摘要
点云是一种重要的几何数据结构类型。由于其不规则的格式,大多数研究人员将此类数据转化为常规的三维体素网格或图像集合。然而,这使数据变得不必要的庞大,并导致问题。在本文中,我们设计了一种新型的直接处理点云的神经网络,它很好地考虑了点在输入中的排列不变性。我们的网络名为PointNet,为从目标分类、部分分割到场景语义分析等应用提供了一个统一的架构。虽然简单,但PointNet是非常高效和有效的。从经验上看,它表现出了与现有技术相当甚至更好的性能。从理论上讲,我们提供了分析,以了解网络学到了什么,以及为什么网络对输入扰动和损坏具有鲁棒性。
1、绪论
在本文中,我们探索了能够推理3D几何数据(如点云或网格)的深度学习架构。典型的卷积架构需要高度规则的输入数据格式,如图像网格或三维体素的格式,以便进行权重共享和其他内核优化。由于点云或网格不是常规格式,大多数研究人员在将这些数据送入深度网架构之前,通常会将其转化为常规的三维体素网格或图像集合(例如,视图)。但是,这种数据表示转换会使结果数据变得不必要的庞大,同时还会引入量化伪像,掩盖数据的不变性。
因此,我们将重点放在使用简单的点云的3D几何体的不同输入表示上,并将我们得到的深网命名为PointNet。出于这个原因,我们专注于使用简单的点云对3D几何进行不同的输入表示--并将我们产生的深度网络命名为PointNet。点云是简单而统一的结构,避免了网格的组合不规则性和复杂性,因此更容易学习。然而,PointNet仍然必须尊重这样一个事实,即点云只是一组点,因此对其成员的排列是不变的,这就需要在网计算中进行某些对称化。还需要考虑刚体运动的不变性。
我们的PointNet是一个统一的架构,直接将点云作为输入和输出,要么是整个输入的类别标签,要么是输入的每个点的分割/部分标签。我们网络的基本架构非常简单,因为在初始阶段,每个点的处理都是相同和独立的。在基本设置中,每个点仅由其三个坐标\((x,y,z)\)表示。可以通过计算法线和其他局部或全局特征来增加额外的维度。我们方法的关键是使用单个对称函数,即最大池化。网络有效地学习一组优化函数/标准,这些函数/标准选择点云中感兴趣的或信息丰富的点,并编码选择它们的原因。最终的网络全连接层将这些学习到的最优值聚合到全局描述符中,为整个形状(形状分类)或用于预测每个点标签(形状分割)。
图1、PointNet的应用。我们提出了一种新的网络架构,它使用原始点云(点集),而无需体素化或渲染。它是一个学习全局和局部点特征的统一体系结构,为许多3D识别任务提供了一种简单、高效和有效的方法。
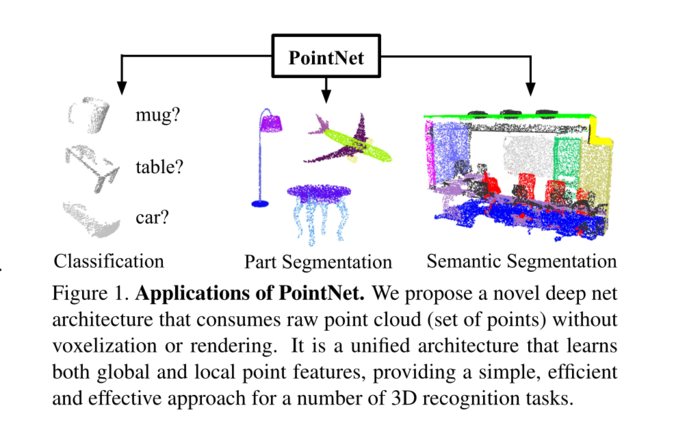
我们的输入格式很容易应用刚性(就是刚体变换)或仿射变换,因为每个点独立变换。因此,我们可以添加一个数据相关的空间变换网络,在PointNet处理数据之前尝试规范化数据,以便进一步改善结果。
我们提供了理论分析和实验评估我们的方法。我们证明了我们的网络可以逼近任何连续的集合函数。更有意思的是,原来我们的网络是通过一组稀疏的关键点来学习概括一个输入点云,根据可视化大致对应物体的骨架。理论分析提供了一个理解,为什么我们的PointNet对输入点的小扰动以及通过点插入(异常值)或删除(丢失数据)造成的损坏具有高度鲁棒性。在从形状分类、部分分割到场景分割的大量基准数据集上,我们实验性地将我们的PointNet与基于多视图和体积表示的最先进方法进行了比较。在统一架构下,我们的PointNet不仅速度快得多,而且表现出与现有技术相当甚至更好的强大性能。
我们工作的主要贡献如下:
- 我们设计了一种新型的深度网络架构,适用于在3D中使用无序点集;
- 我们展示了如何训练这样的网络来执行3D形状分类、形状部分分割和场景语义解析任务;
- 我们对我们方法的稳定性和有效性进行了深入的实证和理论分析;
- 我们举例说明了网络中所选神经元计算的3D特征,并对其性能进行了直观的解释。
通过神经网络处理无序集合的问题是一个非常普遍和基本的问题——我们希望我们的想法也可以应用到其他领域。
2、相关工作
点云特征 大多数现有的点云功能都是针对特定任务手工制作的。点特征通常对点的某些统计属性进行编码,并被设计为对某些转换保持不变,这些转换通常被分类为内在的[2, 24, 3]或外在的[20, 19, 14, 10, 5]。它们也可以分为局部特征和全局特征。对于特定任务,找到最佳特征组合并非易事。
3D数据的深度学习 3D数据具有多种流行的表示形式,引导了各种学习方法。Volumetric CNNs:[28,17,18] 是将3D卷积神经网络应用于体素化形状的先驱。然而,由于数据稀疏性和3D卷积的计算成本,体积表示受到其分辨率的限制。FPNN[13]和Vote3D[26]提出了处理稀疏问题的特殊方法;然而,他们的操作仍然在稀疏的体积上,处理非常大的点云对他们来说是一个挑战。Multiview CNNs:[23, 18]尝试将3D点云或形状渲染为2D图像,然后应用2D卷积网络对它们进行分类。通过精心设计的图像CNN,这一系列方法已经在形状分类和检索任务上取得了主导性能[21]。然而,将它们扩展到场景理解或其他3D任务(如点分类和形状补全)是很重要的。Spectral CNNs:一些最新的工作[4,16]在网格上使用谱CNN。然而,这些方法目前仅限于流形网格,如organic物体,如何将它们扩展到非等距形状,如家具,并不明显。基于特征的DNN:[6, 8] 首先将3D数据转换为向量,通过提取传统的形状特征,然后使用全连接网络对形状进行分类。我们认为它们受到所提取特征的表示能力的限制。
无序集合的深度学习 从数据结构的角度来看,点云是一组无序的向量。 虽然深度学习的大多数工作都集中在常规的输入表示上,比如序列(在语音和语言处理中)、图像和体积(视频或3D数据),但在点集的深度学习方面做的工作并不多。
Oriol Vinyals等人[25]最近的一项工作研究了这个问题。 他们使用一个具有注意力机制的read-process-write网络来处理无序的输入集,并表明他们的网络有能力对数字进行排序。然而,由于他们的工作集中在通用集合和NLP应用程序上,因此集合中缺乏几何体的作用。
3、问题陈述
我们设计了一个深度学习框架,直接使用无序点集作为输入。点云被表示为一组3D点\(\left\{P_{i} \mid i=1, \ldots, n\right\}\),其中每个点\(P_{i}\)是其\((x,y,z)\)坐标加上额外的特征通道(例如颜色、法线等)的向量。为了简单明了,除非另有说明,我们只使用\((x,y,z)\)坐标作为点的通道。
对于目标分类任务,输入点云要么直接从形状采样,要么从场景点云预分割。 我们提出的深度网络输出所有\(k\)个候选类的\(k\)个分数。 对于语义分割,输入可以是用于部分区域分割的单个目标,也可以是用于目标区域分割的三维场景的子体积。 我们的模型将为每个\(n\)点和每个\(m\)语义子类别输出\(n×m\)分数。
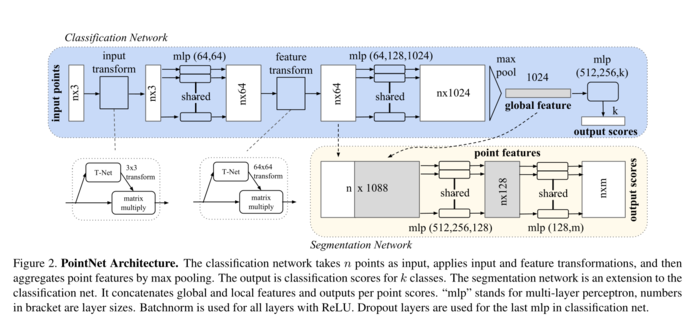
图2、PointNet架构。分类网络将n个点作为输入,应用输入和特征变换,然后通过最大池化聚合点特征。输出是k个类别的分类分数。分割网络是分类网络的扩展。它连接全局和局部特征并输出每点分数。“mlp”代表多层感知器,括号中的数字是层大小。 Batchnorm用于所有带有ReLU的层。Dropout层用于分类网络中的最后一个mlp。
