

导读: 本次分享的内容为图深度学习在自然语言处理领域的方法与应用,主要内容和素材都来自于我们Graph4NLP团队的一篇调研文章:Graph Neural Networks for Natural Language Processing:A Survery,以及我们团队所开发的Graph4NLP的python开源库和教程。主要包括以下几大方面内容:
- DLG4NLP背景与发展
- DLG4NLP方法和模型
- DLG4NLP典型的应用
- DLG4NLP Python开源库
--
01 DLG4NLP背景与发展
我将首先阐述一下为什么需要图结构来处理NLP任务,然后介绍一下传统的图方法在NLP里面的应用,最后引出图神经网络并且简单介绍图深度学习的基础理论。
1. 为什么需要图来处理NLP任务
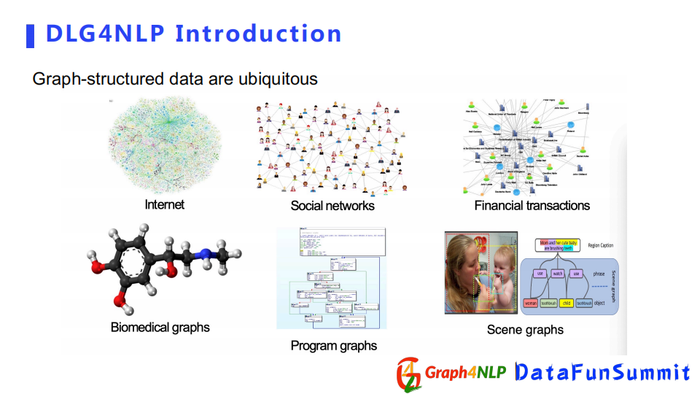
我们知道图结构数据是由节点和边组成的数据类型,在生活的方方面面都可以看到,尤其在大数据时代,比如互联网、社交网络、金融的交易网。还有可以表示成图结构的蛋白质等化学物质。我们也可以用图结构来表示逻辑关系的程序脚本。从图像领域来看,有表示图像里物体间相互交互关系的图结构。
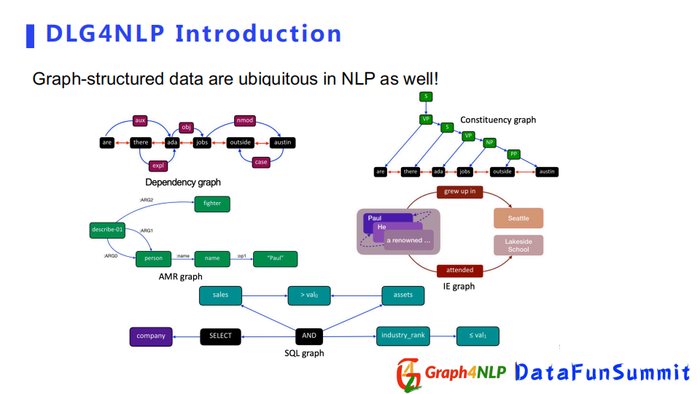
同样在NLP的领域里,我们也会发现很多很多可以表示为图结构的数据。比如针对一个句子,如果我们想表示这个句子里的句法信息的话,可以建立一个dependency graph或者constituency graph;如果我们想捕捉句子的语义信息的话,可以建立一个AMR graph或者IE graph;如果我们把程序语言也看作一种自然语言的话,我们可以构建出捕捉程序逻辑关系的SQL graph。
2. 传统图方法在NLP任务的应用
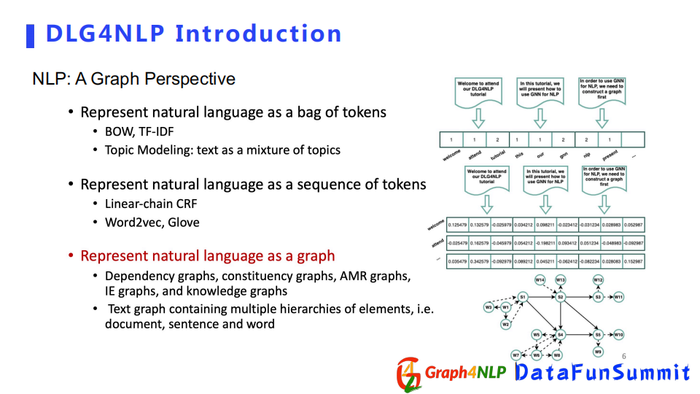
传统NLP领域的表征方法一般分为3种:
第一种采用词袋来表征文本,该方法依靠统计每个词在句子或文档里的频率,但是这种方式无法捕捉词语之间顺序或者无法捕捉词语之间的语义信息。
第二种把文本表示成序列,相对于词袋会捕捉更多的序列信息,并且会包含词对之间的前后关系,典型方法有Word2vec和Glove。
第三种把文本表示成图,比较常见的有dependency graph和constituency graph等。当我们把一个文本表示成图后,就不再局限于前后位置的序列关系,我们可以捕捉到任意两个位置之间的关系,除了位置关系、语法关系,我们还可以捕捉语义关系。所以当我们对句子的文本表示越彻底越全面时,对表征学习任务帮助越大。

