? 作者:韩信子@ShowMeAI
? 数据分析实战系列:https://www.showmeai.tech/tutorials/40
? 机器学习实战系列:https://www.showmeai.tech/tutorials/41
? 本文地址:https://www.showmeai.tech/article-detail/300
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容
一份来自『RESEARCH AND MARKETS』的二手车报告预计,从 2022 年到 2030 年,全球二手车市场将以 6.1% 的复合年增长率增长,到 2030 年达到 2.67 万亿美元。人工智能技术的广泛使用增加了车主和买家之间的透明度,提升了购买体验,极大地推动了二手车市场的增长。

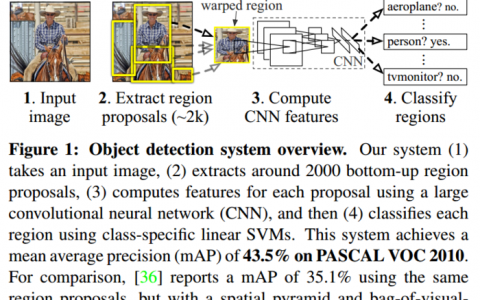
基于机器学习对二手车交易价格进行预估,这一技术已经在二手车交易平台中广泛使用。在本篇内容中,ShowMeAI 会完整构建用于二手车价格预估的模型,并部署成web应用。

? 数据分析处理&特征工程
本案例涉及的数据集可以在 ? kaggle汽车价格预测 获取,也可以在ShowMeAI的百度网盘地址直接下载。
? 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [11] 构建AI模型并部署Web应用,预测二手车价格 『CarPrice 二手车价格预测数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
① 数据探索
数据分析处理涉及的工具和技能,欢迎大家查阅ShowMeAI对应的教程和工具速查表,快学快用。

我们先加载数据并初步查看信息。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import pickle
%matplotlib.inline
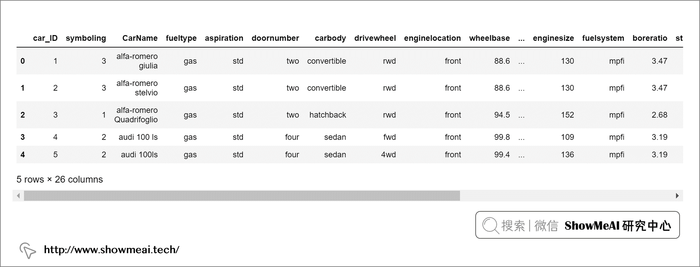
df=pd.read_csv('CarPrice_Assignment.csv')
df.head()
数据 Dataframe 的数据预览如下:
我们对属性字段做点分析,看看哪些字段与价格最相关,我们先计算相关性矩阵
df.corr()

再对相关性进行热力图可视化。
sns.set(rc={"figure.figsize":(20, 20)})
sns.heatmap(df.corr(), annot = True)

其中各字段和price的相关性如下图所示,我们可以看到其中有些字段和结果之间有非常强的相关性。
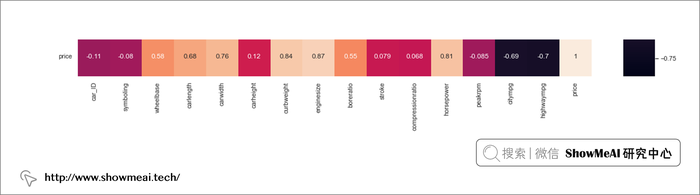
我们可以对数值型字段,分别和price目标字段进行绘图详细分析,如下:
for col in df.columns:
if df[col].dtypes != 'object':
sns.lmplot(data = df, x = col, y = 'price')
可视化结果图如下:
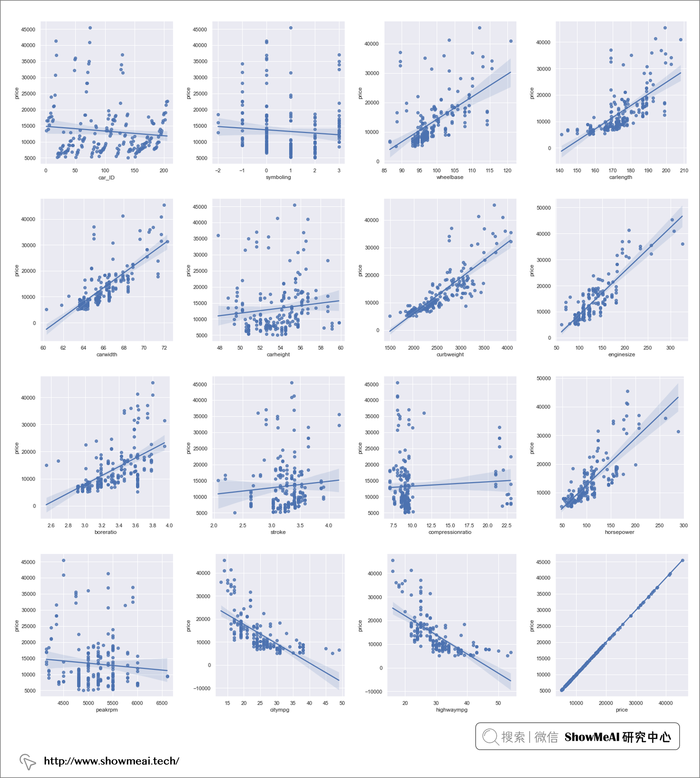
我们把一些与价格相关性低(r<0.15)的字段删除掉:
df.drop(['car_ID'], axis = 1, inplace = True)
to_drop = ['peakrpm', 'compressionratio', 'stroke', 'symboling']
df.drop(df[to_drop], axis = 1, inplace = True)
② 特征工程
特征工程涉及的方法技能,欢迎大家查阅ShowMeAI对应的教程文章,快学快用。
车名列包括品牌和型号,我们对其拆分并仅保留品牌:
df['CarName'] = df['CarName'].apply(lambda x: x.split()[0])