4、点集的深度学习
我们网络的架构(第 4.2 节)受到\(\mathbb{R}^{n}\)中点集性质的启发(第 4.1 节)。
4.1、\(\mathbb{R}^{n}\)中点集的性质
我们的输入是来自欧几里得空间的点的子集。它具有三个主要性质:
- 无序。 与图像中的像素阵列或体积网格中的体素阵列不同,点云是一组没有特定顺序的点。换句话说,一个处理\(N\)个3D点集的网络需要在数据输入顺序上对输入集的\(N !\)排列保持不变。
- 点之间的相互作用。 这些点来自具有距离度量的空间。这意味着点不是孤立的,相邻点形成一个有意义的子集。因此,模型需要能够从附近的点捕捉局部结构,以及局部结构之间的组合相互作用。
- 变换下的不变性。 作为一个几何目标,点集的学习表示对于某些变换应该是不变的。例如,所有的点旋转和平移不应修改全局点云类别,也不应修改点的分段。
4.2、PointNet架构
我们的完整网络架构如图2所示,其中分类网络和分割网络共享很大一部分结构。 请阅读图2中pipeline的说明。
我们的网络有三个关键模块:作为对称函数聚合所有点信息的max pooling层、局部和全局信息组合结构,以及用于对齐输入点和点要素的两个联合对齐网络。
我们将在下面单独的段落中讨论这些设计选择背后的原因。
无序输入的对称函数 为了使模型对输入排列不变,存在三种策略:1)将输入的内容整理成一个规范的顺序。2)将输入作为一个序列来训练RNN,但通过各种排列组合来增加训练数据。3)使用简单的对称函数来聚集来自每个点的信息。这里,对称函数将n个向量作为输入,并输出一个对输入顺序不变的新向量。例如,+ 和 * 运算符是对称二元函数。
虽然排序听起来是一个简单的解决方案,但在高维空间中,事实上并不存在一个在一般意义上对点扰动稳定的排序。这很容易通过矛盾表现出来。如果存在这样的排序策略,它定义了一个高维空间和\(1d\)实线之间的双射映射。不难看出,要求排序对于点扰动是稳定的,相当于要求该地图在维度减小时保持空间接近度,这是一般情况下无法完成的任务。因此,排序并不能完全解决排序问题,而且随着排序问题的持续,网络很难从输入到输出获得一致的映射。如实验所示(图5),我们发现将MLP直接应用于分类后的点集表现不佳,尽管比直接处理未分类的输入稍好。使用RNN的想法将点集视为一个序列信号,并希望通过用随机排列的序列训练RNN,RNN将变得对输入顺序不变。然而,在“OrderMatters”[25] 中,作者已经表明顺序确实很重要,不能完全省略。虽然RNN对于小长度(几十个)的序列的输入排序具有相对较好的鲁棒性,但它很难扩展到数千个输入元素,而这是点集的常见大小。根据经验,我们还表明,基于RNN的模型不如我们提出的方法表现好(图5)。我们的想法是通过对集合中的变换元素应用对称函数来近似定义在点集上的一般函数:
\]
,其中\(f: 2^{\mathbb{R}^{N}} \rightarrow \mathbb{R}, h: \mathbb{R}^{N} \rightarrow \mathbb{R}^{K}\)和\(g:\underbrace{\mathbb{R}^{K} \times \cdots \times \mathbb{R}^{K}}_{n} \rightarrow \mathbb{R}\)是对称函数。
根据经验,我们的基本模块非常简单:我们用多层感知器网络近似\(h\),用单变量函数和最大池化函数的组合来估算\(g\)。 实验证明,这种方法效果良好。通过\(h\)的集合,我们可以学习一些\(f\)来获取集合的不同属性。
虽然我们的关键模块看起来很简单,但它具有有趣的特性(见第5.3节),可以在一些不同的应用中实现强大的性能(见第5.1节)。由于我们模块的简单性,我们也能够像第4.3节那样提供理论分析。
局部和全局信息聚合 上述部分的输出形成一个向量\(\left[f_{1}, \ldots, f_{K}\right]\),它是输入集的全局签名。 我们可以很容易地在形状全局特征上训练SVM或多层感知器分类器进行分类。 然而,点分割需要结合局部和全局信息。我们可以通过简单而高效的方式实现这一点。
我们的解决方案如图2(分段网络)所示。 在计算全局点云特征向量后,我们通过将全局特征与每个点特征连接起来,将其反馈给每个点特征。 然后,我们基于组合点特征提取新的每点特征——这一次,每点特征同时感知局部和全局信息。
通过这种修改,我们的网络能够预测依赖于局部几何和全局语义的每个点的数量。例如,我们可以准确预测每个点的法线(补充图中的图),验证网络是否能够汇总来自点的局部邻域的信息。在实验环节中,我们还展示了我们的模型在形状部分分割和场景分割方面的最新性能。
联合校准网络 如果点云经过某些几何变换,例如刚体变换,点云的语义标记必须是不变的。因此,我们期望通过我们的点集学习的表示对这些变换是不变的。
一种自然解决方案是在特征提取之前将所有输入集对齐到规范空间。Jaderberg等人[9]引入了空间transformer的概念,通过采样和插值来对齐二维图像,由一个专门的层在GPU上实现。
与[9]相比,我们的点云输入形式使我们能够以更简单的方式实现这一目标。我们不需要创造任何新的层,也没有像图像中那样引入别名。我们通过小型网络(图2中的T-net)预测仿射变换矩阵,并将该变换直接应用于输入点的坐标。微型网络本身类似于大网络,并且由点独立特征提取、最大池化和全连接层的基本模块组成。关于T-net的更多细节在附录中。
这个想法也可以进一步扩展到特征空间的对齐。我们可以在点要素上插入另一个对齐网络,并预测要素变换矩阵来对齐来自不同输入点云的要素。然而,特征空间中的变换矩阵比空间变换矩阵维数高得多,这大大增加了优化的难度。因此,我们在softmax训练损失中增加了一个正则项。我们将特征变换矩阵约束为接近正交矩阵:
\]
其中\(A\)是由微型网络预测的特征对准矩阵。正交变换不会丢失输入中的信息,因此是所期望的。我们发现,通过加入正则项,优化变得更加稳定,我们的模型实现了更好的性能。
4.3、理论分析
通用近似 我们首先展示了我们的神经网络对连续集函数的通用近似能力。通过集合函数的连续性,直观地,对输入点集的小扰动应该不会极大地改变函数值,例如分类或分割分数。
形式上,设\(\mathcal{X}=\left\{S: S \subseteq[0,1]^{m}\right.\) and \(\left.|S|=n\right\}, f:\mathcal{X} \rightarrow \mathbb{R}\)是\(\mathcal{X}\)上关于Hausdorff距离(Hausdorff距离可以理解成一个点集中的点到另一个点集的最短距离的最大值。)\(d_{H}(\cdot, \cdot)\), i.e., \(\forall \epsilon>0, \exists \delta>0\)的连续集函数,对任意\(S, S^{\prime} \in \mathcal{X}\),若\(d_{H}\left(S, S^{\prime}\right)<\delta\),则\(\left|f(S)-f\left(S^{\prime}\right)\right|<\epsilon\)。我们的定理说,在最大池化层给定足够的神经元,即(1)中的\(K\)足够大,\(f\)可以由我们的网络任意估算。
