深度学习小组介绍PPT
1.今天我就介绍一下深度学习,不会讲太细的东西,也不会有太多的数学的公式。


2.现在深度学习能做的事情还非常有限,为什么要去了解深度学习呢?我觉至少有两个方面,可以忽悠比人或者不被别人忽悠
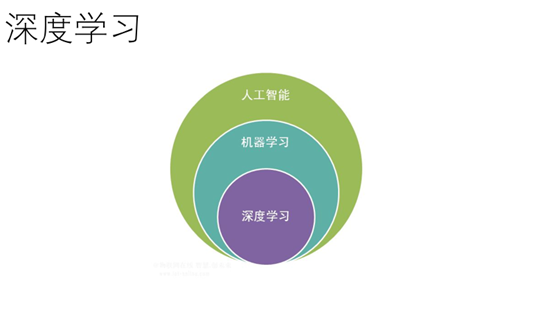
3.这张图展现了人工智能,机器学习,深度学习的关系。深度学习是机器学习现在最火的研究热点
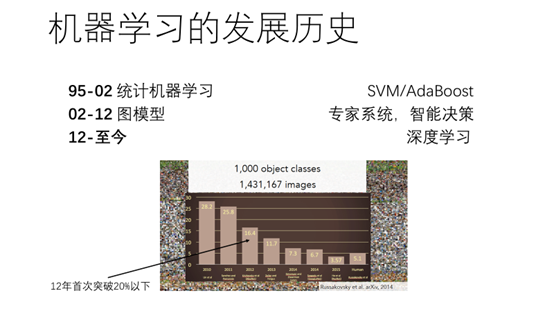
4.下面我给出了近20年机器学习的研究热点。95-02年以统计机器学习为主,代表性的研究热点有SVM/AdaBoost。02-12年以图模型为主,代表性的研究热点有专家系统,智能决策。12-至今,主要以深度学习为主。深度学习很早就提出来,早在80年代,Hinto就提出了玻尔兹曼机以及受限玻尔兹曼机,为现在才火起来呢。12年,在图像分类比赛中,基于卷积神经网络的图像分类算法首次突破了20%,带动这一波人工智能,使深度学习重新回到人们身边。
5.机器学习主要分为三大类别:监督学习,无监督学习以及增强学习。监督学习,训练的数据集是带有标签的。无监督学习,训练的数据没有标签。增强学习主要是研究智能体与环境的交互。后面会提到深度学习如何应用到这三种类别中。