输出:

我们发现有一些车品牌的别称或者拼写错误,我们做一点数据清洗如下:
df['CarName'] = df['CarName'].str.lower()
df['CarName']=df['CarName'].replace({'vw':'volkswagen','vokswagen':'volkswagen','toyouta':'toyota','maxda':'mazda','porcshce':'porsche'})
再对不同车品牌的数量做绘图,如下:
sns.set(rc={'figure.figsize':(30,10)})
sns.countplot(data = df, x='CarName')

③ 特征编码&数据变换
下面我们要做进一步的特征工程:
- 类别型特征
大部分机器学习模型并不能处理类别型数据,我们会手动对其进行编码操作。类别型特征的编码可以采用 序号编码 或者 独热向量编码(具体参见ShowMeAI文章 机器学习实战 | 机器学习特征工程最全解读),独热向量编码示意图如下:

- 数值型特征
针对不同的模型,有不同的处理方式,比如幅度缩放和分布调整。
下面我们先将数据集的字段分为两类:类别型和数值型:
categorical = []
numerical = []
for col in df.columns:
if df[col].dtypes == 'object':
categorical.append(col)
else:
numerical.append(col)
下面我们使用pandas中的哑变量变换操作把所有标记为“categorical”的特征进行独热向量编码。
# 独热向量编码
x1 = pd.get_dummies(df[categorical], drop_first = False)
x2 = df[numerical]
X = pd.concat([x2,x1], axis = 1)
X.drop('price', axis = 1, inplace = True)
下面我们对数值型特征进行处理,首先我们看看标签字段price,我们先绘制一下它的分布,如下:
sns.histplot(data=df, x="price", kde=True)
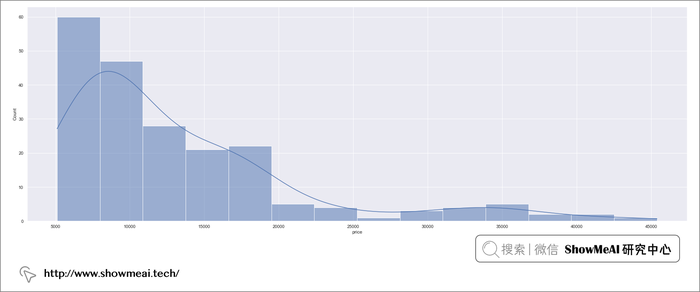
大家从图上可以看出这是一个有偏分布。我们对它做一个对数处理,以使其更接近正态分布。(另外一个考量是,如果我们以对数后的结果作为标签来建模学习,那还原回 price 的过程,会使用指数操作,这能保证我们得到的价格一定是正数) ,代码如下:
#修复偏态分布
df["price_log"]=np.log(df["price"])
sns.histplot(data=df, x="price_log", kde=True)
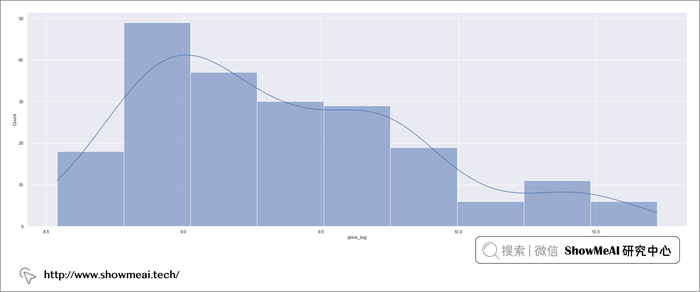
校正过后的数据分布更接近正态分布了,做过这些基础处理之后,我们准备开始建模了。
? 机器学习建模
① 数据集切分&数据变换
让我们拆分数据集为训练和测试集,并对其进行基本的数据变换操作:
#切分数据
from sklearn.model_selection import train_test_split
y = df['price_log']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.333, random_state=1)
#特征工程-幅度缩放
from sklearn.preprocessing import StandardScaler
sc= StandardScaler()
X_train[:, :(len(x1.columns))]= sc.fit_transform(X_train[:, :(len(x1.columns))])