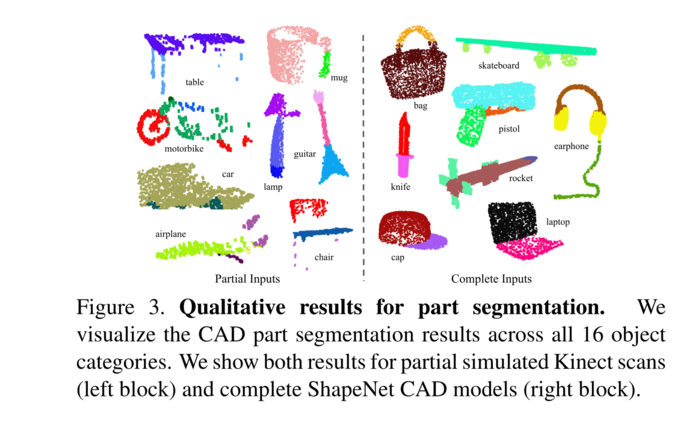
图3、部分分割的定性结果。我们可视化所有16个目标类别的CAD部分分割结果。我们展示了部分模拟Kinect扫描(左块)和完整ShapeNet CAD 模型(右块)的结果。
定理1。假设\(f: \mathcal{X} \rightarrow \mathbb{R}\)是关于Hausdorff距离\(d_{H}(\cdot, \cdot) . \quad \forall \epsilon>0\)的连续集函数,\(∃\)一个连续函数\(h\)和一个对称函数\(g\left(x_{1}, \ldots, x_{n}\right)=\gamma \circ M A X\),对于任何\(S \in \mathcal{X}\),
\]
其中\(x_{1}, \ldots, x_{n}\)是\(S\)中任意排序的元素的完整列表,\(γ\)是一个连续函数,MAX是一个向量\(max\)运算符,它以\(n\)个向量作为输入,并返回元素最大值的新向量。
这个定理的证明可以在我们的补充材料中找到。关键思想是,在最坏的情况下,网络可以通过将空间划分为相等大小的体素,来学习将点云转换为体积表示。然而,在实践中,网络学会了一种更智能的策略来搜寻空间,正如我们将在point函数可视化中看到的。
瓶颈维度与稳定性 从理论上和实验上,我们发现我们的网络的表达能力受到最大池化层的维度,即\(K\)在(1)中的影响。在这里,我们提供了一个分析,这也揭示了与我们的模型稳定性相关的属性。 我们将\(\mathbf{u}=\underset{x_{i} \in S}{\operatorname{MAX}}\left\{h\left(x_{i}\right)\right\}\)定义为\(f\)的子网络,它将\([0,1]^{m}\)中的一个点集映射到\(K\)维向量。以下定理告诉我们,输入集中的损坏较小或额外噪声点不太可能改变网络的输出:
定理2 假设\(\mathbf{u}: \mathcal{X} \rightarrow \mathbb{R}^{K}\)满足于\(\mathbf{u}= \underset{x_{i} \in S}{\operatorname{MAX}}\left\{h\left(x_{i}\right)\right\}\)和\(f=\gamma \circ \mathbf{u}\)条件,那么,
(a) \(\forall S, \exists \mathcal{C}_{S}, \mathcal{N}_{S} \subseteq \mathcal{X}, f(T)=f(S)\) if \(\mathcal{C}_{S} \subseteq T \subseteq \mathcal{N}_{S}\)
(b) \(\left|\mathcal{C}_{S}\right| \leq K\)
我们解释这个定理的含义。(a)表示如果\(\mathcal{C}_{S}\)中的所有点都被保留,\(f(S)\)在输入损坏之前保持不变;它也保持不变,额外的噪声点达到\(\mathcal{N}_{S}\)。 (b)表示\(\mathcal{C}_{S}\)仅包含有限数量的点,由(1)中的\(K\)确定。换句话说,\(f(S)\)实际上完全由小于或等于\(K\)个元素的有限子集\(\mathcal{C}_{S} \subseteq S\)决定。 因此,我们称\(\mathcal{C}_{S}\)为\(S\)的临界点集,称\(K\)为\(f\)的瓶颈维数。
结合\(h\)的连续性,这解释了我们的模型在点扰动、腐败和额外的噪声点方面的稳健性。类似于机器学习模型中的稀疏性原理,获得了鲁棒性。直观地说,我们的网络学习通过一组稀疏的关键点来总结形状。在实验部分,我们看到关键点构成了一个目标的骨架。
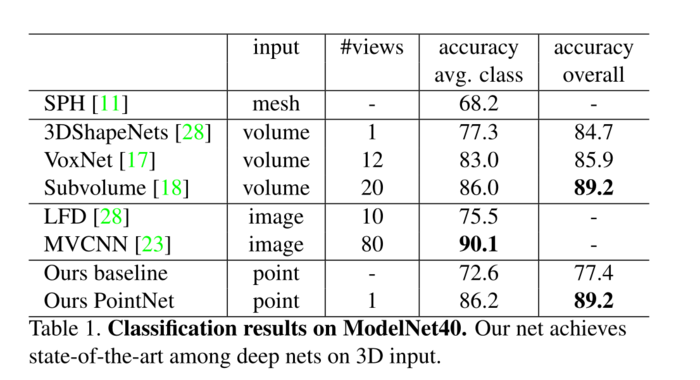
表1、ModelNet40上的分类结果。我们的网络在3D输入的深度网络中达到了最先进的水平。
5、实验
实验分为四个部分。首先,我们展示了PointNet可以应用于多个3D识别任务(第5.1节)。 其次,我们提供详细的实验来验证我们的网络设计(第5.2节)。 最后,我们将网络学习的内容可视化(第5.3节),并分析时间和空间复杂性(第5.4节)。
5.1、应用
在本节中,我们将展示如何训练我们的网络来执行3D目标分类、目标部分分割和语义场景分割。尽管我们正在研究一种全新的数据表示(点集),但我们能够在多个任务的基准测试中获得相当甚至更好的性能。
3D物体分类 我们的网络学习可用于目标分类的全局点云特征。 我们在ModelNet40[28]形状分类基准上评估我们的模型。共有来自40个人造物体类别的12311个CAD模型,分为9843个用于训练,2468个用于测试。虽然以前的方法侧重于体积和多视图图像表示,但我们是第一个直接处理原始点云的方法。
我们根据面面积对网格面上的1024个点进行统一采样,并将它们规格化为一个单位球体。 在训练过程中,我们通过沿上轴随机旋转目标,并通过具有零均值和0.02标准偏差的高斯噪声抖动每个点的位置,来实时增加点云。
在表1中,我们将我们的模型与以前的工作以及我们的基线进行了比较,我们使用MLP对从点云提取的传统特征(点密度、D2、形状轮廓等)进行了比较。).我们的模型在基于3D输入(体积和点云)的方法中实现了最先进的性能。由于只有全连接层和最大池化,我们的网络在推理速度上获得了强大的领先优势,并且可以很容易地在CPU中并行化。在我们的方法和基于多视图的方法(MVCNN [23])之间仍然有一个小的差距,我们认为这是由于渲染图像可以捕获的精细几何细节的损失。
3D目标部分分割 部分分割是一项具有挑战性的细粒度3D识别任务。给定3D扫描或网格模型,任务是为每个点或面分配部分类别标签(例如椅子腿、杯柄)。
我们评估了来自[29]的ShapeNet部分数据集,其中包含来自16个类别的16,881个形状,总共注释了50个部分。大多数目标类别都标有两到五个部分。真值注释标注在形状采样点上。
我们将目标分割描述为逐点分类问题。我们将部分分割描述为逐点分类问题。 对于C类的每个形状S,要计算形状的mIoU: 对于C类中的每种部分类型,计算出基本事实和预测之间的IoU。 如果真实值相和预测点的并集为空,则将部分IoU计算为1。 然后我们对C类中所有部分类型的IOU进行平均,得到该形状的mIoU。为了计算类别的mIoU,我们取该类别中所有形状的mIoU的平均值。 在本节中,我们将我们的分割版本PointNet(图2的修改版本,分割网络)与两种传统方法[27]和[29]进行比较,这两种方法都利用了逐点几何特征和形状之间的对应关系,以及我们自己的3D CNN基线。
有关3D CNN的详细修改和网络架构,请参见补充说明。在表2中,我们报告了每个类别和平均IoU(%)分数。 我们观察到平均IoU改善了2.3%,我们的净改善率超过了大多数类别的基线方法。
表2、ShapeNet部分数据集的分割结果。度量标准是点上的mIoU(%)。我们与两种传统方法[27]和[29]以及我们提出的3D全卷积网络基线进行比较。我们的PointNet方法在mIoU中达到了最先进的水平。
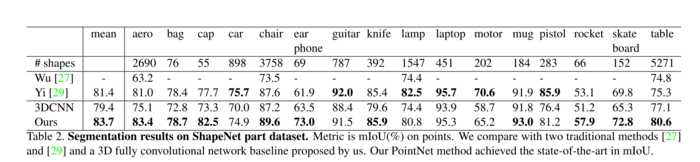
