1.背景
Easy-Classification是一个应用于分类任务的深度学习框架,它集成了众多成熟的分类神经网络模型,可帮助使用者简单快速的构建分类训练任务。
本例基于Easy-Classification框架,快速搭建一个验证码识别训练任务。项目整体目录如下:

- 任务输入:4位大小写字母和数字混合组成的验证码图片, 图片大小为100*40。
- 任务输出:识别图像中的字母和数字,并输出验证码编码。
2.验证码识别
2.1 生成训练数据
在项目根目录下新建data目录用于放置训练集,测试集,验证集数据。验证码训练数据基于脚本模拟生成。执行scripts/make_captcha.py文件,或make_captcha_1.py,make_captcha_3.py可批量生成验证码图像信息。(实际选择哪一种,看实际需要验证码识别图像的样式,若本身存在训练数据,可基于实际的训练数据训练)。
基于make_captcha.py文件,最终生成训练数据10000份,验证数据5000份,最终模拟应用数据10000份。训练验证码图片如:

说明:
- 基于脚本模拟验证码图片,生成的验证码字符做大小写区分。
- 每个验证码图片,对应的验证码字符串为图片名称,如00FS_69570.png,00FS是验证码字符串,后面的是随机数避免文件重名。
2.2 编写训练脚本
训练过程需编写配置文件,自定义DateSet数据加载类,训练过程脚本类。一个图像中存在多个识别对象,考虑到最终是4个字符,本例基于one-hot模式,将验证码的label转换为one-hot编码。详情请参考对应目录下实现源码。
自定义DateSe部分核心代码说明:
""" @Description : 构建Dataset类,不同的任务,dataset自行编写,如基于csv,文本等加载标签,均可从cfg配置文件中读取后,自行扩展编写 编写自定义Dataset类时,初始化参数需定义为source_img, cfg。否则数据加载通用模块,data_load_service.py模块会报错。 source_img :传入的图像地址信息 cfg:传入的配置类信息,针对不同的任务,可能生成的label模式不同,可基于配置类指定label的加载模式,最终为训练的图像初始化label (用户自定义实现) 本例为验证码加载类:基于文件名称生成标签(如验证码:0AaW_54463.png,标签值为:0AaW,返回one-hot编码) """import torch from torch.utils.data.dataset import Dataset import torchvision.transforms as transforms import cv2 from universe.data_load.normalize_adapter import NormalizeAdapter from PIL import Image from universe.utils.utils import one_hot classTrainDataset(Dataset): """ 构建一个 加载原始图片的dataSet对象 此函数可加载 训练集数据,基于路径识别验证码真实的label,label在转换为one-hot编码 若 验证集逻辑与训练集逻辑一样,验证集可使用TrainDataset,不同,则需自定义一个,参考如下EvalDataset """def__init__(self, source_img, cfg): self.source_img = source_img self.cfg = cfg self.transform = createTransform(cfg, TrainImgDeal) def__getitem__(self, index): img = cv2.imread(self.source_img[index]) if self.transform isnotNone: img = self.transform(img) # ../ data / train\Qigj_73075.png label = self.source_img[index].split("_")[0][-4:] target = torch.Tensor(one_hot(label)) return img, target, self.source_img[index] def__len__(self): returnlen(self.source_img) classEvalDataset(Dataset): """ 构建一个 加载原始图片的dataSet对象 此函数可加载 验证集数据,基于路径识别验证码真实的label,label在转换为one-hot编码 """def__init__(self, source_img, cfg): self.source_img = source_img self.cfg = cfg # 若验证集图片处理逻辑(增强,调整)与 训练集不同,可自定义一个EvalImgDeal self.transform = createTransform(cfg, TrainImgDeal) def__getitem__(self, index): img = cv2.imread(self.source_img[index]) if self.transform isnotNone: img = self.transform(img) # ../ data / train\Qigj_73075.png label = self.source_img[index].split("_")[0][-4:] target = torch.Tensor(one_hot(label)) return img, target, self.source_img[index] def__len__(self): returnlen(self.source_img) classPredictDataset(Dataset): """ 构建一个 加载预测图片的dataSet对象 此函数可加载 测试集数据,应用集数据(返回图像信息) """def__init__(self, source_img,cfg): self.source_img = source_img # 若预测集图片处理逻辑(增强,调整)与 训练集不同,可自定义一个PredictImgDeal self.transform = createTransform(cfg, TrainImgDeal) def__getitem__(self, index): img = cv2.imread(self.source_img[index]) if self.transform isnotNone: img = self.transform(img) # 用于记录实际的label值(因为应用数据也是脚本生成的,所以可以知道正确的验证码) real_label = self.source_img[index].split("_")[0][-4:] return img, real_label, self.source_img[index] def__len__(self): returnlen(self.source_img) classTrainImgDeal: def__init__(self, cfg): img_size = cfg['target_img_size'] self.h = img_size[0] self.w = img_size[1] def__call__(self, img): img = cv2.resize(img, (self.h, self.w)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = Image.fromarray(img) return img defcreateTransform(cfg, img_deal): my_normalize = NormalizeAdapter.getNormalize(cfg['model_name']) transform = transforms.Compose([ img_deal(cfg), transforms.ToTensor(), my_normalize, ]) return transform
2.3 训练结果展示
训练结果会输出到out目录,输出信息包括acc,loss的过程图,最优训练权重文件。
本例采用的网络模型为moblienetv3。
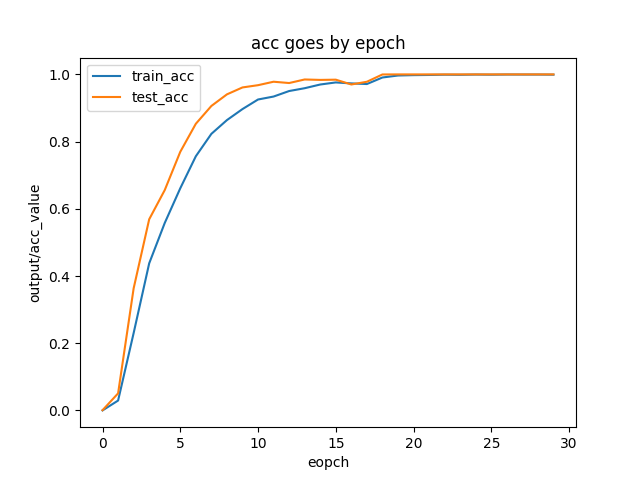
2.3.1 图像训练
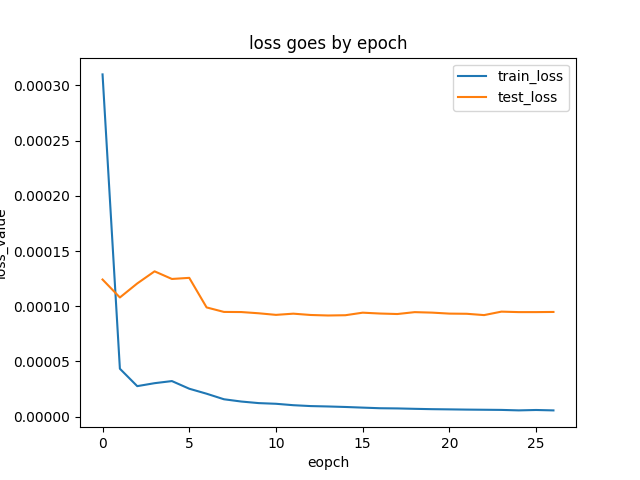
本例基于make_captcha.py验证码生成脚本,批量生成训练数据10000条,验证数据10000条,预测数据6000条。训练结果如下:

2.3.2 混合图像训练
由于训练图像与验证图像是基于不同的验证码脚本生成的图像,将这些图像混合在一起训练。由于训练数据不算多,目前训练结果准确率不高。
三种不同的验证码脚本生成的验证码图片,在图像清晰度,间隔,图像复杂情况不一样。训练数据10000条,验证数据5000条,预测数据10000条,预加载权重文件,训练结果如下:

输出训练日志参考信息:
1/100 [9600/10000 (96%)] - ETA: 0:00:19, loss: 0.0003, acc: 0.9234 LR: 0.001000 [VAL] loss: 0.00012, acc: 81.060% 2/100 [9600/10000 (96%)] - ETA: 0:00:23, loss: 0.0000, acc: 0.9977 LR: 0.001000 [VAL] loss: 0.00011, acc: 82.000% 3/100 [9600/10000 (96%)] - ETA: 0:00:20, loss: 0.0000, acc: 0.9978 LR: 0.001000 [VAL] loss: 0.00012, acc: 79.520% 4/100 [9600/10000 (96%)] - ETA: 0:00:18, loss: 0.0000, acc: 0.9888 LR: 0.001000 [VAL] loss: 0.00013, acc: 78.020% 5/100 [9600/10000 (96%)] - ETA: 0:00:18, loss: 0.0000, acc: 0.9824 LR: 0.001000 [VAL] loss: 0.00012, acc: 80.260% 6/100 [9600/10000 (96%)] - ETA: 0:00:19, loss: 0.0000, acc: 0.9903 LR: 0.001000 [VAL] loss: 0.00013, acc: 80.040% 7/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9923 LR: 0.000100 [VAL] loss: 0.00010, acc: 83.900% 8/100 [9600/10000 (96%)] - ETA: 0:00:20, loss: 0.0000, acc: 0.9977 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.280% 9/100 [9600/10000 (96%)] - ETA: 0:00:18, loss: 0.0000, acc: 0.9987 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.400% 10/100 [9600/10000 (96%)] - ETA: 0:00:20, loss: 0.0000, acc: 0.9992 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.600% 11/100 [9600/10000 (96%)] - ETA: 0:00:19, loss: 0.0000, acc: 0.9993 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.460% 12/100 [9600/10000 (96%)] - ETA: 0:00:19, loss: 0.0000, acc: 0.9995 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.600% 13/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9998 LR: 0.000100 [VAL] loss: 0.00009, acc: 85.100% 14/100 [9600/10000 (96%)] - ETA: 0:00:19, loss: 0.0000, acc: 0.9996 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.720% 15/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9998 LR: 0.000100 [VAL] loss: 0.00009, acc: 85.140% 16/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9998 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.720% 17/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9999 LR: 0.000100 [VAL] loss: 0.00009, acc: 85.220% 18/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9999 