一位杰出的科学家曾经引用过成为自然语言处理基础的一句话:
“计算机非常快、准确和愚蠢;人类非常慢、不准确和聪明;他们在一起的力量超乎想象。” -爱因斯坦
尽管被称为最先进的自然语言处理 技术的新词嵌入技术能够在一个模型上执行多个 NLP 任务,但在这些模型出现并永远改变游戏规则之前,我们已经有了有效的信息检索方法和其他 NLP 问题,其中两种方法包括潜在语义分析(LSA)和潜在狄利克雷分配(LDA),这两种方法执行不同的任务并被广泛使用,LSA 于 2005 年推出,而 LDA 于 2003 年推出并成为一种在最强大的文本分类和摘要技术中,我们将详细讨论它的工作和应用。
潜在语义分析(LSA)
潜在语义分析是用于语义分析的自然语言处理技术之一,广义上是指我们试图借助统计的帮助从文本语料库中挖掘出一些意义,由 Jerome Bellegarde 于 2005 年提出。
LSA 基本上是一种我们从文本文档中识别模式的技术,或者简单地说,我们倾向于从文本文档中找出相关且重要的信息。如果说是有监督的方式还是无监督的方式,那显然是无监督的方式。
它是一种非常有助于矩阵降维或主题建模的技术,也称为潜在语义索引(LSI)。LSA 的主要概念和工作是将所有具有相似含义的词组合在一起。
那么它是怎样工作的?让我们看看:
LSA中词频/逆文档频率的意义
术语频率 定义为实例或关键字出现在单个文档中的次数除以该文档中的单词总数。
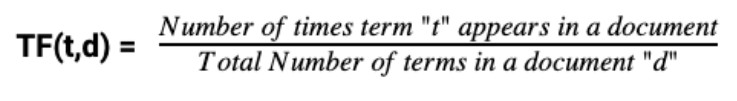
正如我们所知,文档的长度在每种情况下都不同,因此术语频率分别随着术语的出现而变化。
逆文档频率(IDF),表示该术语在文档集合中的重要性。IDF 计算文档集合中文本的稀有词项的权重。IDF 的公式为:

Tf/IDF在Latent Semantic Analysis中的主要思想是提供每个词的计数和稀有词的频率,以便根据它们的稀有性为它们提供权重,TF/IDF比传统的词出现计数更可取因为它只计算频率而没有分类。
在我们使用 TF/IDF 完成分类部分之后,我们倾向于进入下一步,即减少矩阵维度,因为通常有这么多特征,输入具有更高的维度,更高维度的输入很难理解和解释,所以为了以最大信息增益降低维度,我们有许多技术,包括奇异值分解(SVD)和主成分分析。让我们看看 SVD 在我们的第一步之后会做什么:-
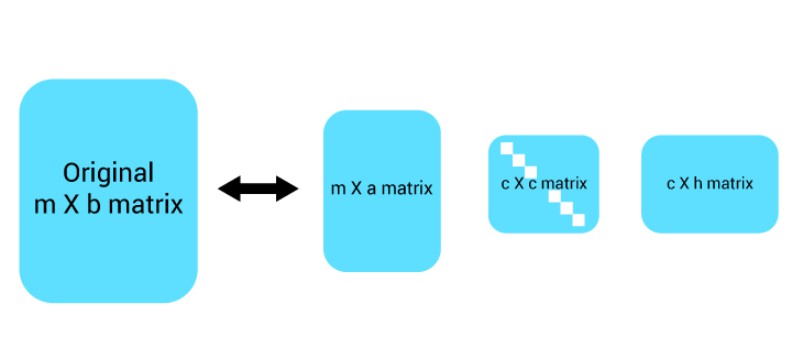
奇异值分解是一种将矩阵从高到低分解的方法,它通常将矩阵分成三个矩阵。让我们将更高维度的输入矩阵mxb作为“A”,计算 SVD 我们将使用下面给出的公式:
A(mxb) = U(mxm)。σVT
这里,σ是大小为mxn的对角矩阵, VT 是nxn正交矩阵的转置。SVD 可以执行其他几项任务,但主要在降维方面仍然有效,它被机器学习开发人员广泛使用和接受。
无论何时执行 SVD,结果总是一流的,它可以将超过 150k 的参数或维度显着减少到可以理解的 50 到 70 个参数。完成以上两个任务,就完成了潜在语义分析的动机。
LSA 有很多应用可以执行,但它主要用于搜索引擎,因为它是一种非常有用的技术,例如,您搜索“运动”,结果还显示了板球和板球运动员,这是由于 LSA 被应用于搜索引擎。LSA 的其他可能应用是文本分析中的文档聚类、推荐系统和构建用户配置文件。