我们还对模拟Kinect扫描进行了实验,以测试这些方法的鲁棒性。对于ShapeNet部分数据集中的每个CAD模型,我们使用Blensor Kinect Simulator[7]从六个随机视点生成不完整的点云。 我们使用相同的网络架构和训练设置在完整的形状和部分扫描上训练我们的PointNet。结果表明,我们只损失了5.3%的平均IoU。在图3中,我们给出了完整数据和部分数据的定性结果。可以看出,虽然部分数据相当具有挑战性,但我们的预测是合理的。
场景中的语义分割 我们的部分分割网络可以很容易地扩展到语义场景分割,其中点标签成为语义目标类而不是目标部分标签。
我们在斯坦福3D语义解析数据集[1]上进行实验。该数据集包含来自6个区域(包括271个房间)的Matterport扫描仪的3D扫描。扫描中的每个点都用来自13个类别(椅子、桌子、地板、墙壁等加上杂乱)的语义标签之一进行注释。
为了准备训练数据,我们首先按房间分割点,然后将房间采样成面积为1m x 1m的块。我们对PointNet的分段版本进行训练,以预测每个块中的每个点类。
表3、场景中语义分割的结果。指标是13个类别(结构和家具元素加上杂乱)的平均IoU和基于点计算的分类精度。
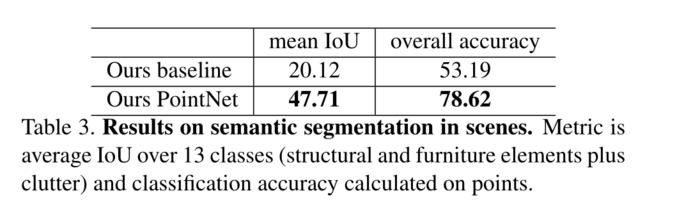
表4、场景中3D目标检测的结果。指标是在3D体积中计算的阈值IoU0.5的平均精度。
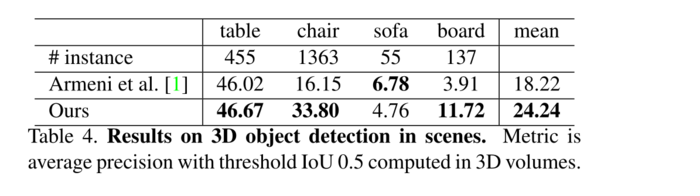


图4、语义分割的定性结果。顶行是带颜色的输入点云。底行是在与输入相同的相机视点中显示的输出语义分割结果(在点上)。
每个点由XYZ、RGB和房间的归一化位置(从 0 到 1)的9维向量表示。在训练时,我们在每个块中随机抽取 4096 个点。在测试时,我们对所有点进行测试。我们遵循与 [1] 相同的协议,使用k-fold策略进行训练和测试。
我们将我们的方法与使用手工点特征的基线进行比较。基线提取相同的9维局部特征和三个附加特征:局部点密度、局部曲率和法向量。我们使用标准MLP作为分类器。结果如表3所示,其中我们的PointNet方法明显优于基线方法。在图4中,我们显示了定性分割结果。我们的网络能够输出平滑的预测,并且对于缺失点和遮挡是鲁棒的。基于从我们的网络输出的语义分割,我们进一步使用用于目标proposal的连接组件来构建3D目标检测系统(细节参见补充)。我们在表4中与以前的最先进的方法进行了比较。前一种方法是基于滑动形状方法(具有CRF后处理),使用在体素网格中的局部几何特征和全局房间上下文特征上训练的SVM。我们的方法在报道的家具类别上远远超过它。
5.2、结构设计分析
在本节中,我们通过控制实验来验证我们的设计选择。我们还显示了我们的网络的超参的影响。
与其他顺序不变方法的比较 如4.2节所述,至少有三种选择来处理无序的集合输入。我们使用ModelNet40形状分类问题作为比较这些选项的测试平台,以下两个操作实验也将使用此任务。
我们比较的基线(如图5所示)包括未排序和排序点上的多层感知器(n×3阵列)、将输入点视为序列的RNN模型,以及基于对称函数的模型。我们实验的对称操作包括最大池化、平均池化和基于注意力的加权和。注意力方法类似于[25]中的方法,其中从每个点特征预测标量分数,然后通过计算softmax对分数进行归一化。然后根据归一化分数和点特征计算加权和。如图5所示,max pooling操作以较大的优势获得了最佳性能,这验证了我们的选择。
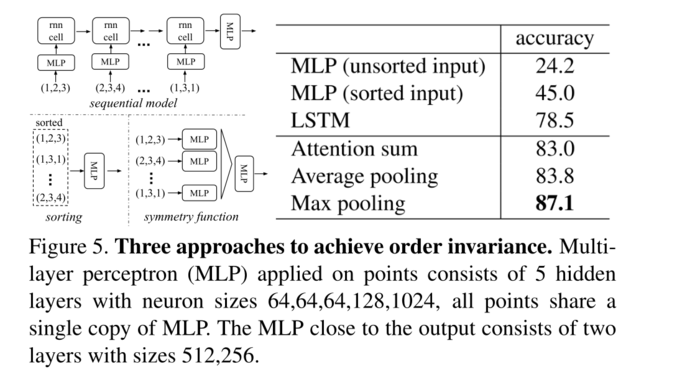
图5、实现顺序不变性的三种方法。应用于点的多层感知器(MLP)由5个隐藏层组成,神经元大小为64、64、64、128、1024,所有点共享一个 MLP副本。靠近输出的 MLP 由大小为 512,256的两层组成。
输入和特征转换的有效性 在表5中,我们展示了我们的输入和特征转换(用于对齐)的积极效果。有趣的是,最基本的架构已经取得了相当合理的结果。使用输入转换可以提高0.8%的性能。正则化损失是高维变换工作所必需的。通过结合变换和正则项,我们获得了最佳性能。
鲁棒性测试 我们展示了我们的PointNet,虽然简单有效,但对各种输入损坏具有鲁棒性。我们使用与图5的最大池化网络相同的架构。输入点被归一化为一个单位球体。结果如图6所示。
至于缺失点,当有 50% 的点缺失时,相对于最远和随机输入采样,准确率仅下降2.4%和3.8%。如果我们的网络在训练期间看到了异常点,那么它对异常点也很鲁棒。我们评估了两个模型:一个在具有(x, y, z)坐标的点上训练;另一个在(x, y, z)加上点密度。即使 20%的点是异常值,网络的准确率也超过80%。图6右侧显示了网络对点扰动的鲁棒性。
表5、输入特征变换的影响。 Metric是ModelNet40测试集上的整体分类准确率。
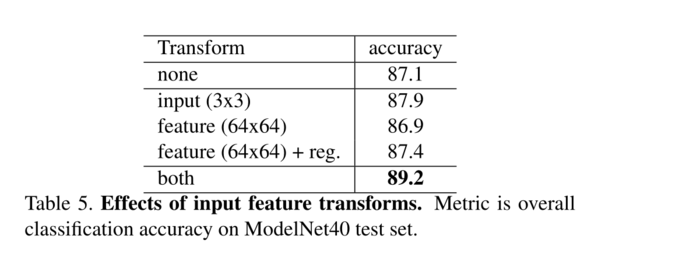
图6、PointNet稳健性测试。该指标是ModelNet40测试集上的整体分类准确率。左:删除点。最远意味着以最远采样对原始1024个点进行采样。中:插入。异常值均匀地分散在单位球面上。右:扰动。分别向每个点添加高斯噪声。
5.3、可视化PointNet
在图7中,我们可视化了一些样本形状\(S\)的临界点集\(C_{S}\)和上界形状\(N_{S}\)(如在Thm 2中讨论的)。两个形状之间的点集将给出完全相同的全局形状特征\(f(S)\)。
从图7中我们可以清楚地看到,对最大池化特征有贡献的临界点集\(C_{S}\)总结了形状的骨架。上界形状\(N_{S}\)说明了与输入点云\(S\) 给出相同全局形状特征\(f(S)\)的最大可能点云。\(C_{S}\)和\(N_{S}\)反映了PointNet的鲁棒性,这意味着丢失一些非关键点根本不会改变全局形状签名\(f(S)\)。\(N_{S}\)通过网络转发边长为2的立方体中的所有点,并选择点函数值\(\left(h_{1}(p), h_{2}(p), \cdots, h_{K}(p)\right)\)不大于全局形状描述符的点\(p\)来构建。
图7、临界点和上限形状。虽然临界点共同确定给定形状的全局形状特征,但任何落在临界点集和上限形状之间的点云都会给出完全相同的特征。我们对所有图形进行颜色编码以显示深度信息。

5.4、时空复杂度分析
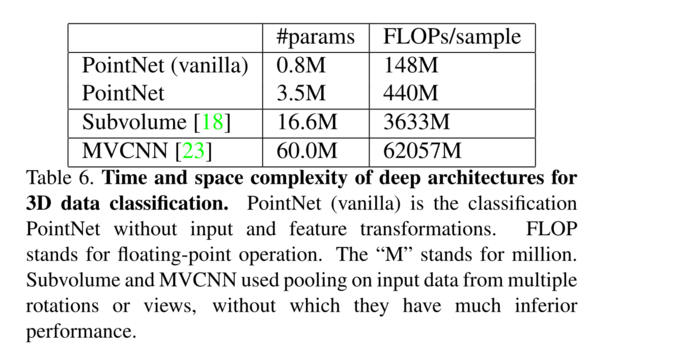
表6总结了我们的分类 PointNet 的空间(网络中的参数数量)和时间(浮点运算/样本)复杂度。我们还将PointNet与之前作品中一组具有代表性的基于体积和多视图的架构进行了比较。
虽然MVCNN[23]和Subvolume(3D CNN)[18]实现了高性能,但PointNet在计算成本方面的效率更高(以FLOPs/样本衡量:效率分别提高了141倍和8倍)。此外,就网络中的#param(参数少17倍)而言,PointNet比MVCNN更节省空间。此外,PointNet更具可扩展性——它的空间和时间复杂度为\(O(N)\)——与输入点的数量呈线性关系。然而,由于卷积在计算时间中占主导地位,多视图方法的时间复杂度在图像分辨率上成正比增长,而基于体积卷积的方法随着体积大小三次增长。
经验表明,PointNet在TensorFlow上使用1080X GPU每秒能够处理超过100万个点用于点云分类(约1K个目标/秒)或语义分割(约2个房间/秒),显示出巨大的实时应用潜力.