X_test[:, :(len(x1.columns))]= sc.transform(X_test[:, :(len(x1.columns))])
② 建模&调优
建模涉及的方法技能,欢迎大家查阅ShowMeAI对应的教程文章,快学快用。
我们这里的数据集并不大(样本数不多),基于模型复杂度和效果考虑,我们先测试 4 个模型,看看哪一个表现最好。
- Lasso regression
- Ridge regression
- 随机森林回归器
- XGBoost回归器
我们先从scikit-learn导入对应的模型,如下:
#回归模型
from sklearn.linear_model import Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
③ 建模 pipeline
为了让整个建模过程更加紧凑简介,我们创建一个pipeline来训练和调优模型。 具体步骤为:
- 使用随机超参数训练评估每个模型。
- 使用网格搜索调优每个模型的超参数。
- 用找到的最佳参数重新训练评估模型。
我们先从 scikit-learn 导入网格搜索:
from sklearn.model_selection import GridSearchCV
接着我们构建一个全面的评估指标函数,打印每个拟合模型的指标(R 平方、均方根误差和平均绝对误差等):
def metrics(model):
res_r2 = []
res_RMSE = []
res_MSE = []
model.fit(X_train, y_train)
Y_pred = model.predict(X_test)
#计算R方
r2 = round(r2_score(y_test, Y_pred),4)
print( 'R2_Score: ', r2)
res_r2.append(r2)
#计算RMSE
rmse = round(mean_squared_error(np.exp(y_test),np.exp(Y_pred), squared=False), 2)
print("RMSE: ",rmse)
res_RMSE.append(rmse)
#计算MAE
mse = round(mean_absolute_error(np.exp(y_test),np.exp(Y_pred)), 2)
print("MAE: ", mse)
res_MSE.append(mse)
下面要构建pipeline了:
# 候选模型
models={
'rfr':RandomForestRegressor(bootstrap=False, max_depth=15, max_features='sqrt', min_samples_split=2, n_estimators=100),
'lasso':Lasso(alpha=0.005, fit_intercept=True),
'ridge':Ridge(alpha = 10, fit_intercept=True), 'xgb':xgb.XGBRegressor(bootstrap=True, max_depth=2, max_features = 'auto', min_sample_split = 2, n_estimators = 100)
}
# 不同的模型不同建模方法
for mod in models:
if mod == 'rfr' or mod == 'xgb':
print('Untuned metrics for: ', mod)
metrics(models[mod])
print('\n')
print('Starting grid search for: ', mod)
params = {
"n_estimators" : [10,100, 1000, 2000, 4000, 6000],
"max_features" : ["auto", "sqrt", "log2"],