潜在狄利克雷分配 (LDA)
潜在狄利克雷分配 (LDA)使用Dirichlet分布,那么Dirichlet分布是什么?它是一种概率分布,但与包括均值和方差的正态分布有很大不同,与正态分布不同,它基本上是概率的总和,它们结合在一起并相加为 1。
它有不同的 K 值,k 的数量意味着所需的概率数,例如:
- 0.6 + 0.4 = 1 (k=2)
- 0.3 + 0.5 + 0.2 = 1 (k=3)
- 0.4 + 0.2 + 0.3 + 0.1 = 1 (k=4)
所以我们可以将概率列为类别,这是它也被称为分类分布的主要原因之一。但是这个概率分布对这个方法有什么帮助呢?让我们来看看:
让我们用一句话来清楚地说明 LDA 到底做了什么:
- 我喜欢板球。
- Virat Kohli 是我最喜欢的板球运动员。
- 山是那么美丽。
- 我想参观喜马拉雅山。
上面是从不同文档中标记化的句子,现在 LDA 所做的是,它将形成集群或将句子 1 和 2 组合在一起,因为它们具有相同的上下文含义,并将 3 和 4 组合在一起以显示文档或句子之间的相似性。我希望你了解 LDA 背后的想法,现在快速开始它的工作:
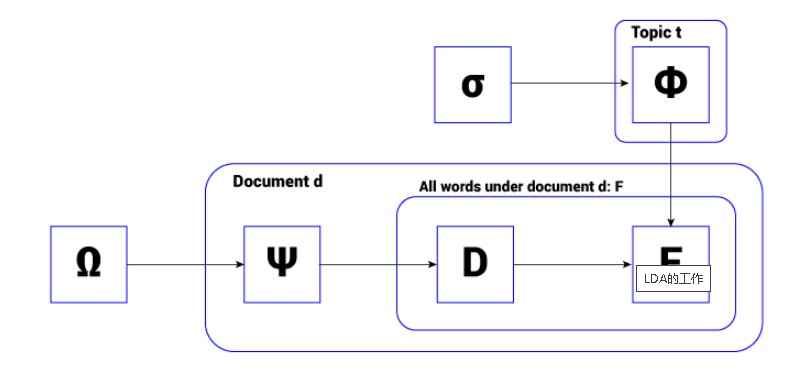
- Ω 是每个文档的主题分布
- ψ 是文档 d 的分布
- D 是文档中第 n 个词的主题
- F是选择的特定词
- Φ 是主题 t 的词分布
- σ 是每个主题的概率
上面是LDA的工作,因为我们可以观察到所有概率都是Dirichlet分布,在执行LDA或其他文本摘要方法时,我们倾向于删除所有不相关的因素,有一种方法可以删除停用词,如“the”、“are”、“is”、“with”等。这些停用词对文档聚类没有价值,需要删除。
LDA 由David Blei、Andrew Ng和Michael I. Jordan于 2003 年提出,与 LSA 一样也是一种无监督学习。它还具有LDA2vec 模型,以便预测与 word2vec 相同的序列中的另一个词,因此它成为下一个词预测中的有效技术。
LDA的应用
-
在Gensim、VW 和 mallet的大量数据集上取得了惊人的结果,从而获得了很高的准确性。
-
寻找关联或区分场景的模式,或者一般而言,有助于在两个文档之间进行模式识别。
-
主题建模的大部分研究都是在 Dirichlet 分布的帮助下完成的,这也有助于开发一些新算法。
-
它的应用之一还包括网络分析,其中包括网络模式分析和分类网络混合分析。
虽然有很多NLP 技术可以在更大的数据集上表现得更好,但我个人认为对于初学者来说,传统的 NLP 方法更好,因为它们在较小的数据集上表现更好并且易于实现,所以所有初学者都应该尝试实施这些文本摘要技术,应该缓慢而优雅地向前推进。有关分析、机器学习、深度学习、人工智能、自然语言处理和新技术的更多博客,请阅读分析步骤。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:潜在语义分析(LSA)和 潜在狄利克雷分配 (LDA)简介 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