表6、用于3D数据分类的深度架构的时间和空间复杂度。PointNet(vanilla)是没有输入和特征转换的分类PointNet。FLOP代表浮点运算。“M”代表百万。Subvolume和MVCNN对来自多个旋转或视图的输入数据使用池化,没有它它们的性能要差得多。
6、结论
在这项工作中,我们提出了一种直接处理点云的新型深度神经网络PointNet。我们的网络为许多3D识别任务提供了统一的方法,包括目标分类、部分分割和语义分割,同时在标准基准上获得与现有技术相当或更好的结果。我们还提供理论分析和可视化,以了解我们的网络。
参考文献
[1] I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2016. 6, 7
[2] M. Aubry, U. Schlickewei, and D. Cremers. The wave kernel signature: A quantum mechanical approach to shape analysis. In Computer Vision Workshops (ICCV Workshops),2011 IEEE International Conference on, pages 1626–1633. IEEE, 2011. 2
[3] M. M. Bronstein and I. Kokkinos. Scale-invariant heat kernel signatures for non-rigid shape recognition. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 1704–1711. IEEE, 2010. 2
[4] J. Bruna, W. Zaremba, A. Szlam, and Y . LeCun. Spectralnetworks and locally connected networks on graphs. arXiv preprint arXiv:1312.6203, 2013. 2
[5] D.-Y . Chen, X.-P . Tian, Y .-T. Shen, and M. Ouhyoung. On visual similarity based 3d model retrieval. In Computer graphics forum, volume 22, pages 223–232. Wiley Online Library, 2003. 2
[6] Y . Fang, J. Xie, G. Dai, M. Wang, F. Zhu, T. Xu, and E. Wong. 3d deep shape descriptor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2319–2328, 2015. 2
[7] M. Gschwandtner, R. Kwitt, A. Uhl, and W. Pree. BlenSor:Blender Sensor Simulation Toolbox Advances in Visual Computing. volume 6939 of Lecture Notes in Computer Science, chapter 20, pages 199–208. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011. 6
[8] K. Guo, D. Zou, and X. Chen. 3d mesh labeling via deep convolutional neural networks. ACM Transactions on Graphics (TOG), 35(1):3, 2015. 2
[9] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In NIPS 2015. 4
[10] A. E. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3d scenes. IEEE Transactions on pattern analysis and machine intelligence, 21(5):433–449, 1999. 2
[11] M. Kazhdan, T. Funkhouser, and S. Rusinkiewicz. Rotation invariant spherical harmonic representation of 3 d shape descriptors. In Symposium on geometry processing, volume 6, pages 156–164, 2003. 5
[12] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner. Gradient-based learning applied to document recognition. Proceed-ings of the IEEE, 86(11):2278–2324, 1998. 13
[13] Y . Li, S. Pirk, H. Su, C. R. Qi, and L. J. Guibas. Fpnn:Field probing neural networks for 3d data. arXiv preprint arXiv:1605.06240, 2016. 2
[14] H. Ling and D. W. Jacobs. Shape classification using the inner-distance. IEEE transactions on pattern analysis and machine intelligence, 29(2):286–299, 2007. 2
[15] L. v. d. Maaten and G. Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9(Nov):2579–2605, 2008. 15
[16] J. Masci, D. Boscaini, M. Bronstein, and P . V andergheynst.Geodesic convolutional neural networks on riemannian man-ifolds. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 37–45, 2015. 2
[17] D. Maturana and S. Scherer. V oxnet: A 3d convolutional neural network for real-time object recognition. In IEEE/RSJ International Conference on Intelligent Robots and Systems,September 2015. 2, 5, 10, 11
[18] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. Guibas.Volumetric and multi-view cnns for object classification on 3d data. In Proc. Computer Vision and Pattern Recognition(CVPR), IEEE, 2016. 2, 5, 8
[19] R. B. Rusu, N. Blodow, and M. Beetz. Fast point feature histograms (fpfh) for 3d registration. In Robotics and Automation, 2009. ICRA’09. IEEE International Conference on, pages 3212–3217. IEEE, 2009. 2
[20] R. B. Rusu, N. Blodow, Z. C. Marton, and M. Beetz. Aligning point cloud views using persistent feature histograms. In 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3384–3391. IEEE, 2008. 2
[21] M. Savva, F. Y u, H. Su, M. Aono, B. Chen, D. Cohen-Or, W. Deng, H. Su, S. Bai, X. Bai, et al. Shrec16 track large-scale 3d shape retrieval from shapenet core55. 2