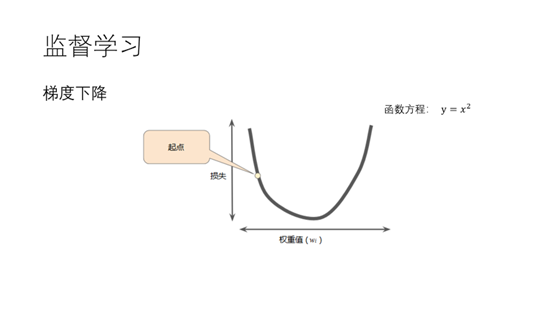
6.在介绍深度学习之前需要明白什么是梯度下降。梯度下降是一种迭代法用于最优值。这里我们假设我们的目标函数为y等于X平方。我们的目标是求出当x等于什么的时候y取得最小值。
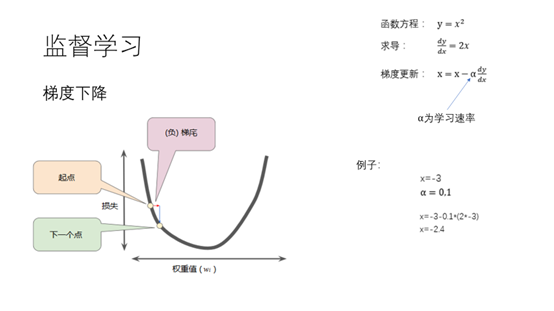
7.X在图中只要沿着下坡的方向步进就可以达到最小值了。下坡的方向也就是求导的反方向。这里的a为步进的长度。 当x=-3,a=0.1时,我们执行一次梯度更新x的值为-2.4离最优值又近了一步。
8.上面提到的目标函数比较简单。左边是循环神经网络在反向传播过程中的求导,从图中可以看出来还是比较复杂的。由于我们不是数学专业的,有些求导的技巧可能不知道,不过没有关系,有一些现成的软件可以帮助我们进行求导,并且会给出求导的步骤。
9.下面通过简单的线性回归介绍一下梯度下降法在机器学习中应用。我们要拟合的方程为
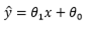
我们的目的是让估计的y值和真实的y值越小越好,所以这里我们采用最小二乘估计,得到代价函数J
对于参数,我们不断的用梯度下降进行迭代求最小值
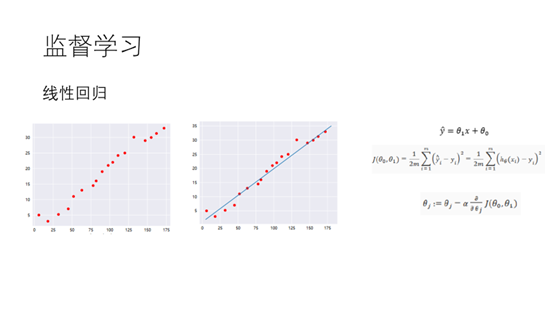
10.这里我们再来看一下一个简单的二分类问题,逻辑回归。这里有两类别蓝色和黄色,我们想要使用一条线将这两个类别分开。我们可以构造概率函数h,表示该点是蓝色的概率。为什么h可以表示蓝色点的概率函数呢?从图中我们可以看到…+b=0为我们所要求得线,在上方离这条线越远…+b的值越大,而sigmoid函数Z在0处的值为0.5,z值越大越接近1,所以可以用sigmoid来表示蓝色的概率。我们希望判断错误的概率越小越好,因此就可以构造我们的代价函数J。同样可以通过梯度下降的方法得到我们的参数。
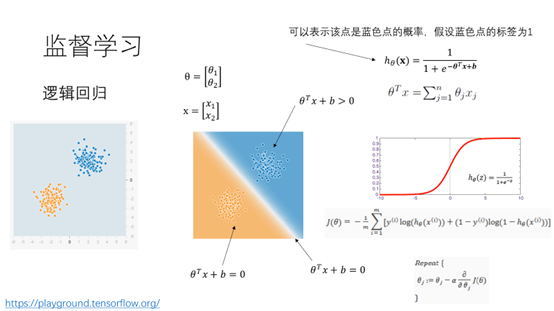
11.逻辑回归可以表示如下的概率图模型。两个输入,一个输出,激活函数为sigmoid函数。如果在中间增加一层就变成了神经网络了。这是一个最简单的神经网络,具有两个输入,8个参数,一个输出,激活函数为sigmoid。代价函数和逻辑回归的代价函数一样。由于存在多层,如何通过梯度下降的方法对这些参数进行更新呢。
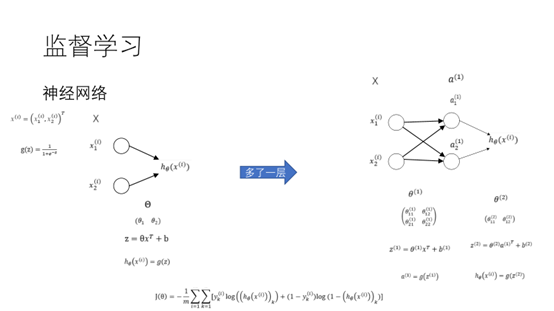
12.为了更新中间层的参数就必须用到反向传播。考虑下面的计算图。我们可以最终得到J=3a+bc。为了求J对u导数,我们可以首先求J对V的导数,再通过罗必塔法则对U求导得到我们想要的结果。通过这种思想我们就可以利用梯度下降对各层中的参数求最优了。
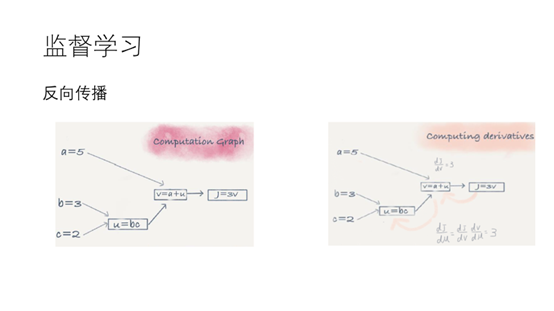
13.这里总结一下,神经网络的三要素:前向传播,代价函数,反向传播。这个模型比起一些传统的机器学习算法比如SVM等简单,但是效果却比较显著。现阶段基本统治了机器学习的所有研究领域。这里有一个小例子你们可以看一下。