现在把自然语言表示成图结构已经不是一件新鲜事情,早在深度学习之前就有算法去这么做。例如采用Random Walk算法和Graph Matching算法计算文本之间的相似性。虽然传统方法表征成了图结构,但是对语言的处理具有比较大的局限性。
其一是没有后续特征的提取环节,其二解决的任务比较有限,比如句子生成,词与句子分类,尤其对于预处理模型同时求多个任务时,需要应用图深度学习来解决图特征提取环节。
3. 图深度学习基础理论
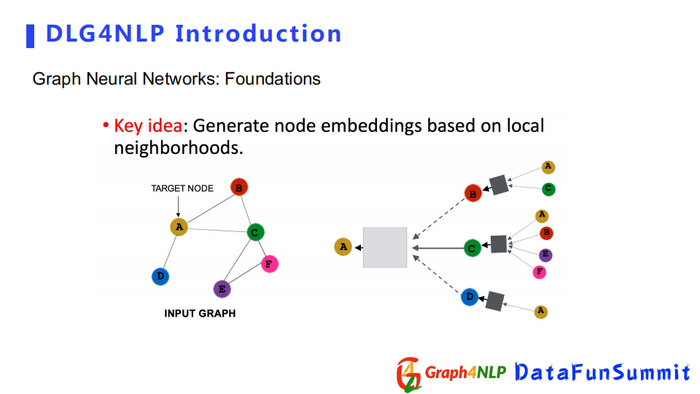
图神经网络的核心思想是依靠邻居节点的表征向量对目标节点的影响,不断地更新和学习每个节点的隐式表征。不同的图神经网络之间的差异在于所定义的邻居节点对目标节点的影响方式和信息传递的方式不同。图神经网络既可以计算节点的表征向量node embedding,也可以计算整个图的表征向量graph-level embedding。通过图卷积方式计算节点的表征向量的不同,图卷积有四个比较典型的代表:Spectral-based,Spatial-based,Attention-based,Recurrent-based。该四个类型并不相互排斥,一种图卷积方法既可以是Spatial-based也可以是Attention-based。
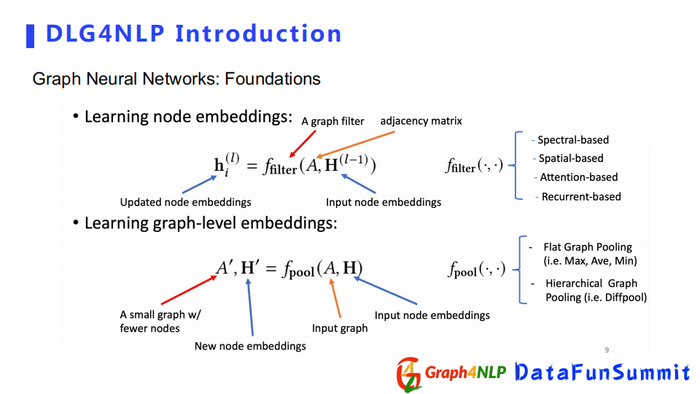
我们介绍下基本的图卷积操作。
第一个公式为图卷积运算,它的输入为A邻接矩阵和H node embedding(节点表征);对于节点分类和邻接预测的任务,得到节点的表征向量即可。对于图分类和图的生成任务,需要采用pooling(池化操作)对整个图做表征向量,常见的方法有Flat Graph Pooling(求平均、最大、最小值pooling方式);另外一种是Hierarchical Graph Pooling(Diff pool方式),根据图结构把整个node embedding聚合到一起组成一个graph embedding network。

根据不同的图卷积方式和pooling(池化)层,我们可以得到不同的图神经网络模型,比如GCN,GAT等。
--
02 DLG4NLP方法和模型
下面我们进入第二部分,即如何用图神经网络去解决自然语言处理的任务。这一环节我会从三个方面进行介绍,首先是如何去构造自然语言任务里的图结构,其次是如何在图结构基础上进行表征学习,最后讲两个比较典型的图神经网络构架。
1. 如何构造NLP的图结构
