主要的思想是:
SSD 是基于一个前向传播 CNN 网络,产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个非极大值抑制Non-maximum suppression得到最终的 predictions。

本文添加了额外辅助的网络结构
1. Mult-scale feature map for detection
在base network后,添加一些卷积层,这些层的大小逐渐减小,可以进行多尺度预测
2. Convolutional predictors for detection
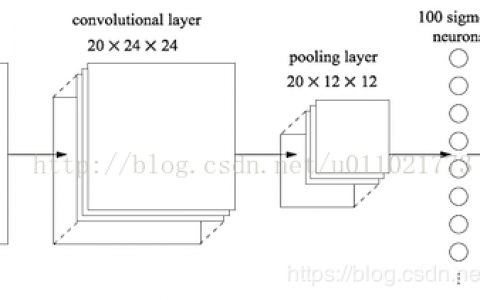
每一个新添加的层,可以使用一系列的卷积核进行预测。对于一个大小为m*n、p通道的特征层,使用3*3的卷积核进行预测,在某个位置上预测出一个值,该值可以是某一类别的得分,也可以是相对于default bounding boxes的偏移量,并且在图像的每个位置都将产生一个值,如图2所示。
3. Default boxes and aspect ratio
在特征图的每个位置预测K个box。对于每个box,预测C个类别得分,以及相对于default bounding box的4个偏移值,这样需要(C+4)*k个预测器,在m*n的特征图上将产生(C+4)*k*m*n个预测值。这里,default bounding box类似于FasterRCNN中anchors,如图1所示。
这里的 default box 很类似于 Faster R-CNN 中的 Anchor boxes,关于这里的 Anchor boxes,详细的参见原论文。但是又不同于 Faster R-CNN 中的,本文中的 Anchor boxes 用在了不同分辨率的 feature maps 上。
参考文献:
https://blog.csdn.net/u013989576/article/details/73439202/
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:基于深度学习的目标检测算法:SSD - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