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.900% 19/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9999 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.980% 20/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 1.0000 LR: 0.000100 [VAL] loss: 0.00009, acc: 85.280% 21/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9999 LR: 0.000100 [VAL] loss: 0.00009, acc: 85.140% 22/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 1.0000 LR: 0.000100 [VAL] loss: 0.00009, acc: 85.140% 23/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 0.9998 LR: 0.000100 [VAL] loss: 0.00009, acc: 84.880% 24/100 [9600/10000 (96%)] - ETA: 0:00:20, loss: 0.0000, acc: 1.0000 LR: 0.000100 [VAL] loss: 0.00010, acc: 85.120% 25/100 [9600/10000 (96%)] - ETA: 0:00:20, loss: 0.0000, acc: 1.0000 LR: 0.000010 [VAL] loss: 0.00009, acc: 85.160% 26/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 1.0000 LR: 0.000010 [VAL] loss: 0.00009, acc: 85.180% 27/100 [9600/10000 (96%)] - ETA: 0:00:21, loss: 0.0000, acc: 1.0000 LR: 0.000010 [VAL] loss: 0.00009, acc: 85.220% [INFO] Early Stop with patient 7 , best is Epoch - 20 :0.852800 -------------------------------------------------- {'model_name': 'mobilenetv3', 'GPU_ID': '', 'class_number': 248, 'random_seed': 42, 'cfg_verbose': True, 'num_workers': 8, 'train_path': 'data/train', 'val_path': 'data/val', 'test_path': 'data/test', 'label_type': 'DIR', 'label_path': '', 'pretrained': 'output/mobilenetv3_e21_0.84700.pth', 'try_to_train_items': 10000, 'save_best_only': True, 'save_one_only': True, 'save_dir': 'output/', 'metrics': ['acc'], 'loss': 'CE', 'show_heatmap': False, 'show_data': False, 'target_img_size': [224, 224], 'learning_rate': 0.001, 'batch_size': 64, 'epochs': 100, 'optimizer': 'Adam', 'scheduler': 'default-0.1-3', 'warmup_epoch': 0, 'weight_decay': 0, 'k_flod': 5, 'start_fold': 0, 'early_stop_patient': 7, 'use_distill': 0, 'label_smooth': 0, 'class_weight': None, 'clip_gradient': 0, 'freeze_nonlinear_epoch': 0, 'dropout': 0.5, 'mixup': False, 'cutmix': False, 'sample_weights': None, 'model_path': '../../config/weight/mobilenet/mobilenetv3_e22_1.00000.pth', 'TTA': False, 'merge': False, 'test_batch_size': 1} -------------------------------------------------- Process finished with exit code 0