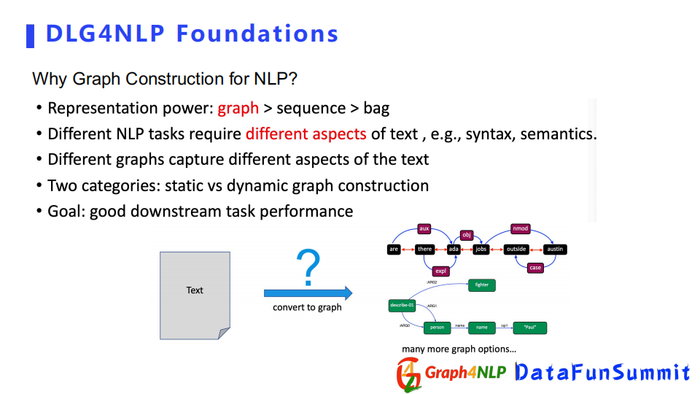
自然语言里对文本的图构造可以分为两类:
- 静态图构造
- 动态图构造
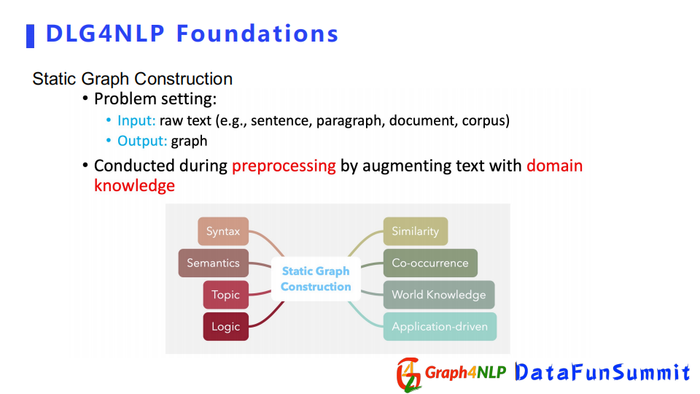
静态图构造的输入可以为原始的句子、段落或者文档,输出是我们针对输入所构造出的图结构。静态图可以在预处理阶段完成,但是它需要有一些对句子或文档文本的领域信息,比如一些语法信息、语义信息、逻辑信息和主题信息,根据领域信息对句子或者文本构造一个图。
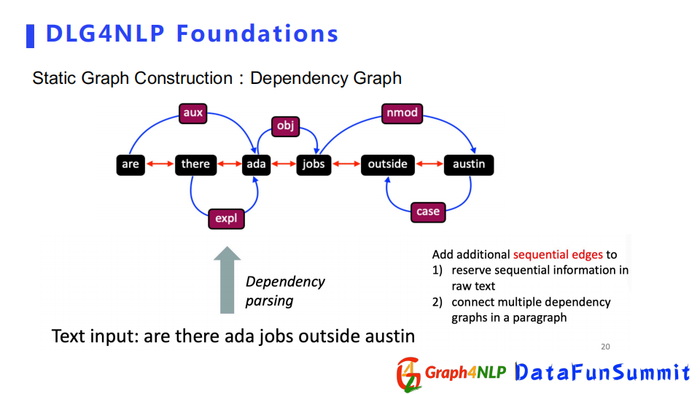
根据不同的信息或者文本,静态图可以进一步细分。
首先是Dependence Graph,该图结构依赖于dependence parsing,可以用来捕捉句子的句法信息,它更注重两个词之间的句法关系,所以该图结构是一个比较简洁的构图表示。如果我们想用图表示整个文档的话,我们可以结合连续边的信息来表示文档中句子之间的前后关系。
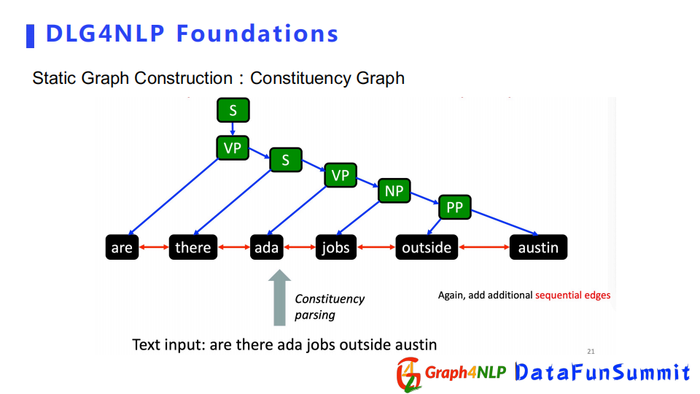
相对Dependence Graph,Constituency Graph展现的是句子的句法信息,更注重整个句子的结构,而不是局限于句子中两个词之间的句法关系。所以它更全面地展示了整个句子的结构性。
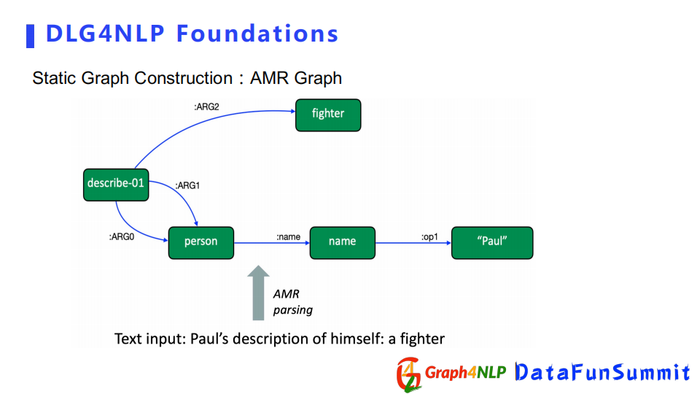
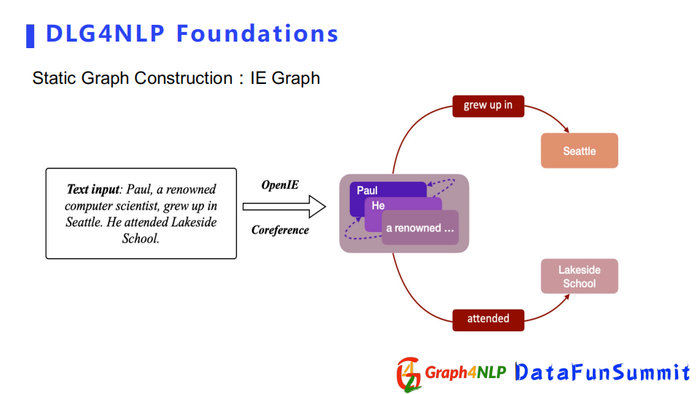
其次介绍AMR Graph和IE Graph,它们都是用来捕捉句子的语义信息,更注重两个词之间语义关系。比如IE Graph例子里面Paul是个人名,然后Seattle是个地名,所以我们首先需要表示它们俩属于实体,同时也需要知道两个实体之间的关系是一种grew up in的语义关系。根据实体关系,可以构造出IE Graph作为最终的构图。
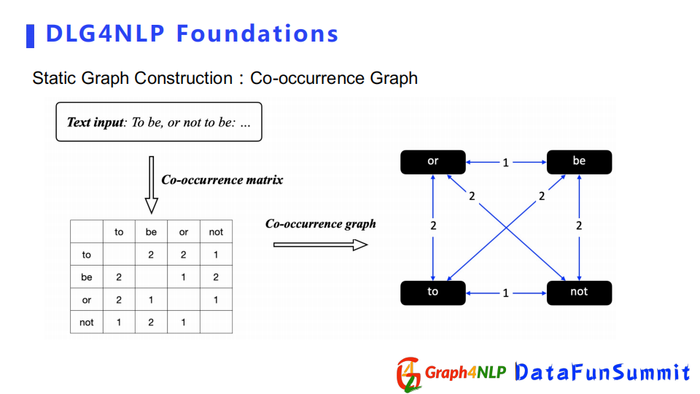
除了之前几种构造图外,还有Co-occurrence Graph,它是通过统计两个词同时出现的次数,得到Co-occurrence矩阵,然后将矩阵作为构图的邻接矩阵。
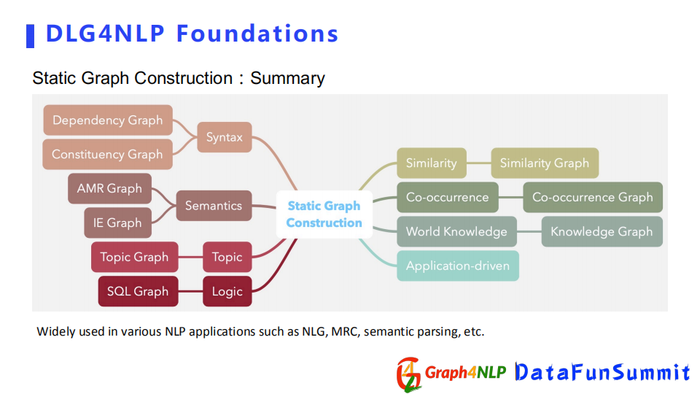
总结以上例子,静态图构建是需要额外的领域信息来增强句子本身的信息组成的图结构。常用的信息有句法信息、语义信息、主题逻辑信息、co-occurrence信息,甚至基于应用的信息。所以根据不同的领域信息,可以构造出不同的静态图结构。
