序列长度有多少,就要回传多少“层”。
之前的所有时刻。在反向传播过程中,梯度需要通过所有的中间隐藏层逐时间步回传,序列长度有多少,就要回传多少“层”。
在神经网络的计算中,经常会用到**函数,如:sigmoid **函数:
") 其导数为:
其导数为:") 导数的最大值为:0.25。
导数的最大值为:0.25。
根据反向传播,残差在往前传播的过程中,每经过一个sigmoid函数计要乘以一个sigmoid函数的导数值,那么残差值至少削减为原来的0.25倍。这样神经网络每多一层,残差往前传递的时候,就会减少3/4,如果层数太多,残差传递到前面层的网络基本上已经为0了,这导致前面网络中的参数无法更新,这就是梯度消失。
反过来,如果每次的导数都大于 1,梯度就会越传越大,导致 参数更新幅度很大,每次参数更新都会非常剧烈,这就是梯度爆炸。梯度消失和梯度爆炸与层数有关,只要层数深的网络,都会遇到梯度消失或梯度爆炸的问题。
二、LSTM(Long Short Term Memory) 长短时间记忆
基于门控的思想,1997年,Hochreiter和 Schmidhuber提出了LSTM模型,该模型通过可以的设计来避免长期依赖问题。
普通RNN单元和LSTM单元结构如下:
")
为避免梯度消失和梯度爆炸问题,LSTM单元相对普通的RNN单元有较大的区别,核心思想有两个:
一是采用一个叫“细胞状态”的通道贯穿整个时间序列。从") 到
到") ,在这条线上的操作只有乘法操作和假发操作,加法操作不引起梯度传播的变化,加权运算只改变梯度的范围,所以在这条“细胞状态”的通道上,不会发生梯度的衰减,而其他输出值的计算依赖于“细胞状态‘的值,所以LSTM的设计就可以避免普通RNN在过长序列上的梯度消失或梯度爆炸。
,在这条线上的操作只有乘法操作和假发操作,加法操作不引起梯度传播的变化,加权运算只改变梯度的范围,所以在这条“细胞状态”的通道上,不会发生梯度的衰减,而其他输出值的计算依赖于“细胞状态‘的值,所以LSTM的设计就可以避免普通RNN在过长序列上的梯度消失或梯度爆炸。
二是通过精心设计的”门”结构来去除或者增加信息的到细胞状态的能力。
C:控制参数
决定什么样的信息会被保留,什么样的信息会被遗忘
")
")
")
")
")
")
")
三、增加peephole 的LSTM单元
除了前面说到的结构之外,LSTM单元还有很多的不同结构,例如增加peephole,让几个“门”的输入数据除了接受正常的输入数据和上一刻的输出之外,再接受“细胞状态”的输入。如下图加粗黑线的连接所示。
")
四、GRU单元
LSTM有很多变种,改动较大的是GRU单元(Gated Recuurent Unit)。它将“忘记门”和“输入门”合成了一个单一的“更新门”,同时还混合了细胞状态和隐藏状态,以及其他的一些改动。最终的模型比标准的LSTM模型简单,计算速度更快,甚至在某些应用上表现更好,是非常流行的变体。结构如下图所示:
")
GRU的计算过程,公式表示如下:
")
")
")
此篇主要总结内容来自书《Tensor flow入门与实战》这本书,作者:罗冬日;还有一部分是所看资料的的总结。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:循环神经网络:RNN(Recurrent Neural Network) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