14.从1958年到2016年底统计出来具有影响力的深度学习模型有27种。大部分深度学习的论文都是从这27种模型中延伸出来的。或是修修改改,或是做一些有趣的应用。
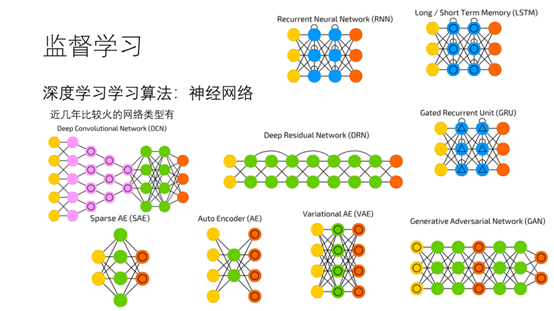
15.这几年比较火的模型分为三类。计算机视觉卷积神经网络,深度残差网络,序列模型有循环神经网络,长短时记忆网络。生成模型有GAN网络,变分自动编码器。由于降维的有自动编码器,稀疏自编码器。
16.这里先介绍一下卷积神经网络,因为这一波人工智能就是从卷积神经网络在12年的优秀表现带起来。

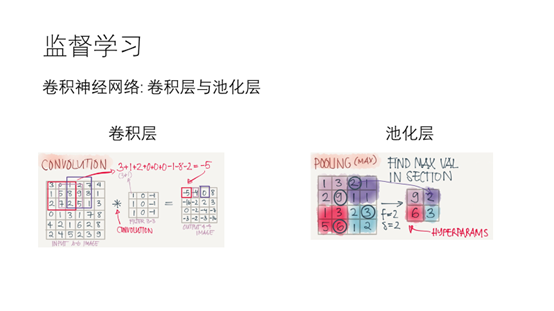
17.卷积神经网络在在原来的神经网络中增加了卷积层和池化层
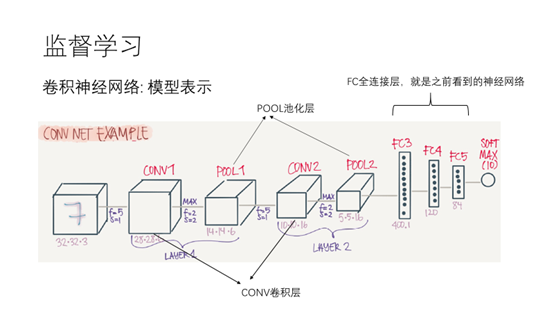
18.在卷积层中有一个过滤器,它与输入层相应位置的数据相乘,得到输出结果,这么做的目的是识别出特征。池化层,在输入层中取最大的数字作为该区域的表示。这么做的最主要的目的是降维。
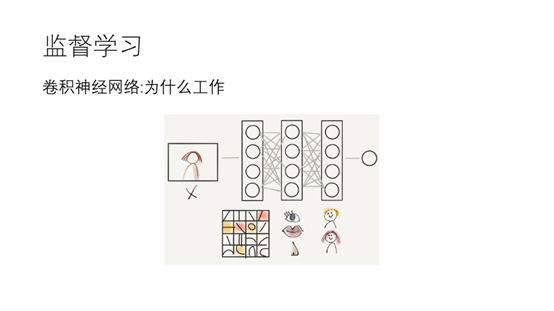
19.卷积神经网络为什么可以工作呢,以识别人脸为例子。在一些浅层会识别出一些比较简单的特征比如边。中间层会根据浅层构造出一些高级的特征,从而识别眼睛,嘴巴,鼻子等。高层根据中间层再构造出人脸的特征,最终识别出人脸。这里可以给大家看一个例子。
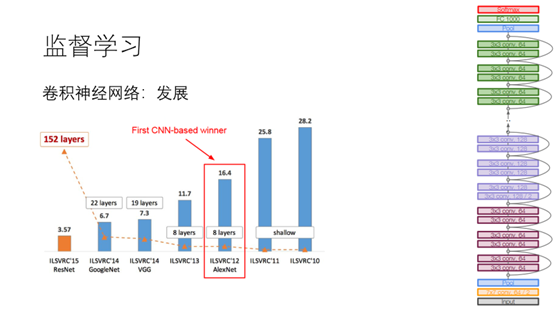
20.下图展示了神经网络这几年来得发展,可以看出来层数越来越多,准确率越来越大。在15年的时候,由于何凯明发表到的论文深度残差网络层数达到了152层,准确率达到了3.57已经超过了人类的识别能力了。
21,22. 除了刚才提到的图像识别,卷积神经网络应用比较广的地方有目标检测,神经风格迁移