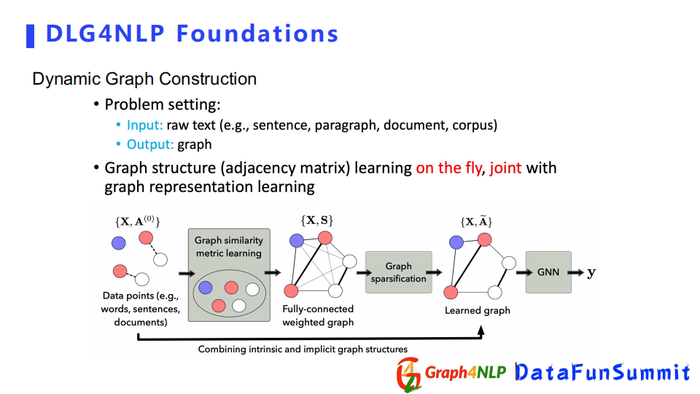
下面介绍另外一种构图方式即动态构图,动态图构造不需要有额外的领域知识去指导如何构图。该方法直接把文本丢给机器,让机器自己去学习图结构。
例如有若干个表示为word或者句子的未知关系节点,首先通过图相似矩阵学习的方式去构造一个全连接图,然后对其做稀疏化操作得到稀疏图,然后进行图表征学习。
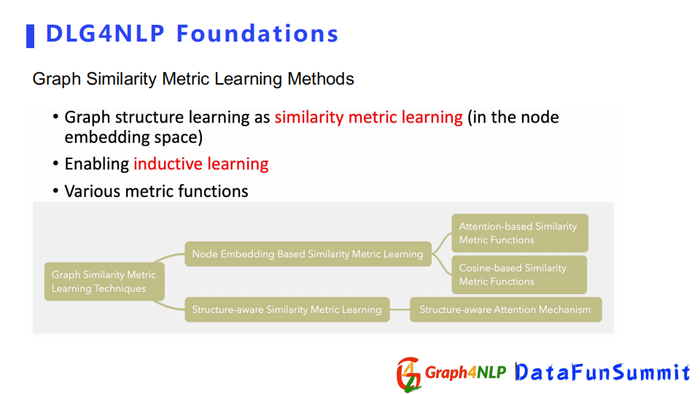
动态图构建中最重要的一个步骤是相似矩阵学习,其核心是计算任意两个节点特征向量相似度。首先需要设置一个相似的kernel去定义这两个embedding的相似度。两种典型的做法:一个是Node Embedding Based方法,第二个是Structure-aware方法,下面分别介绍这两种方法。
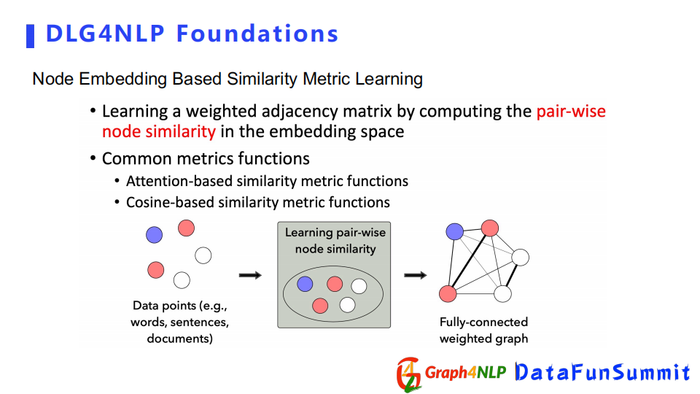
Node Embedding Based方法依靠两个节点的表征向量(embedding)。先计算两个节点embedding的相似度,然后把相似度作为加权的邻接矩阵里面的值。特征向量计算相似度的方式也分两种,一个是attention based,一个是cosine based。
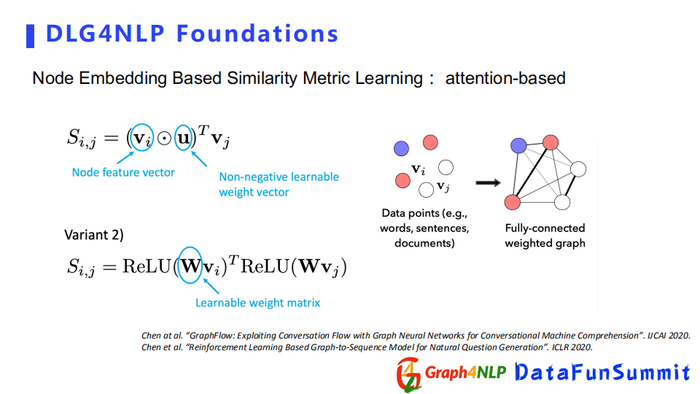
Attention-based的方式在计算相似度时,会有可学习的参数来帮助计算每对节点对之间的attention,它其实有两种方式来计算attention:
第一种是假设对所有的节点都共享可学习的参数,可学习参数是一个向量。
第二种方式是每一对节点都有自己的可学习的参数,这里可学习的参数是一个矩阵了,矩阵里面N代表节点的数量。
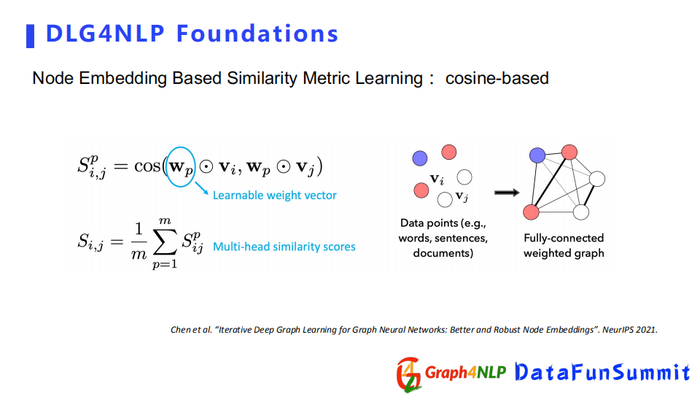
Cosine-based方法是先把节点的表征向量都乘以一个可学习的参数矩阵,相当于将其投影到另一个新的空间,再计算新空间下两个表征向量之间的cosine值。如果想让函数更加具有张力,可以借鉴多头机制(multi-head)设置多个投影空间,即学多个参数。对于每一个头参数都会有一个cosine值,然后把所有的cosine求平均,即为最终的cosine值。
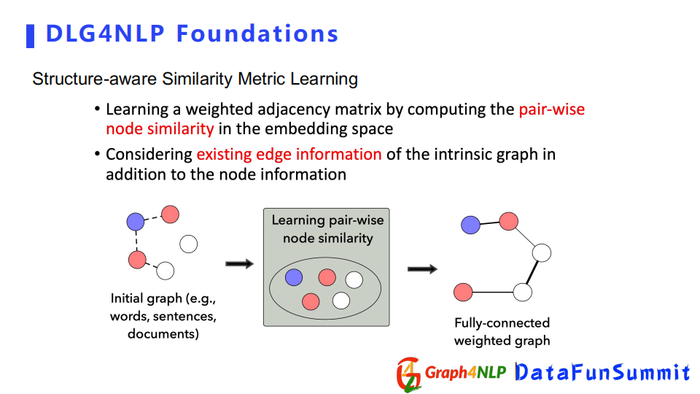
在计算相似度时有时不仅要考虑node embedding,还要考虑图本身的结构。可以用structure-aware相似矩阵来学习本身的初始结构,但该结构不确定对下游任务的影响,但是可以先用起来,然后去算structure-aware相似度。