"max_depth" : [2, 4, 8, 12, 15],
"min_samples_split" : [2,4,8],
"bootstrap": [True, False],
}
if mod == 'rfr':
rfr = RandomForestRegressor()
grid = GridSearchCV(rfr, params, verbose=5, cv=2)
grid.fit(X_train, y_train)
print("Best score: ", grid.best_score_ )
print("Best: params", grid.best_params_)
else:
xgboost = xgb.XGBRegressor()
grid = GridSearchCV(xgboost, params, verbose=5, cv=2)
grid.fit(X_train, y_train)
print("Best score: ", grid.best_score_ )
print("Best: params", grid.best_params_)
else:
print('Untuned metrics for: ', mod)
metrics(models[mod])
print('\n')
print('Starting grid search for: ', mod)
params = {
"alpha": [0.005, 0.05, 0.1, 1, 10, 100, 290, 500],
"fit_intercept": [True, False]
}
if mod == 'lasso':
lasso = Lasso()
grid = GridSearchCV(lasso, params, verbose = 5, cv = 2)
grid.fit(X_train, y_train)
print("Best score: ", grid.best_score_ )
print("Best: params", grid.best_params_)
else:
ridge = Ridge()
grid = GridSearchCV(ridge, params, verbose = 5, cv = 2)
grid.fit(X_train, y_train)
print("Best score: ", grid.best_score_ )
print("Best: params", grid.best_params_)
以下是随机调整模型的结果:

在未调超参数的情况下,我们看到差异不大的R方结果,但 Lasso 的误差最小。
我们再看看网格搜索的结果,以找到每个模型的最佳参数:

现在让我们将这些参数应用于每个模型,并查看结果:
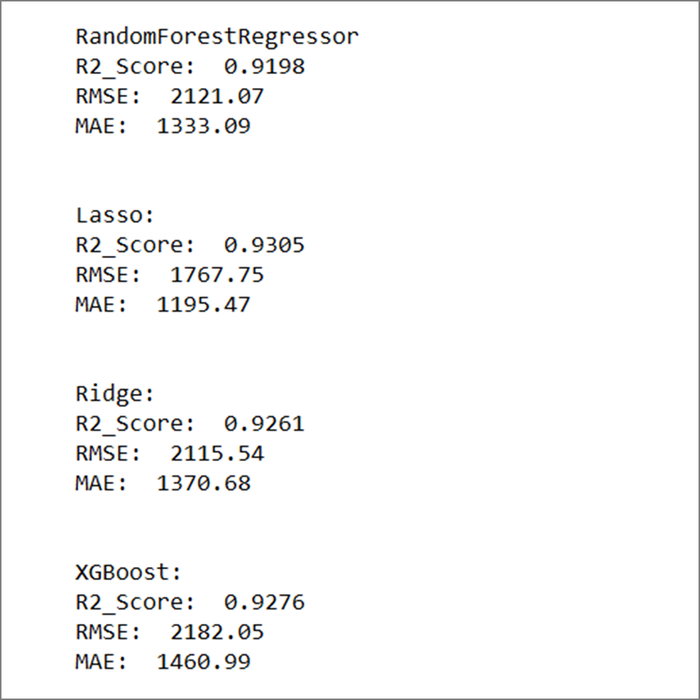
调参后的结果相比默认超参数,都有提升,但 Lasso回归依旧有最佳的效果(与本例的数据集样本量和特征相关性有关),我们最终保留Lasso回归模型并存储模型到本地。
lasso_reg = Lasso(alpha = 0.005, fit_intercept = True)
pickle.dump(lasso_reg, open('model.pkl','wb'))
? web应用开发
下面我们把上面得到的模型部署到网页端,形成一个可以实时预估的应用,我们这里使用 gradio 库来开发 Web 应用程序,实际的web应用预估包含下面的步骤:
- 用户在网页表单中输入数据
- 处理数据(特征编码&变换)
- 数据处理以匹配模型输入格式
- 预测并呈现给用户的价格
① 基本开发
首先,我们导入原始数据集和做过数据处理(独热向量编码)的数据集,并保留它们各自的列。
# df的列
#Columns of the df
df = pd.read_csv('df_columns')