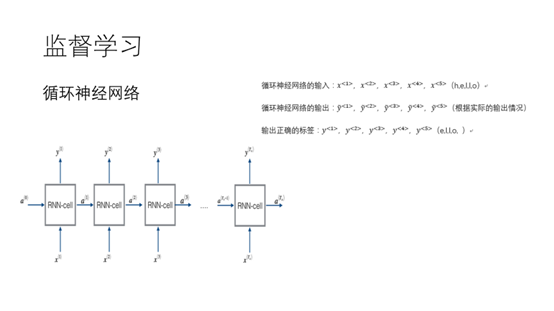
23.神经网络在监督学习应用比较广的另一种模型,是循环神经网络。循环神经网络主要应用在序列模型中。常见的序列数据有文字,语音。之前的语音以及文字都通过隐马尔可夫建模,现在通过循环神经网络效率大大的提升了。
24.循环神经网络的一个有趣的应用是文本序列的生成。上面是我在阿里云服务器中通过LSTM训练莎士比亚文集跑1h的输出结果,可以看出来它大概的学会了部分单次,以及分段。在阿里云中跑3小时的结果输出如下,可以看出来它已经学会了给段落打标签,比如这里的7。 网上还有人通过该模型训练Linux的源代码,生成的效果如右图所示,可以看出来长得还挺像Linux源代码的,而且还学会了注释。不过只是样子像,程序是跑不起来的。

前面介绍监督学习,后面简单的提一下神经网络在无监督学习以及增强学习中的应用。
25.深度学习在无监督学习应用中一个比较热的研究点是生成模型。14年Goodfellow提出了GAN网络,对抗生成网络。该网络主要由两部分主成,生成器和判别器。生成器主要是生成和训练数据相同分布的数据,判别器主要是识别数据是生成的还是真实数据。
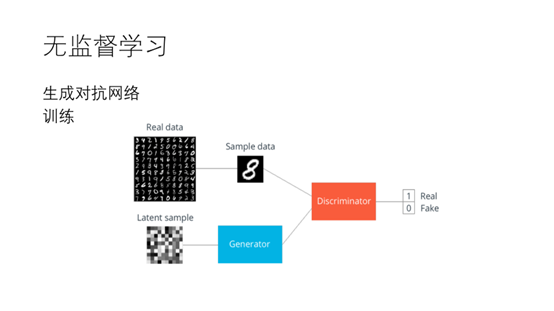
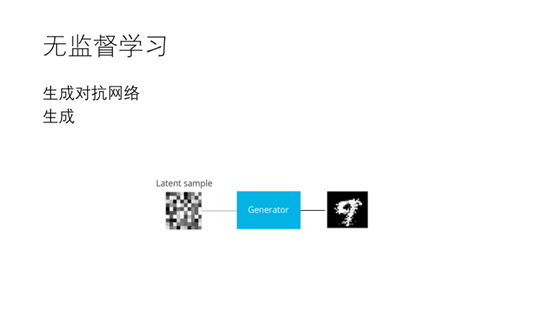
26. 通过不断的迭代训练最终生成器可以做到以假乱真。
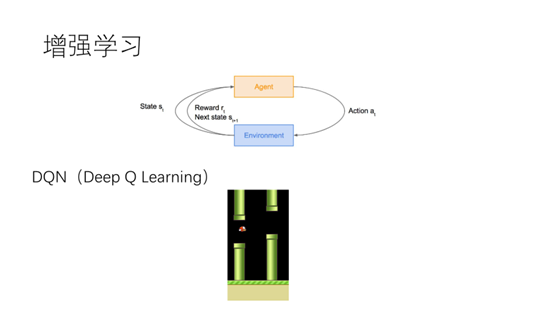
27.增强学习是最接近真正的AI,近几年在增强学习中也融入了深度学习,形成深度增强学习的研究点。这一块做的比较好的是DeepMind公司的AlphaGo。DeepMind的那篇关于DQN的论文发表在了Nature上面。DQN模型也大量的应用游戏中,下面我大家演示一下通过DQN玩愤怒的小鸟游戏。
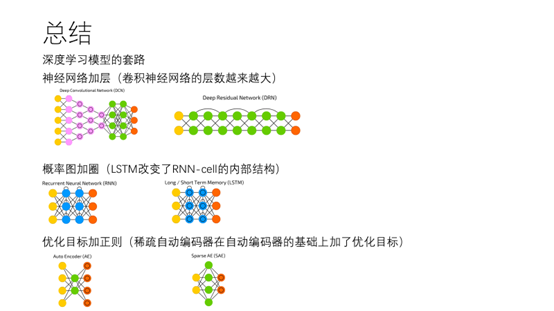
28.深度学习模型的套路:神经网络加层(如前面看到的卷积神经网络越来越深),
概率图加圈,优化目标加正则,这一块暂时还没有提高,后面有机会再做分享

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习小组介绍PPT – kexinxin - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 