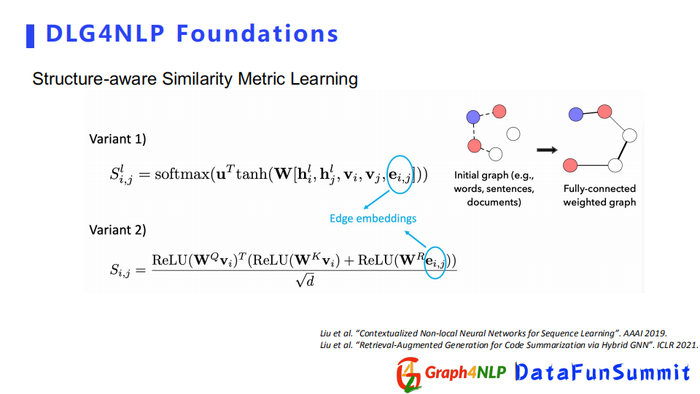
structure-aware相似矩阵计算其相似度也有两种方式,计算相似度时都将边界的embedding算进去。
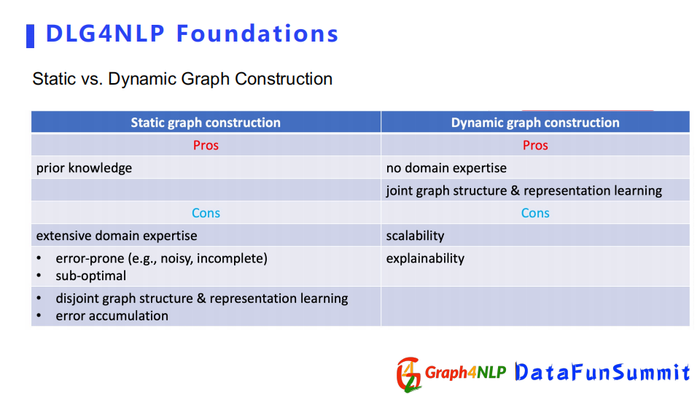
下面对动态图和静态图的构造做一个总结:
a) 静态图的优点可以依靠认为构造去捕捉一些先验目标知识,其缺点是人为构造会产生噪声。同时无法确定构建的图结构对下游任务是否有所帮助。当我们确定所掌握的领域知识是跟下游任务是匹配时,可以应用静态图结构。
b) 动态图的优点是比较简便,不需要额外的领域知识直接让机器去学最优的图结构,其图结构和图表征的学习过程可以相互促进。缺点是图结构的可解释性几乎为零,不太能解释两个节点之间的关系和代表的含义,第二个缺点是由于是全连接的图导致稳定性很差。当缺少一些领域知识或者不确定用什么图去解决下游任务时,可以选择动态图构建来帮我们去学最优的图结构。下面介绍如何做表征学习。
2. 如何做NLP的图表征学习

图表征学习分为三种,为Homogeneous Graph、Multi-relational Graph和Heterogenous graph。Homogeneous Graph只有一种节点类型以及一种边类型。Multi-relational Graph是一种节点类型以及多种边类型。Heterogenousgraph则是多种节点类型和多种边类型。
下面分别介绍这三种不同的图表征学习。
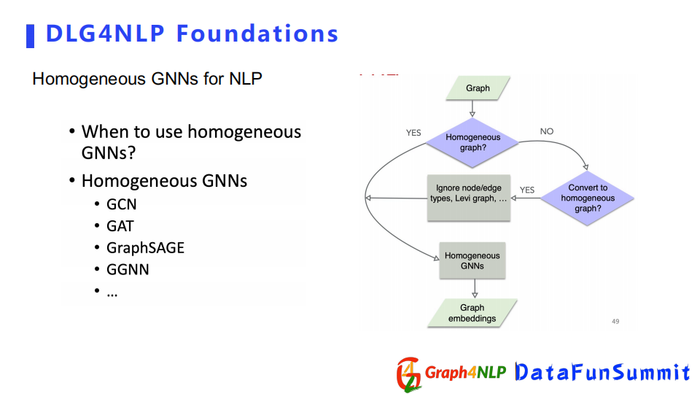
Homogeneous Graph的神经网络比较简单,构建来源有两种,一种是本身图结构就是homogeneous,第二种是通过转换操作,把non-homogeneous graph转化成一个homogeneous graph。
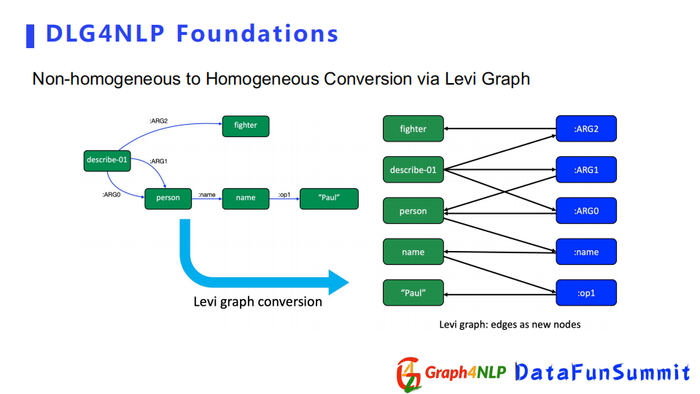
接下来举例子介绍,如何把不适合的non-homogeneous graph转化成homogeneous graph。左边图结构是一个AMR graph,有多种不同的关系,把每个关系的ARG值当成一个节点,这样就可以把它转化成了只有一种ARG值的graph,如果将节点看作同等对,其就是一个homogeneous graph。
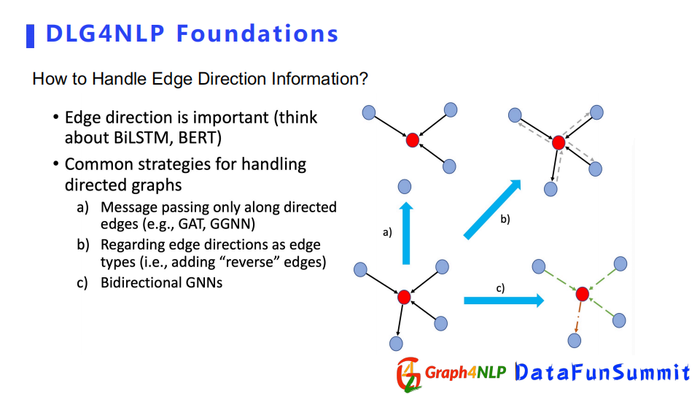