df.drop(['Unnamed: 0','price'], axis = 1, inplace=True)
cols = df.columns
# df的哑变量列
dummy = pd.read_csv('dummy_df')
dummy.drop('Unnamed: 0', axis = 1, inplace=True)
cols_to_use = dummy.columns
接下来,对于类别型特征,我们构建web应用端下拉选项:
# 构建应用中的候选值
# 车品牌首字母大写
cars = df['CarName'].unique().tolist()
carNameCap = []
for col in cars:
carNameCap.append(col.capitalize())
#fueltype字段
fuel = df['fueltype'].unique().tolist()
fuelCap = []
for fu in fuel:
fuelCap.append(fu.capitalize())
#carbod, engine type, fuel systems等字段
carb = df['carbody'].unique().tolist()
engtype = df['enginetype'].unique().tolist()
fuelsys = df['fuelsystem'].unique().tolist()
OK,我们会针对上面这些模型预估需要用到的类别型字段,开发下拉功能并添加候选项。
下面我们定义一个函数进行数据处理,并预估返回价格:
# 数据变换处理以匹配模型
def transform(data):
# 数据幅度缩放
sc = StandardScaler()
# 导入模型
model= pickle.load(open('model.pkl','rb'))
# 新数据Dataframe
new_df = pd.DataFrame([data],columns = cols)
# 区分类别型和数值型特征
cat = []
num = []
for col in new_df.columns:
if new_df[col].dtypes == 'object':
cat.append(col)
else:
num.append(col)
x1_new = pd.get_dummies(new_df[cat], drop_first = False)
x2_new = new_df[num]
X_new = pd.concat([x2_new,x1_new], axis = 1)
final_df = pd.DataFrame(columns = cols_to_use)
final_df = pd.concat([final_df, X_new])
final_df = final_df.fillna(0)
X_new = final_df.values
X_new[:, :(len(x1_new.columns))]= sc.fit_transform(X_new[:,
:(len(x1_new.columns))])
output = model.predict(X_new)
return "The price of the car " + str(round(np.exp(output)[0],2)) + "$"
下面我们在gradio web应用程序中创建元素,我们会为类别型字段构建下拉菜单或复选框,为数值型字段构建输入框。 参考代码如下:
# 类别型
car = gr.Dropdown(label = "Car brand", choices=carNameCap)
# 数值型
curbweight = gr.Slider(label = "Weight of the car (in pounds)", minimum = 500, maximum = 6000)
现在,让我们在界面中添加所有内容:
一切就绪就可以部署了!