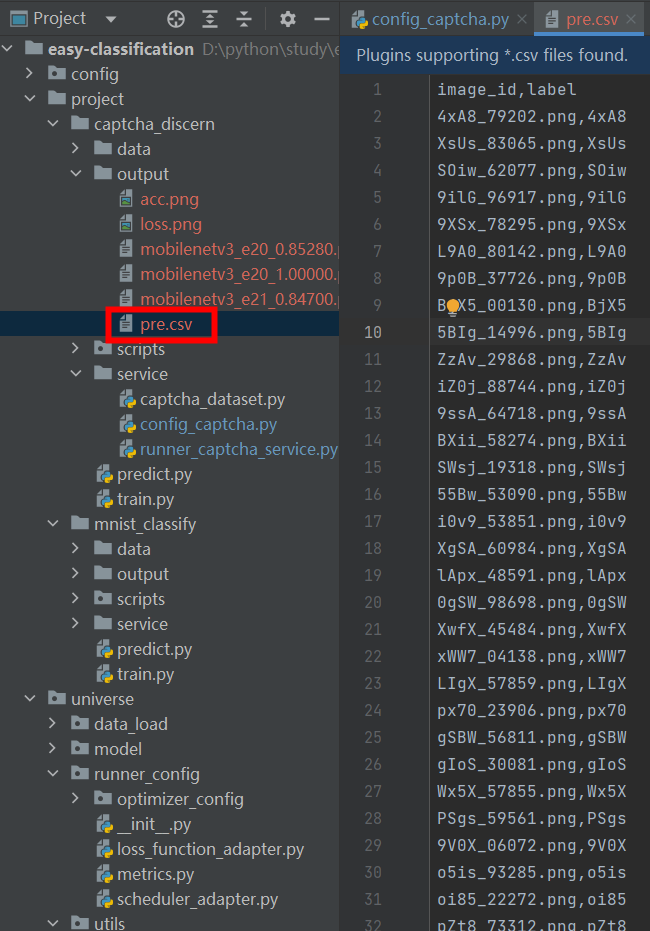
2.4 预测应用
编写预测类脚本,在配置文件中,配置model_path(为训练好的权重文件路径如:),加载预测数据,模型预测后将结果输出到csv文件中。预测代码参考如下:
def predict(cfg): initConfig(cfg) model = ModelService(cfg) data = DataLoadService(cfg) test_loader = data.getPredictDataloader(PredictDataset) runner = RunnerCaptchaService(cfg, model) modelLoad(cfg['model_path']) res_dict = runner.predict(test_loader) print(len(res_dict)) # to csv res_df = pd.DataFrame.from_dict(res_dict, orient='index', columns=['label']) res_df = res_df.reset_index().rename(columns={'index': 'image_id'}) res_df.to_csv(os.path.join(cfg['save_dir'], 'pre.csv'), index=False, header=True) if __name__ == '__main__': predict(cfg)
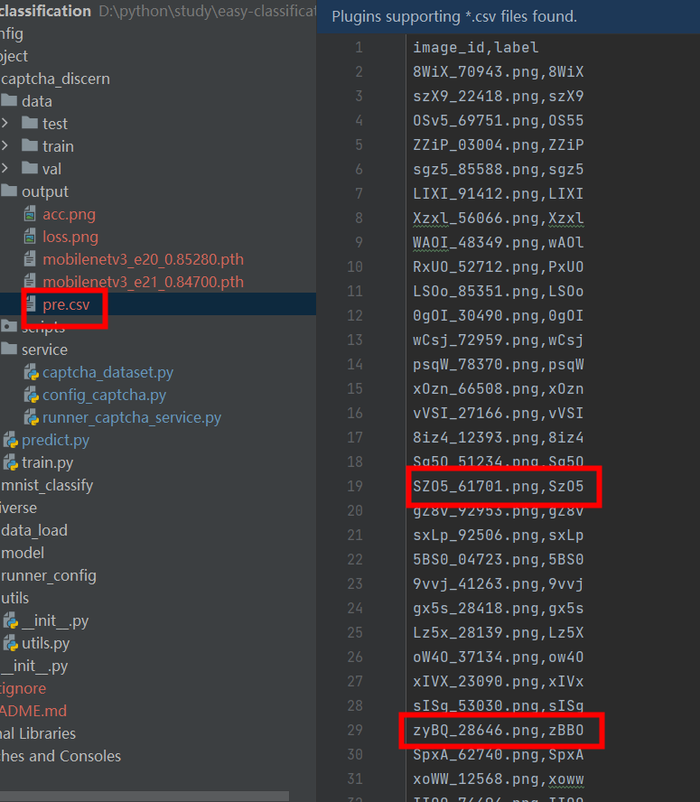
2.4.1 图像训练-预测结果
训练图像,验证图像,预测图像均由make_captcha.py脚本生成,实际预测6000张图像,本次识别准确度100%。
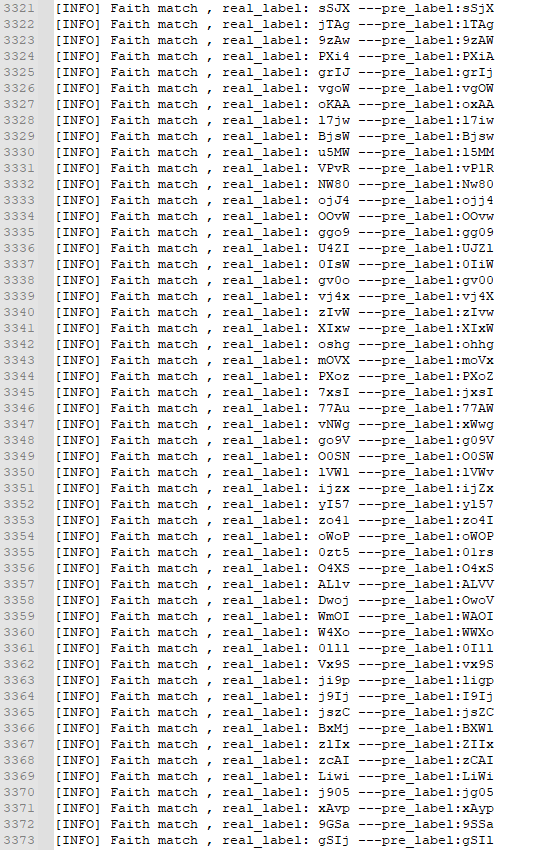
2.4.2 混合图像模式-预测结果
本例的训练图像,验证图像采用了不同的验证码脚本生成,准确率较低,10000张图像,有3373张识别失败。
3.扩展与思考
- 验证码识别中,大小写字母(如x,X),这种容易识别失败。
- 当训练数据偏少时,对于o,O,0,这种看起来相似的字母也容易识别错误。若训练的数据中某一个字母的图像较少,识别该字母的准确度也偏低。所以,本质还是尽可能的丰富训练数据。
- 验证码识别,基于特定场景,基于脚本构建的训练数据,测试数据一定要尽可能的与实际的图像相似(清晰度,字母间的间隔),这样准确度才高。参考上面的两种测试,若训练的验证码图像与最终预测的图像相似,则准确度高。
本例是基于数字,大小写组合的验证码,验证码识别可满足大多数场景,也可以改造支持如下特殊的场景:
- 字符验证码不区分大小写:本算法不变,一样支持。
- 多字符验证码识别:基于具体的位数,如6位验证码,调整分类数值为62*6,改造one-hot,调整为6位,调整acc匹配函数,即可训练支持。
- 纯数字验证码:改造one-hot函数,现有算法的每一位字符串,均存在62种情况(10个数字,52个大小写字母),数字版本只存在10种情况,比现有模式更简单,调整输出分类数值为40,改造one-hot,调整acc匹配函数,即可训练支持。
- 简单数学计算验证码识别:如5-1=?,4+3=?,这种模式的验证码识别,本质还是简单字符识别,
第一位字符存在10种情况(0-9的数字),
第二位存在4种情况(+-*/),
第三位存在10种情况(0-9数字),
调整输出分类数值为24,改造one-hot,调整acc匹配函数,即可训练支持。识别到对应的数字和运算方法后,做简单数学计算即可算出最终的验证码数学计算结果。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Easy-Classification-验证码识别 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 