这关我慢慢悠悠的做了两天才搞出来,思路太重要了;下面是我最终的代码,写的很烂很low,凑合看吧。这过程中走了不少弯路,思路有问题,给自己出了不少难题,最后发现是自己想复杂了。
用到的技术:
字符串、列表、集合、字典等基础操作
requests模块的get、post、session等用法
多线程、以及获取多线程返回值
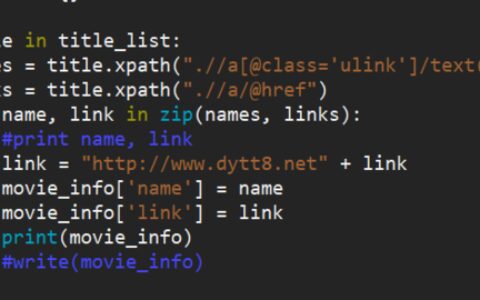
import re,requests,time from lxml import html etree=html.etree import threading class MyThread(threading.Thread): def __init__(self,func,args=()): super(MyThread,self).__init__() self.func = func self.args = args def run(self): self.result = self.func(*self.args) def get_result(self): try: return self.result # 如果子线程不使用join方法,此处可能会报没有self.result的错误 except Exception: return None def main(): # 访问第三关自动跳转到了这个url,所以首先需要登录 url_login = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex03/' # 登录成功后,访问第三关url url = 'http://www.heibanke.com/lesson/crawler_ex03/' # 因为需要通过带着cookie去访问,以便做到会话保持,所以这里用requests.session来做 session = requests.Session() # 获取cookie session.get(url_login) # 获取csrftoken token = session.cookies['csrftoken'] # 将用户名密码和csrftoken一起提交给登录页面 session.post(url_login, data={'csrfmiddlewaretoken': token, 'username': 'tianlegg', 'password': '123456'}) # 登录成功后,携带了token再来访问页面会看到第三关内容,和第二关一样,只不过每次提交时同样需要带着csrftoken,否则还是会报错 l=[] count=0 while True: thread_list = [] # 网站有限制,每个请求都会夯住15s,并且15秒内的并发最大为2,超出的话就会返回404,所以这里就起2个线程去请求 for i in range(2): t = MyThread(get_pos_values, args=(session,)) thread_list.append(t) t.start() for my_thread in thread_list: my_thread.join() # 一定要join,不然主线程比子线程跑的快,会拿不到结果 print('多线程运行结果:',my_thread.get_result()) # 把每次双线程运行返回的列表++ l = l + my_thread.get_result() print('本轮累加的pos+pwd列表,长度:',len(l),l) # k是所有pos k=l[::2] # v是所有value v=l[1::2] # 当去重后pos的长度为100时,说明1-100已经够了 if len(set(k))==100: # 把pos和value合并为字典,字典中不会出现重复的key,所以不需要再去重了。 dic=dict(zip(k, v)) session.get(url) new_token = session.cookies['csrftoken'] # 循环1-100,作为key,去获取字典中的value最后拼接起来 password=''.join([dic[str(i)] for i in range(1, 101)]) print('over!,密码是:',password) # 将csrftoken和用户名密码一同提交 page_text=session.post(url=url,data={'csrfmiddlewaretoken': new_token, 'username': 'tianlegg', 'password': password}).text # 通过xpath获取通关文本,下一关url并没有在页面里,自己在去访问ex04吧 tree=etree.HTML(page_text) print(tree.xpath('//h3/text()')[0]) break count=count+1 print(f'第{count}轮循环\n去重后的长度{len(sorted(set(k),key=int))} pos:{sorted(set(k),key=int)}') def get_pos_values(session): ''' 获取页面中的pos和pwd并返回list :param session: :return: ''' page_text=session.get(url='http://www.heibanke.com/lesson/crawler_ex03/pw_list/').text tree = etree.HTML(page_text) return tree.xpath('//table[@class="table table-striped"]//td/text()') if __name__ == '__main__': main()
开始运行时:
多线程运行结果: ['38', '8', '97', '6', '34', '7', '83', '5', '84', '7', '79', '1', '71', '2', '72', '5'] 多线程运行结果: ['69', '0', '22', '6', '15', '9', '73', '3', '76', '1', '9', '4', '53', '4', '67', '3'] 本轮累加的pos+pwd列表,长度: 32 ['38', '8', '97', '6', '34', '7', '83', '5', '84', '7', '79', '1', '71', '2', '72', '5', '69', '0', '22', '6', '15', '9', '73', '3', '76', '1', '9', '4', '53', '4', '67', '3'] 第1轮循环 去重后的长度16 pos:['9', '15', '22', '34', '38', '53', '67', '69', '71', '72', '73', '76', '79', '83', '84', '97']
结果:(跑了50次15秒才获取完1-100的pos,这个次数是随机的,这里通过多线程已经缩短了一半的时间)

密码是4894613647990394874326048437134877661813696344916326470648993670283105253381901613579433963964296911
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python 黑板课爬虫闯关-第四关 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