② 部署
下面我们把上面得到应用部署一下,首先我们对于应用的 ip 和端口做一点设定
export GRADIO_SERVER_NAME=0.0.0.0
export GRADIO_SERVER_PORT="$PORT"
大家确定使用pip安装好下述依赖:
numpy
pandas
scikit-learn
gradio
Flask
argparse
gunicorn
rq
接着运行 python WebApp.py 就可以测试应用程序了,WebApp.py内容如下:
import gradio as gr
import numpy as np
import pandas as pd
import pickle
from sklearn.preprocessing import StandardScaler
# 数据字典
asp = {
'Standard':'std',
'Turbo':'turbo'
}
drivew = {
'Rear wheel drive': 'rwd',
'Front wheel drive': 'fwd',
'4 wheel drive': '4wd'
}
cylnum = {
2: 'two',
3: 'three',
4: 'four',
5: 'five',
6: 'six',
8: 'eight',
12: 'twelve'
}
# 原始df字段名
df = pd.read_csv('df_columns')
df.drop(['Unnamed: 0','price'], axis = 1, inplace=True)
cols = df.columns
# 独热向量编码过后的字段名
dummy = pd.read_csv('dummy_df')
dummy.drop('Unnamed: 0', axis = 1, inplace=True)
cols_to_use = dummy.columns
# 车品牌名
cars = df['CarName'].unique().tolist()
carNameCap = []
for col in cars:
carNameCap.append(col.capitalize())
# fuel
fuel = df['fueltype'].unique().tolist()
fuelCap = []
for fu in fuel:
fuelCap.append(fu.capitalize())
#For carbod, engine type, fuel systme
carb = df['carbody'].unique().tolist()
engtype = df['enginetype'].unique().tolist()
fuelsys = df['fuelsystem'].unique().tolist()
#Function to model data to fit the model
def transform(data):
# 数值型幅度缩放
sc= StandardScaler()
# 导入模型
lasso_reg = pickle.load(open('model.pkl','rb'))
# 新数据Dataframe
new_df = pd.DataFrame([data],columns = cols)
# 切分类别型与数值型字段
cat = []
num = []
for col in new_df.columns:
if new_df[col].dtypes == 'object':
cat.append(col)
else:
num.append(col)
# 构建模型所需数据格式
x1_new = pd.get_dummies(new_df[cat], drop_first = False)
x2_new = new_df[num]
X_new = pd.concat([x2_new,x1_new], axis = 1)
final_df = pd.DataFrame(columns = cols_to_use)
final_df = pd.concat([final_df, X_new])
final_df = final_df.fillna(0)
final_df = pd.concat([final_df,dummy])
X_new = final_df.values
X_new[:, :(len(x1_new.columns))]= sc.fit_transform(X_new[:, :(len(x1_new.columns))])
print(X_new[-1].reshape(-1, 1))
output = lasso_reg.predict(X_new[-1].reshape(1, -1))
return "The price of the car " + str(round(np.exp(output)[0],2)) + "$"
# 预估价格的主函数
def predict_price(car, fueltype, aspiration, doornumber, carbody, drivewheel, enginelocation, wheelbase, carlength, carwidth,
carheight, curbweight, enginetype, cylindernumber, enginesize, fuelsystem, boreratio, horsepower, citympg, highwaympg):
new_data = [car.lower(), fueltype.lower(), asp[aspiration], doornumber.lower(), carbody, drivew[drivewheel], enginelocation.lower(),
wheelbase, carlength, carwidth, carheight, curbweight, enginetype, cylnum[cylindernumber], enginesize, fuelsystem,
boreratio, horsepower, citympg, highwaympg]
return transform(new_data)
car = gr.Dropdown(label = "Car brand", choices=carNameCap)
fueltype = gr.Radio(label = "Fuel Type", choices = fuelCap)