还有一个比较关键的问题,在构图中会经常遇到连接的边具有方向性。边的方向性在表示两个节点关系上是非常重要的。比如说在处理序列时,BiLSTM结构之所以效果很好,其实也是考虑到这种方向性,所以在图结构上也要考虑这个方向性。目前处理方向有三个选择:
第一个是在信息传递时,只让信息沿着方向传播,例如a中的红色节点跟四个节点连接,但是因为让信息只沿着节点的箭头方向传播,所以它只受三个邻居节点的影响。
第二个是把edge的两个方向当成两个edge种类,产生一个多关系的graph。
第三个是设计Bidirectional GNNs,直接用这种特殊的图神经网络去解决问题。
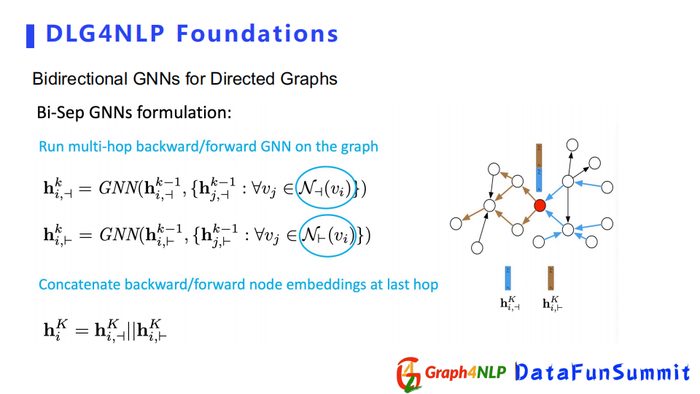
下面详细介绍特殊的Bidirectional GNNs,该图神经网络分两个类型:
第一种类型是对每一个方向都会搭建两个独立的卷积网络,分别学习embedding,到最后一层时,再把两个方向得到的节点表征连接到一起得到最终的表征。
另外一种类型不同之处在于,虽然有两个不同方向的卷积网络,但在每一层卷积之后都会把学到的节点表征合到一起,把新的节点表征去分别送到下一层两个方向的卷积。
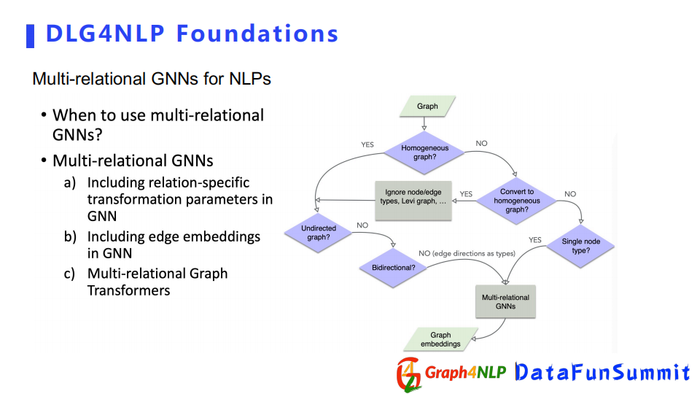
接下来介绍Multi-relation GNNs,其方法分为三类:
第一种是引入不同的与type相关的可训练卷积参数。
第二种直接引入edge embeddings,来表示不同的关系。
第三种利用专门的Multi-Relation Graph Transformer。
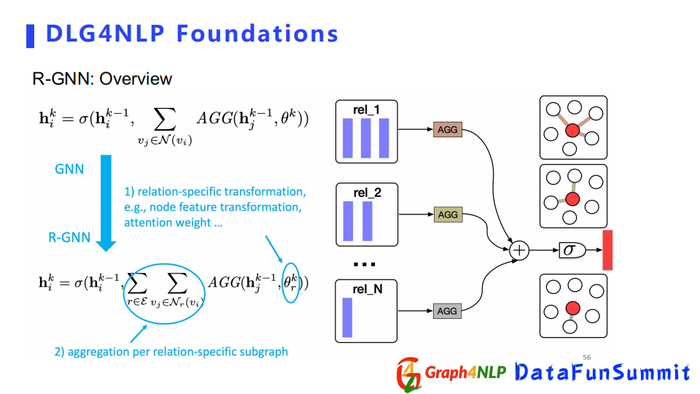
下面是处理Multi-relation的方法。
第一种方法是对每一个关系学一个卷积核,相比于传统的GNN,R-GGN有一个参数θ,对每个type都会学一个θ,每一个关系都会得到节点表征,然后把得到的节点表征做一个加和。
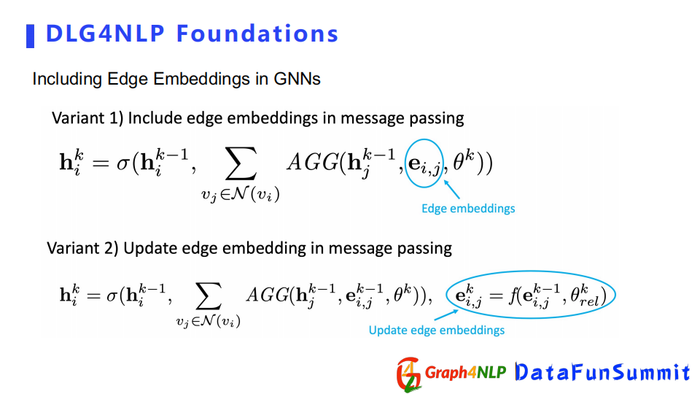
第二种直接引入边的表征向量,其核心是在做message传播时,把边的表征向量加进来可以捕捉不同边的种类。引入边表征向量有两种方式,一种是边表征向量从头到尾是固定不变的,另外一种是边的表征向量像节点一样,在传播中不断地更新迭代。
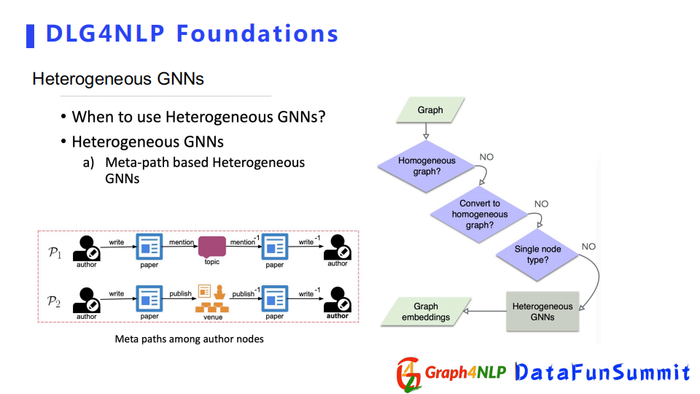
eterogeneousGraph在NLP领域里面更多用的是基于meta-path的GNNs。详细介绍可以看ACL2020的文章。