[22] P . Y . Simard, D. Steinkraus, and J. C. Platt. Best practices for convolutional neural networks applied to visual document analysis. In ICDAR, volume 3, pages 958–962, 2003. 13
[23] H. Su, S. Maji, E. Kalogerakis, and E. G. Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. In Proc. ICCV , to appear, 2015. 2, 5, 6, 8
[24] J. Sun, M. Ovsjanikov, and L. Guibas. A concise and provably informative multi-scale signature based on heat diffusion. In Computer graphics forum, volume 28, pages 1383–1392. Wiley Online Library, 2009. 2
[25] O. Vinyals, S. Bengio, and M. Kudlur. Order mat-ters: Sequence to sequence for sets. arXiv preprint arXiv:1511.06391, 2015. 2, 4, 7
[26] D. Z. Wang and I. Posner. V oting for voting in online point cloud object detection. Proceedings of the Robotics: Science and Systems, Rome, Italy, 1317, 2015. 2
[27] Z. Wu, R. Shou, Y . Wang, and X. Liu. Interactive shape co-segmentation via label propagation. Computers & Graphics,38:248–254, 2014. 6, 10
[28] Z. Wu, S. Song, A. Khosla, F. Y u, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1912–1920, 2015. 2,5, 11
[29] L. Yi, V . G. Kim, D. Ceylan, I.-C. Shen, M. Yan, H. Su,C. Lu, Q. Huang, A. Sheffer, and L. Guibas. A scalable active framework for region annotation in 3d shape collections.SIGGRAPH Asia, 2016. 6, 10, 18
Supplementary
A、综述
本文件为主要文件提供了额外的定量结果、技术细节和更多定性测试示例。
在第二节中,我们扩展了健壮性测试,在不完全输入的情况下比较了PointNet和VoxNet。在C节中,我们提供了有关神经网络架构、训练参数的更多详细信息,在 D 节中,我们描述了我们在场景中的检测pipeline。然后E节展示了PointNet更多的应用,F节展示了更多的分析实验。在第G节为我们在点网上的理论提供了一个证明。最后,我们展示了更多的可视化结果。
B、PointNet和VoxNet之间的比较(第5.2节)
我们扩展了第5.2节鲁棒性测试中的实验,以比较PointNet和VoxNet 17对输入点云中缺失数据的鲁棒性。两个网络都在相同的训练测试分割上进行训练,以1024个数据点作为输入。对于VoxNet,我们将点云体素化为32×32×32占用网格,并通过围绕上轴的随机旋转和抖动来增加训练数据。
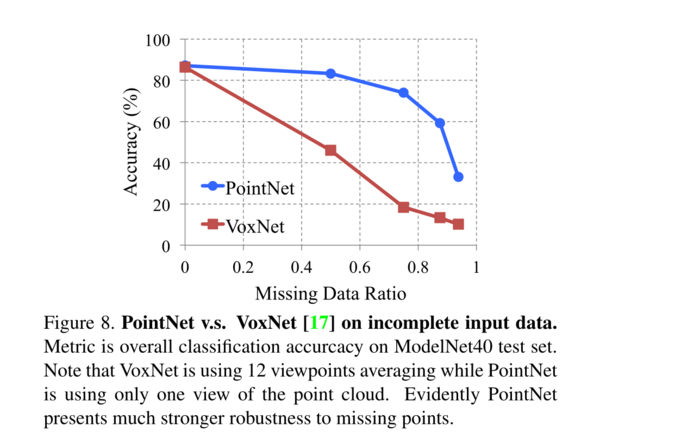
在测试时,输入点按照一定的比例被随机删除。由于VoxNet对旋转很敏感,它的预测使用了点云的12个视点的平均分数。如图8所示,我们看到我们的PointNet对于缺失点更加健壮。当一半的输入点丢失时,VoxNet的准确性急剧下降,从86.3%下降到46.0%,差异为40.3%,而我们的PointNet仅具有3.7%的性能下降。这可以通过我们的PointNet的理论分析和解释来解释——它正在学习使用临界点的集合来总结形状,因此它对于缺失的数据非常健壮。
图8、PointNet与VoxNet[17]处理不完整的输入数据。 Metric是ModelNet40测试集上的整体分类准确率。请注意,VoxNet使用12个视点进行平均,而PointNet仅使用点云的一个视图。显然,PointNet对缺失点具有更强的鲁棒性。
C、网络架构和训练细节(第5.1节)
PointNet分类网络 由于基本架构已经在主要论文中说明,这里我们提供了更多关于关节对齐/转换网络和训练参数的细节。
第一个转换网络是一个mini-PointNet,它将原始点云作为输入并回归到一个3×3矩阵。它由每个点上的共享MLP(64、128、1024)网络(层输出大小为64、128、1024)、通过点的最大池化和两个输出大小为512、256的全连接层成。输出矩阵被初始化为单位矩阵。除最后一层外,所有层都包括ReLU和批量归一化。第二个变换网络的架构与第一个相同,只是输出是64×64矩阵。矩阵也被初始化为一个单位矩阵。一个正则化损失(权重为 0.001)被添加到softmax 分类损失中,以使矩阵接近正交矩阵。在类分数预测之前,我们在最后一个全连接层(其输出维度为256)上使用保持比为0.7的dropout。批量归一化的衰减率从0.5开始,逐渐增加到0.99。我们使用初始学习率0.001、momentum为0.9 和批量大小32的adam优化器。学习率每20个epoch除以2。在ModelNet上进行训练需要3-6小时才能与TensorFlow 和GTX1080 GPU融合。
PointNet分割网络 分割网络是分类PointNet的扩展。局部点特征(第二个转换网络之后的输出)和全局特征(最大池化的输出)为每个点连接起来。分割网络不使用dropout。训练参数与分类网络相同。
对于形状部分分割的任务,我们对基本的分割网络架构(主论文中的图2)进行了一些修改,以实现最佳性能,如图9所示。我们添加一个指示输入类别的one-hot向量,并将其与最大池化层的输出连接。我们还在某些层中增加了神经元,并添加了跳跃链接以收集不同层中的局部点特征并将它们连接起来形成点特征输入到分割网络。
虽然[27]和[29]独立处理每个目标类别,但由于缺少某些类别的训练数据(数据集中所有类别的形状总数显示在第一行),我们训练我们的跨类别的PointNet(但使用one-hot 向量输入来指示类别)。为了进行公平比较,在测试这两个模型时,我们只预测给定特定目标类别的部分标签。
至于语义分割任务,我们使用了主要论文中图2中的架构。在ShapeNet part数据集上训练模型大约需要6到12个小时,在斯坦福语义解析数据集上训练大约需要半天时间。
图9、部分分割的网络架构。 T1和T2是输入点和特征的对齐/转换网络。FC是在每个点上运行的全连接层。MLP是每个点上的多层感知器。 One-hot是一个大小为16的向量,表示输入形状的类别。
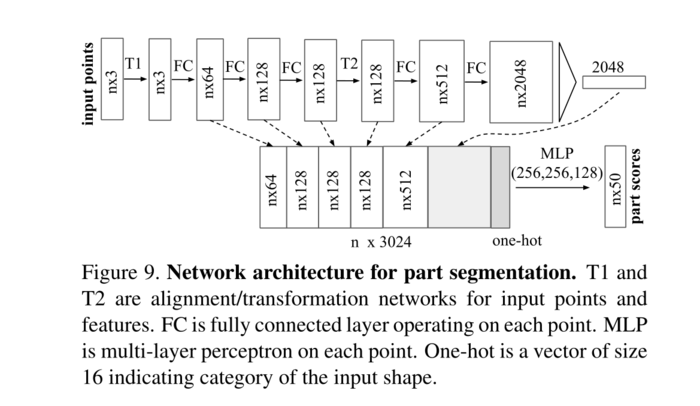
图10、baseline 3D CNN分割网络。该网络是完全卷积的,并预测每个体素的部分分数。
Baseline 3D CNN分割网络 在ShapeNet部分分割实验中,我们将我们提出的分割版本PointNet与两种传统方法以及3D volumetric CNN网络baseline进行了比较。在图10中,我们展示了我们使用的baseline 3D volumetric CNN网络。我们将著名的3D CNN架构,如VoxNet[17]和3DShapeNets[28]推广到完全卷积的3D CNN分割网络。
对于给定的点云,我们首先将其转换为体积表示,作为分辨率为32×32×32的占用网格。然后,依次应用五个3D卷积操作,每个操作具有32个输出通道和步长为1,以提取特征。每个体素的感受野为19。最后,将内核大小为1×1×1的3D卷积层序列附加到计算的特征图中,以预测每个体素的分割标签。除最后一层外,所有层都使用ReLU和批量归一化。网络是跨类别训练的,然而,为了与给定目标类别的其他baseline方法进行比较,我们只考虑给定目标类别中的输出分数。
D、检测pineline的详细信息(第5.1节)
我们基于语义分割结果和我们的目标分类PointNet构建了一个简单的3D目标检测系统。
我们使用具有分割分数的连接组件来获得场景中的目标proposals。我们从场景中的一个随机点开始,找到它的预测标签,并使用BFS搜索附近具有相同标签的点,搜索半径为0.2米。如果生成的集群有超过200个点(假设在1m x 1m的区域中有4096个点样本),则集群的边界框被标记为一个目标proposal。对于每个proposal的目标,它的检测分数被计算为该类别的平均分数。在评估之前,对面积/体积极小的proposals进行修剪。对于桌子、椅子和沙发,边界框延伸到地板,以防腿与座椅/表面分开。