aspiration = gr.Radio(label = "Aspiration type", choices = ["Standard", "Turbo"])
doornumber = gr.Radio(label = "Number of doors", choices = ["Two", "Four"])
carbody = gr.Dropdown(label ="Car body type", choices = carb)
drivewheel = gr.Radio(label = "Drive wheel", choices = ['Rear wheel drive', 'Front wheel drive', '4 wheel drive'])
enginelocation = gr.Radio(label = "Engine location", choices = ['Front', 'Rear'])
wheelbase = gr.Slider(label = "Distance between the wheels on the side of the car (in inches)", minimum = 50, maximum = 300)
carlength = gr.Slider(label = "Length of the car (in inches)", minimum = 50, maximum = 300)
carwidth = gr.Slider(label = "Width of the car (in inches)", minimum = 50, maximum = 300)
carheight = gr.Slider(label = "Height of the car (in inches)", minimum = 50, maximum = 300)
curbweight = gr.Slider(label = "Weight of the car (in pounds)", minimum = 500, maximum = 6000)
enginetype = gr.Dropdown(label = "Engine type", choices = engtype)
cylindernumber = gr.Radio(label = "Cylinder number", choices = [2, 3, 4, 5, 6, 8, 12])
enginesize = gr.Slider(label = "Engine size (swept volume of all the pistons inside the cylinders)", minimum = 50, maximum = 500)
fuelsystem = gr.Dropdown(label = "Fuel system (link to ressource: ", choices = fuelsys)
boreratio = gr.Slider(label = "Bore ratio (ratio between cylinder bore diameter and piston stroke)", minimum = 1, maximum = 6)
horsepower = gr.Slider(label = "Horse power of the car", minimum = 25, maximum = 400)
citympg = gr.Slider(label = "Mileage in city (in km)", minimum = 0, maximum = 100)
highwaympg = gr.Slider(label = "Mileage on highway (in km)", minimum = 0, maximum = 100)
Output = gr.Textbox()
app = gr.Interface(title="Predict the price of a car based on its specs",
fn=predict_price,
inputs=[car,
fueltype,
aspiration,
doornumber,
carbody,
drivewheel,
enginelocation,
wheelbase,
carlength,
carwidth,
carheight,
curbweight,
enginetype,
cylindernumber,
enginesize,
fuelsystem,
boreratio,
horsepower,
citympg,
highwaympg
],
outputs=Output)
app.launch()
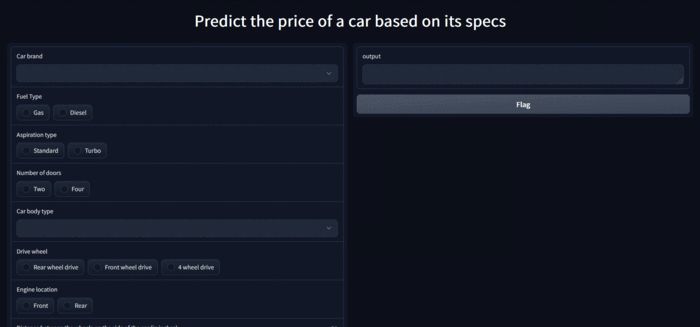
最终的应用结果如下,可以自己勾选与填入特征进行模型预估!
参考资料
- ? 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [11] 构建AI模型并部署Web应用,预测二手车价格 『CarPrice 二手车价格预测数据集』
- ⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
- ? 图解数据分析:从入门到精通系列教程 https://www.showmeai.tech/tutorials/33
- ? 数据科学工具库速查表 | Pandas 速查表 https://www.showmeai.tech/article-detail/101
- ? 数据科学工具库速查表 | Seaborn 速查表 https://www.showmeai.tech/article-detail/105
- ? 机器学习实战 | 机器学习特征工程最全解读 https://www.showmeai.tech/article-detail/208
- ? 机器学习实战 | SKLearn最全应用指南 https://www.showmeai.tech/article-detail/203

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:二手车价格预测 | 构建AI模型并部署Web应用 ⛵ - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