3. NLP任务重的图编码解码模型

在经典的NLP任务里面,seq2seq的架构相对比较流行,比如自然语言翻译这种实际问题,但是这种结构只能处理序列转换,无法解决图结构,所以为了把图结构引入整个NLP任务,需要采用Graph2Seq的结构。
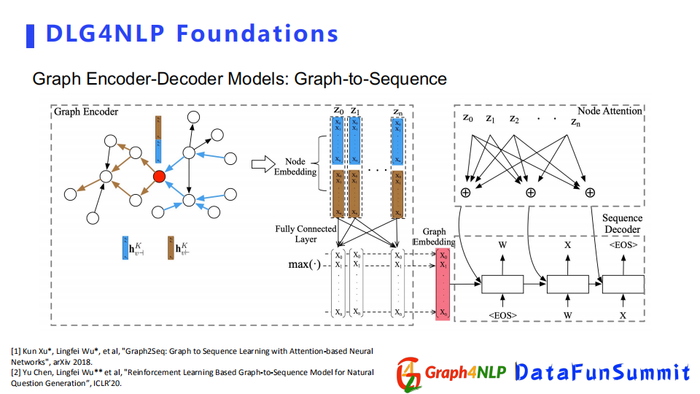
目前有两个比较主流的结构,第一个是由encoder-decoder组成,其encoder是基于GNN神经网络组成,将图作为输入图的embedding,然后decoder选择为NLP里针对不同下游任务所使用的语言生成器。
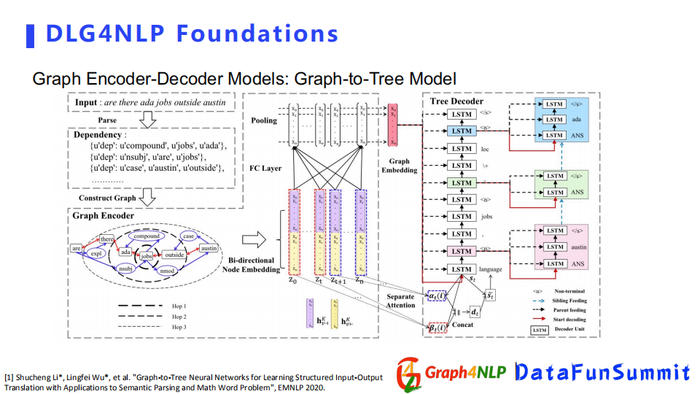
第二种结构是graph-to-Tree Model,输出不只是需要sequence,我们还需要更详细的图结构文本。比如程序语言的生成,需要把它表示成为tree的结构模型来解决任务。
--
03 DLG4NLP典型的应用
接下来介绍Graph NLP里面主要模型和方法的两个典型应用。
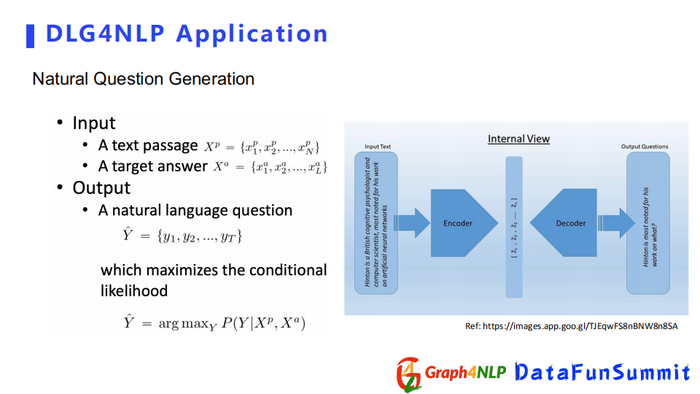
一种广泛的应用是文本问题生成,即根据输入的答案,生成对应的问题。该应用可以看成一个生成问题,目的是希望decoder学到一个基于条件的分布。
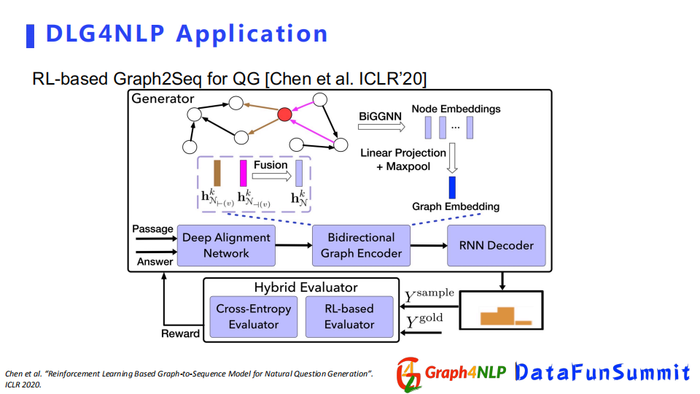
在ICLR220的这篇文章中,它是利用Graph2Seq的结构去解决生成问题,把输入表示成一个图结构,用BiGGNN去学习节点表征,再配上RNN decoder做最后的问题生成。
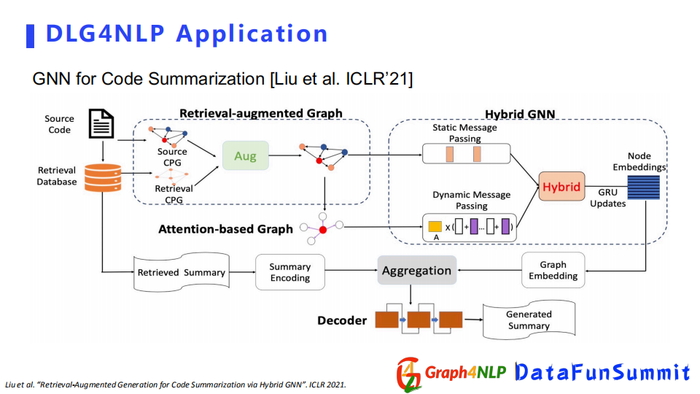
另外一篇文章是总结概要的应用,它的目的就是把整个比较大的文章输入进去,得到一个短摘要。该文章收录在ICLR2021的summary session中。
--
04 DLG4NLP Python开源库
最后介绍一下我们团队开发的开源python库Graph4NLP。
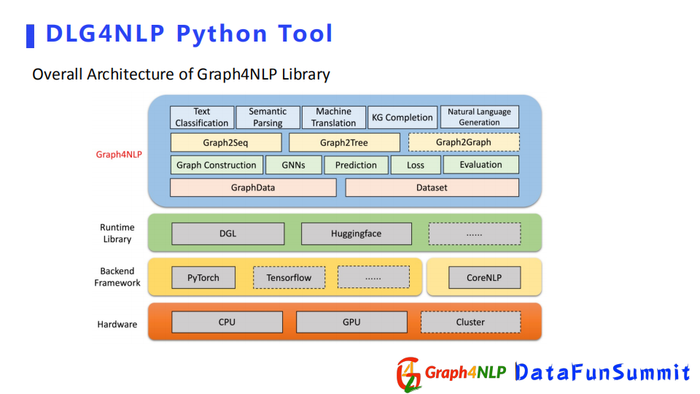
首先我们开源库基于pytorch、DGL和CoreNLP开发,并且提供了Huggingface接口,进而可以使用bert之类的模型。
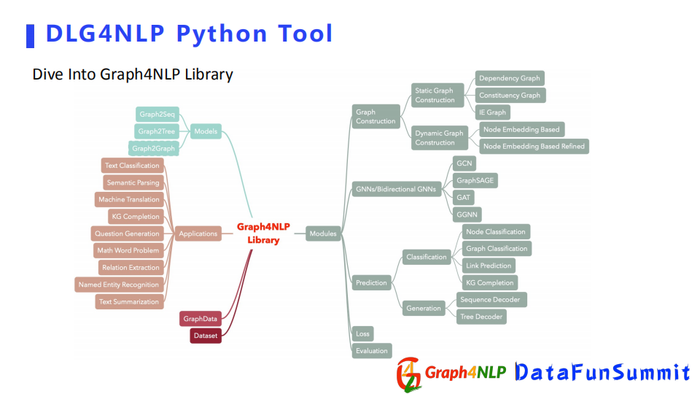
下面是对开源库功能函数的概览,其核心的module包含了Graph Construction即静态图构建和动态图构建。还有其下游的任务,比如分类任务和生成任务。另外还包括一些比较典型的图神经网络GCN和GraphSAGE等。我们还用python库去实现了一些比较经典文章里的一些模型,并且取得了不错的效果。