我们观察到,在礼堂等一些房间中,许多目标(例如椅子)彼此靠近,其中连接的组件无法正确分割出单个目标。因此,我们利用我们的分类网络并使用滑动形状方法来缓解椅子类的问题。我们为每个类别训练一个二元分类网络,并使用分类器进行滑动窗口检测。结果框通过非最大抑制进行修剪。将来自连接组件和滑动形状的建议框组合起来进行最终评估。
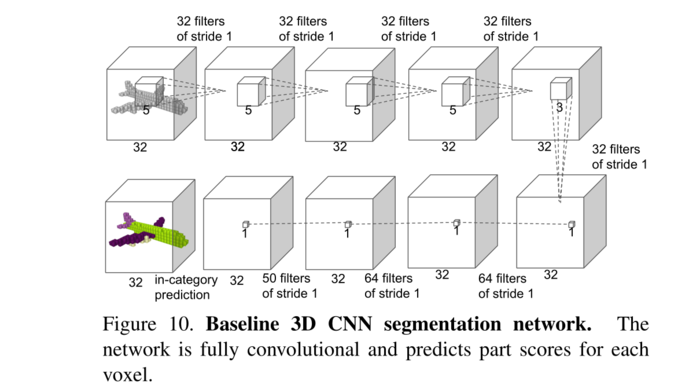
在图11中,我们展示了目标检测的精确召回曲线。我们训练了六个模型,每个模型都在五个区域进行训练并在左侧区域进行测试。在测试阶段,每个模型都在它从未见过的区域进行测试。汇总所有六个区域的测试结果以生成PR曲线。
图11、3D点云中目标检测的精确召回曲线。我们对四个类别的所有六个区域进行了评估:桌子、椅子、沙发和木板。 IoU阈值为0.5的体积。
E、更多应用(第 5.1 节)
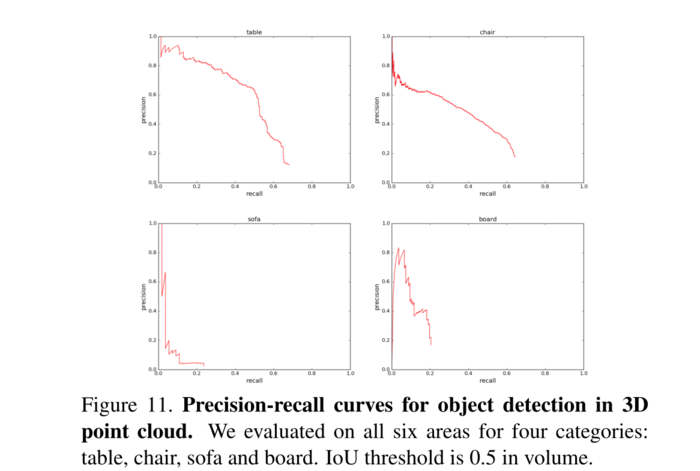
从点云中检索模型 我们的PointNet为每个给定的输入点云学习全局形状签名。我们期望几何相似的形状具有相似的全局特征。在本节中,我们在形状检索应用程序上测试我们的猜想。更具体地说,对于来自ModelNet测试分割的每个给定的查询形状,我们计算其由我们的分类PointNet给出的全局签名(得分预测层之前的层的输出),并通过最近邻搜索在训练分割中检索相似的形状。结果如图12所示。
图12、从点云中检索模型。对于每个给定的点云,我们从ModelNet测试拆分中检索前5个相似形状。从上到下,我们展示了椅子、植物、床头柜和浴缸查询的示例。检索到的属于错误类别的结果用红色框标记。
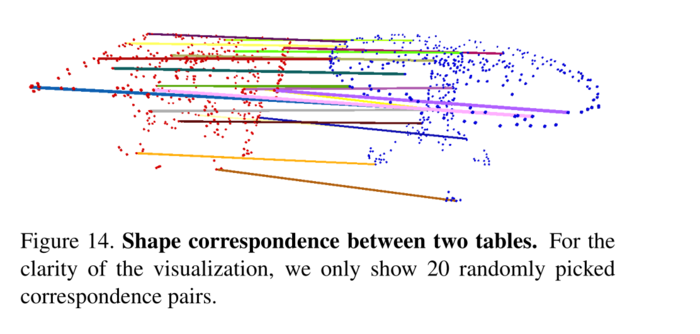
形状对应 在本节中,我们展示了PointNet学习的点特征可以潜在地用于计算形状对应。给定两个形状,我们通过匹配激活全局特征中相同维度的点对来计算它们的临界点集\(C_{S}\)之间的对应关系。图13和图14显示了检测到的两个相似椅子和桌子之间的形状对应关系。
图13、两把椅子之间的形状对应。为了可视化的清晰,我们只展示了20个随机挑选的对应对。
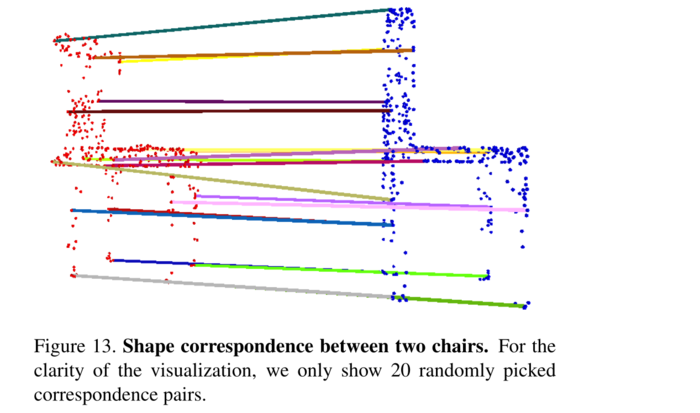
图14、两个表格之间的形状对应关系。为了可视化的清晰,我们只展示了20个随机挑选的对应对。
F、更多架构分析(第 5.2节)
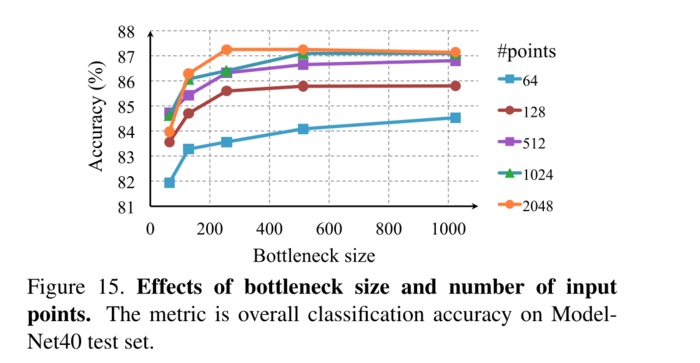
瓶颈维度和输入点数的影响 在这里,我们展示了我们的模型在第一个最大层输出的大小以及输入点的数量方面的性能变化。在图15中,我们看到性能随着点数的增加而增长,但是它在大约1K点处饱和。最大层大小起着重要作用,将层大小从64增加到1024会导致2−4%的性能提升。这表明我们需要足够的点特征函数来覆盖三维空间,以便区分不同的形状。
值得注意的是,即使输入64个点(从网格上的最远点采样获得),我们的网络也可以获得不错的性能。
图15、瓶颈大小和输入点数量的影响。该指标是 ModelNet40 测试集上的整体分类准确率。
MNIST数字分类 虽然我们专注于3D点云学习,但完整性检查实验是将我们的网络应用于2D点云-像素集。为了将 MNIST图像转换为2D点集,我们对像素值进行阈值化,并将值大于128的像素(表示为图像中具有(x, y)坐标的点)添加到该集。我们使用256的集合大小。如果集合中的像素超过256个,我们随机对其进行子采样;如果更少,我们用集合中的一个像素填充集合(由于我们的最大操作,用于填充的点不会影响结果)。
如表7所示,我们与一些基线进行比较,包括将输入图像视为有序向量的多层感知器、将输入视为从像素(0,0)到像素 (27,27)的序列的RNN,以及vanilla版CNN。虽然MNIST上性能最好的模型仍然是精心设计的CNN(误差率低于0.3%),但有趣的是,我们的PointNet模型可以通过将图像视为2D点集来实现合理的性能。
表7、MNIST分类结果。我们与其他深度架构的普通版本进行比较,以表明我们基于点集输入的网络

正态估计 在PointNet的分割版本中,局部点特征和全局特征被连接起来,以便为局部点提供上下文。但是,尚不清楚上下文是否是通过这种连接来学习的。在这个实验中,我们通过展示我们的分割网络可以被训练来预测点法线来验证我们的设计,点法线是由点的邻域决定的局部几何属性。
我们以监督的方式训练我们的分割PointNet的修改版本,以回归到groundtruth点法线。我们只需更改分割点网络的最后一层来预测每个点的法线向量。我们使用余弦距离的绝对值作为损失。
图16将我们的PointNet法线预测结果(左列)与从网格计算的真实法线(右列)进行比较。我们观察到合理的正常重建。我们的预测比在某些区域包括翻转法线方向的ground-truth更平滑和连续。
图16、PointNet法线重建结果。在该图中,我们显示了一些样本点云中所有点的重建法线以及在网格上计算的ground-truth法线。

分割鲁棒性 正如5.2节和B节所讨论的,我们的PointNet对分类任务的数据损坏和缺失点不太敏感,因为全局形状特征是从给定输入点云的关键点集合中提取的。在本节中,我们展示了鲁棒性也适用于分割任务。基于每点特征和学习的全局形状特征的组合来预测每点部分标签。在图17中,我们说明了给定输入点云\(S\)(最左列)、临界点集\(C_{S}\)(中间列)和上限形状\(N_{S}\)的分割结果。
图17、分割结果的一致性。我们举例说明了一些样本点云\(S\),它们的临界点集\(C_{S}\)和上限形状\(N_{S}\)的分割结果。我们观察到\(C_{S}\)和\(N_{S}\)之间的形状族共享一致的分割结果。

网络对看不见的形状类别的泛化性 在图18中,我们可视化了临界点集合和上界形状,这些形状来自未在ModelNet或ShapeNet中出现的看不见的类别(脸、房子、兔子、茶壶)。这表明所学习的每点(per-point)函数是可推广的。然而,由于我们主要在具有大量平面结构的人造物体上进行训练,因此在新类别中重建的上限形状也包含更多的平面表面。
图18、可见物体的临界点集合和上限形状。我们将不在ModelNet或ShapeNet形状存储库中的茶壶、兔子、手和人体的临界点集和上限形状可视化,以测试我们的PointNet的学习的每点(per-point)函数在其他看不见的目标上的普遍性.图像采用颜色编码以反映深度信息。

G、定理的证明(第4.3节)
定理1 假设\(f: \mathcal{X} \rightarrow \mathbb{R}\)是关于Hausdorff距离\(d_{H}(\cdot, \cdot)\)的连续集函数。\(\forall \epsilon > 0\) , ∃一个连续函数\(h\)和一个对称函数\(g\left(x_{1}, \ldots, x_{n}\right)=\gamma \circ MAX\),其中\(γ\)是一个连续函数,max是一个向量MAX操作符,它将n个向量作为输入,并返回一个元素最大值的新向量,使得对于任何\(S \in \mathcal{X}\),
\]
其中\(x_{1}, \ldots, x_{n}\)是按一定顺序提取的\(S\)的元素。
证明:通过\(f\)的连续性,我们取\(\delta_{\epsilon}\)使得\(\left|f(S)-f\left(S^{\prime}\right)\right|<\epsilon\)对于任意\(S, S^{\prime} \in \mathcal{X}\),如果\(d_{H}\left(S, S^{\prime}\right)<\delta_{\epsilon}\)。
定义\(K=\left\lceil 1 / \delta_{\epsilon}\right\rceil\),它将\([0,1]\)平均分成\(K\)个区间,并定义一个辅助函数,将一个点映射到它所在区间的左端:
\]
令\(\tilde{S}=\{\sigma(x): x \in S\}\),则
\]
因为\(d_{H}(S, \tilde{S})<1 / K \leq \delta_{\epsilon}\)。
设\(h_{k}(x)=e^{-d\left(x,\left[\frac{k-1}{K}, \frac{k}{K}\right]\right)}\)是一个软指示函数,其中\(d(x, I)\)是要设置(间隔)距离的点。设\(\mathbf{h}(x)=\left[h_{1}(x) ; \ldots ;h_{K}(x)\right]\),则\(\mathbf{h}: \mathbb{R} \rightarrow \mathbb{R}^{K}\)。
令\(v_{j}\left(x_{1}, \ldots, x_{n}\right)=\max \left\{\tilde{h}_{j}\left(x_{1}\right), \ldots, \tilde{h}_{j}\left(x_{n}\right)\right\}\),表示\(S\)中的点对第\(j\)个区间的占用。设\(\mathbf{v}=\left[v_{1} ; \ldots ; v_{K}\right]\),则\(\mathbf{v}: \underbrace{\mathbb{R} \times \ldots \times \mathbb{R}}_{n} \rightarrow\{0,1\}^{K}\)是一个对称函数,用\(S\)中的点表示每个区间的占用情况。
将\(\tau:\{0,1\}^{K} \rightarrow \mathcal{X}\)定义为\(\tau(v)=\left\{\frac{k-1}{K}: v_{k} \geq 1\right\}\),它将占用向量映射到包含每个占用区间左端的集合。很容易展示:
\]
其中\(x_{1}, \ldots, x_{n}\)是按一定顺序提取的\(S\)的元素。
令\(\gamma: \mathbb{R}^{K} \rightarrow \mathbb{R}\)是一个连续函数,使得\(\gamma(\mathbf{v})=f(\tau(\mathbf{v}))\)对于\(v \in\{0,1\}^{K}\)。则,
&\left|\gamma\left(\mathbf{v}\left(x_{1}, \ldots, x_{n}\right)\right)-f(S)\right| \\
=&\left|f\left(\tau\left(\mathbf{v}\left(x_{1}, \ldots, x_{n}\right)\right)\right)-f(S)\right|<\epsilon
\end{aligned}
\]
注意\(\gamma\left(\mathbf{v}\left(x_{1}, \ldots, x_{n}\right)\right)\)可以改写如下:
\gamma\left(\mathbf{v}\left(x_{1}, \ldots, x_{n}\right)\right) &=\gamma\left(\operatorname{MAX}\left(\mathbf{h}\left(x_{1}\right), \ldots, \mathbf{h}\left(x_{n}\right)\right)\right) \\
&=(\gamma \circ \mathbf{M A X})\left(\mathbf{h}\left(x_{1}\right), \ldots, \mathbf{h}\left(x_{n}\right)\right)
\end{aligned}
\]
显然\(\gamma \circ\) MAX是一个对称函数。
接下来我们给出定理2的证明。我们将\(\mathbf{u}=\underset{x_{i} \in S}{\operatorname{MAX}}\left\{h\left(x_{i}\right)\right\}\)定义为\(f\)的子网络,它将\([0,1]^{m}\)中的点集映射到 \(K\)维向量。
定理2 假设\(\mathbf{u}: \mathcal{X} \rightarrow \mathbb{R}^{K}\)使得\(u = \underset{x_{i} \in S}{\operatorname{MAX}}\left\{h\left(x_{i}\right)\right\}\)并且\(f=\gamma \circ \mathbf{u}\)。则,
(a) \(\forall S, \exists \mathcal{C}_{S}, \mathcal{N}_{S} \subseteq \mathcal{X}, f(T)=f(S)\) if \(\mathcal{C}_{S} \subseteq T \subseteq \mathcal{N}_{S}\);
(b) \(\left|\mathcal{C}_{S}\right| \leq K\)
证明:显然,\(\forall S \in \mathcal{X}\),\(f(S)\)由\(\mathbf{u}(S)\)决定。所以我们只需要证明 \(\forall S, \exists \mathcal{C}_{S}, \mathcal{N}_{S} \subseteq \mathcal{X},f(T) = f(S)\), 如果\(\mathcal{C}_{S} \subseteq T \subseteq \mathcal{N}_{S}\)。
对于作为\(\mathbf{u}\)的输出的第j个维度,至少存在一个\(x_{j} \in \mathcal{X}\)使得\(h_{j}\left(x_{j}\right)=\mathbf{u}_{j}\),其中\(h_{j}\)是来自\(h\)的输出向量的第j个维度。以\(C_{S}\)作为 \(j=1, \ldots, K\)的所有\(x_{j}\)的并集。则\(C_{S}\)满足上述条件。
增加任何额外的点\(x\)使得在\(C_{S}\)的所有维度上\(h(x) ≤ u(S)\)不会改变\(\mathbf{u}\),hence \(f\)。因此,\(T_{S}\)可以通过将所有这些点的并集与\(N_{S}\)相加来获得。
H、更多可视化
分类可视化 我们使用t-SNE[15]将来自我们分类点网的点云全局签名(1024维)嵌入到2D空间中。图20示出了ModelNet 40测试分割形状的嵌入空间。相似的形状根据它们的语义类别聚集在一起。
分割可视化 我们在完整的CAD模型和模拟的Kinect部分扫描上呈现了更多的分割结果。我们还通过错误分析可视化失败案例。图21和图22显示了在完整CAD模型及其模拟Kinect扫描上生成的更多分割结果。图23显示了一些故障情况。请阅读错误分析的标题。
场景语义解析可视化 我们在图24中给出了语义解析的可视化,其中我们示出了两个办公室和一个会议室的语义分割和目标检测的输入点云、预测和基础事实。在训练集中看不到区域和房间。
点功能可视化 我们的分类点网络计算每个点的K(在该可视化中我们取K = 1024)维点特征,并通过最大池层化将所有每点局部特征聚集到单个K维向量中,这形成了全局形状描述符。
为了获得关于所学习的每点函数\(h\)检测到什么的更多见解,我们在图19中可视化给出高每点函数值\(f(p_{i})\)的点\(p_{i}\)。这种可视化清楚地显示了不同的点函数学习检测具有分散在整个空间中的各种形状的不同区域中的点。
图19、点函数可视化。对于每个点函数\(h\),我们计算位于原点的直径为2的立方体中所有点\(p\)的值\(h(p)\),它在空间上覆盖了在训练PointNet时我们的输入形状被归一化的单位球体。在此图中,我们将所有使\(h(p) > 0.5\)的点\(p\)可视化,函数值由体素的亮度进行颜色编码。我们随机选择15个点函数并可视化它们的激活区域。

图20、 学习形状全局特征的2D嵌入。我们使用t-SNE技术来可视化ModelNet40测试拆分中形状的学习全局形状特征。

图21、完整CAD模型上的PointNet分割结果。
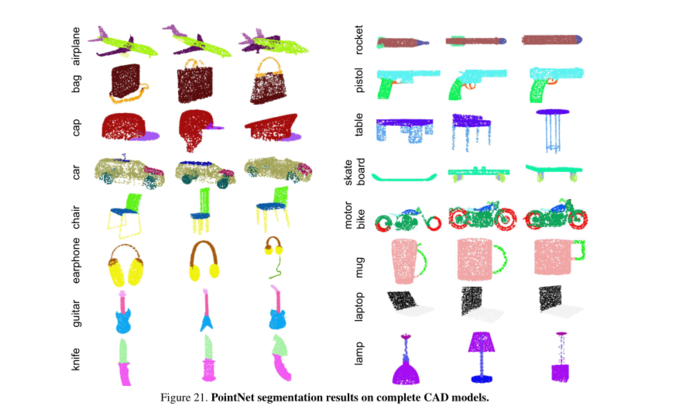
图22、模拟Kinect扫描的PointNet分割结果。

图23、PointNet分割失败案例。在此图中,我们总结了分割应用程序中的六种常见错误。第一列和第二列给出了预测和真值分割,而第三列计算并显示了差异图。红点对应于给定点云中错误标记的点。(a)说明了最常见的失败案例;边界上的点被错误地标记。在示例中,桌/椅腿和顶部之间的交叉点附近的点的标签预测不准确。然而,大多数分割算法都存在这个错误。(b)显示了奇异形状的错误。例如,图中所示的吊灯和飞机在数据集中非常罕见。(c)表明小部分可以被附近的大部分覆盖。例如,飞机的喷气发动机(图中黄色)被错误地归类为机身(绿色)或机翼(紫色)。(d)显示了由part形状固有的模糊性引起的误差。例如,图中两个桌子的两个底部被分类为桌腿和桌底([29]中的其他类别),而ground-truth分割则相反。(e)说明了由部分扫描的不完整性引入的错误。对于图中的两个帽子,几乎一半的点云都丢失了。(f)显示了当某些目标类别的训练数据太少而无法涵盖足够多的种类时的失败案例。对于此处显示的两个类别,整个数据集中只有54个袋子和39个帽子。
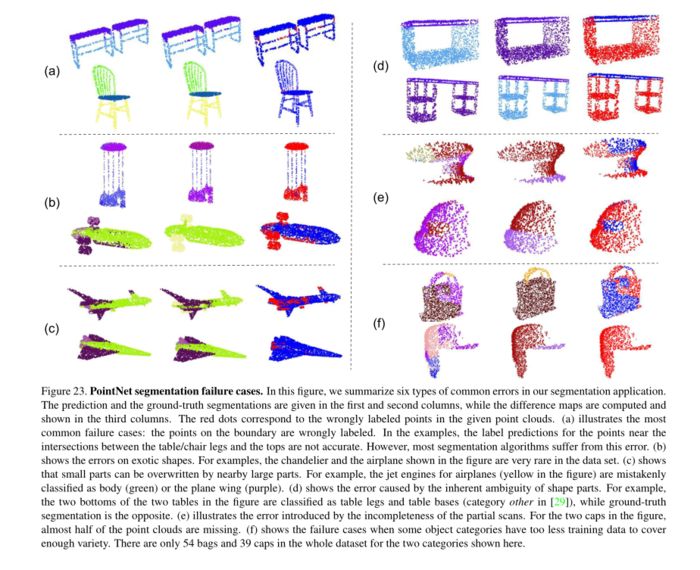
图24. 语义分割和目标检测示例。第一行是输入点云,为了清晰起见,隐藏了墙壁和天花板。第二行和第三行是对点的语义分割的预测和ground-truth,其中属于不同语义区域的点颜色不同(红色椅子,紫色桌子,橙色沙发,灰色木板,绿色书柜,蓝色地板,紫罗兰色的窗户,黄色的横梁,洋红色的柱子,卡其色的门和黑色的杂物)。最后两行是带有边界框的目标检测,其中预测框来自基于语义分割预测的连接组件。


本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 