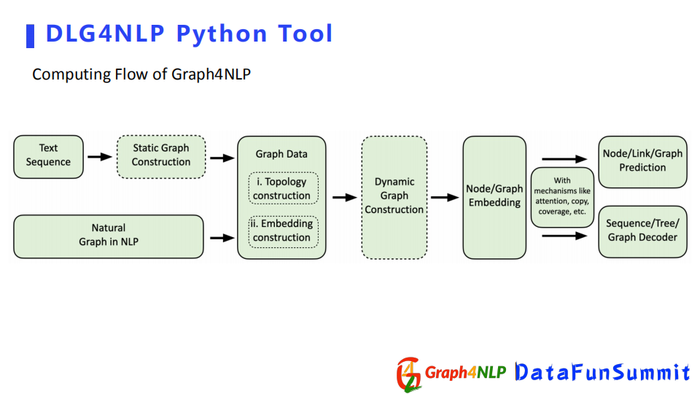
接下来展示下python库如何做完成NLP任务。
流程为首先做一个图构建,将图结构输进去,用python库的Graph Data产生Data数据类型,然后用GNN图学习模块优化该图,或者进行图的表征学习,最后可以根据具体的任务去选择下游的模块,或者做分类、生成任务等。
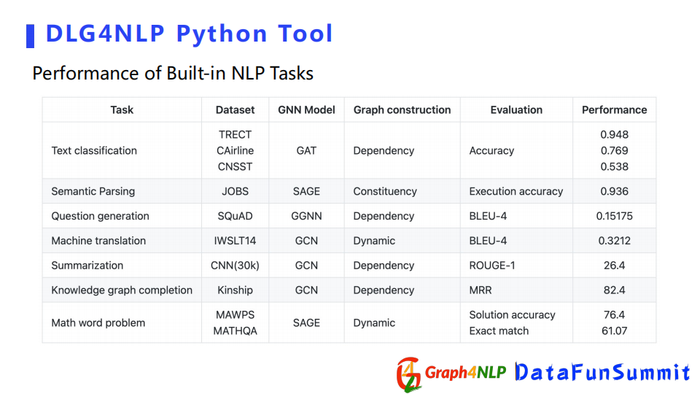
这个表格展示了python库在不同NLP任务上取得的不错结果。如果大家想探索图深度学习在NLP应用的话,请关注和尝试该library,欢迎大家多提宝贵的意见,因为我们还在不断的去更新我们的开源库。今天就是我分享的全部内容,谢谢大家的关注。
--
05 精彩问答
Q1:现在像知识图谱的图表示学习的算法多吗?
A:目前边的网络更多的是生成homogeneous graph, Heterogeneous graph也有一两篇文章。
Q2:Bert加图学习训练不起来怎么办?
A:有可能是构建图结构有问题,或者调参没调好,可以试下上面讲的开源python库。先去做一个尝试,然后对照排查问题。
Q3:最近transformer相对比较火,在用于NLP文本建模时用全连接的图来进行建模,如果找一些比较稀疏的有语义的图,也可以取得非常好的结果。您觉得有没有可能把这两种方法结合起来,同时利用全连接的图和语义的图?
A:我觉得transformer本身就是一种GNN形式,只不过它学的是个全连接图,它有点类似于我刚才讲的动态图构建,因为动态图的构建本身也是学一个全连接图,如果你本身有原始的图,可以借用原始的图把它放到动态图,然后两两去结合促进后面的图学习。
Q4:将图神经网络用于NLP,重点是在于图的构建还是在于新的模型?
A:目前图学习的效果已经不错了,但基于不同应用,我觉得图的构建是比较关键的一件事情,尤其是如果你做静态图构建的时候,你的信息选取不对或者添加的图信息不对的话,你有可能会引入一些bias或一些noise,然后导致学不到你想要的一个信息,或者得到了更多noise。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:基于图深度学习的自然语言处理方法和应用 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 