任务目标
构建深度学习模型,对猫狗数据集进行分类(数据集来自kaggle),要求测试集的准确率不能低于\(75 \%\)。在本文中,使用了3个不同的模型进行分类,其测试集结果分别是:
- 自定义卷积神经网络:\(87.26\%\)。
- 使用resnet34做特征提取:\(93.6\%\)。
- 使用resnet34和VGG16做特征提取:\(94.88\%\)。
python:3.9.7
torch:1.11.0(使用resnet34和VGG16做特征提取使用的pytorch 版本是1.9.1)
代码Github:https://github.com/xiaohuiduan/deeplearning-study/tree/main/猫狗识别
数据集
数据集来自kaggle的猫狗数据集:Dogs vs. Cats | Kaggle。在数据集中,一共有2个压缩包,其中一个是训练集,另一个是测试集。但是针对于测试集,kaggle并没有相对应label标签。因此,在本次实验中,对kaggle训练集的数据进行划分,按照\(8:2\)的比例划分为训练集和验证集,最终使用验证集对模型性能进行测试。
在数据集中,以文件名对图片的类型进行划分,我们只需要提取文件名的前3个字符判断其为“dog”或者“cat”便可以对每张图片打上相对应的标签。


参考代码如下:
root_dir = "./train"
import os
from PIL import Image
imgs_name = os.listdir(root_dir)
imgs_path = []
labels_data = []
for name in imgs_name:
if name[:3] == "dog":
label = 0
if name[:3] == "cat":
label = 1
img_path = os.path.join(root_dir,name)
imgs_path.append(img_path)
labels_data.append(label)
数据集部分图片如下:

数据增强
为了提高模型的能力,可以使用pytorch自带的Transforms对图片进行处理变换。在训练时,可以对图片进行一定的剪裁,旋转,但是在验证的时候,并不需要进行这些操作。
# 对训练图片进行处理变换
my_transforms = transforms.Compose([
transforms.Resize(75),
transforms.RandomResizedCrop(64), #随机裁剪一个area然后再resize
transforms.RandomHorizontalFlip(), #随机水平翻转
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 对验证集的图片进行处理变换
valid_transforms = transforms.Compose([
transforms.Resize((64,64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
在以下3个模型中,模型接收的输入为(3,64,64)规格的图片。同时在数据增强阶段对图片进行标准化。标准化所使用的std和mean为ImageNet的值。
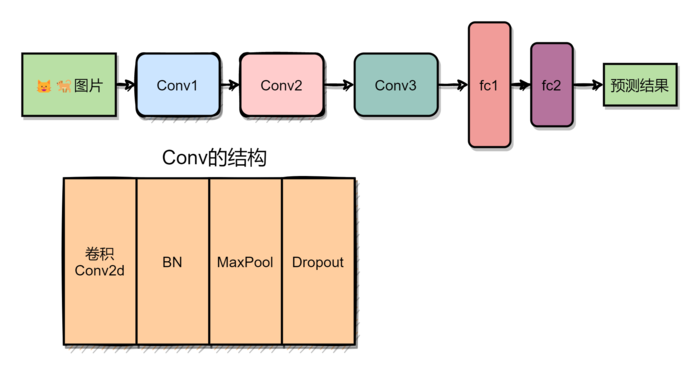
模型一:自定义网络
模型一是随便设计的卷积神经网络,Netron生成的模型图如下所示,网络一共由3个卷积层和2个全连接层构成。

模型对应的简化图,如下所示:
代码参考如下:
import torch.nn.functional as F
class MyNet(nn.Module):
def __init__(self):
super(MyNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,32,kernel_size=3),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.MaxPool2d(2,2),
nn.Dropout(0.25)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32,64,kernel_size=3),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2,2),
nn.Dropout(0.25)
)
self.conv3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2,2),
nn.Dropout(0.25)
)
self.fc = nn.Sequential(
nn.Linear(128*6*6,256),
nn.Dropout(0.2),
nn.Linear(256,2),
)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return F.log_softmax(x,dim=1)
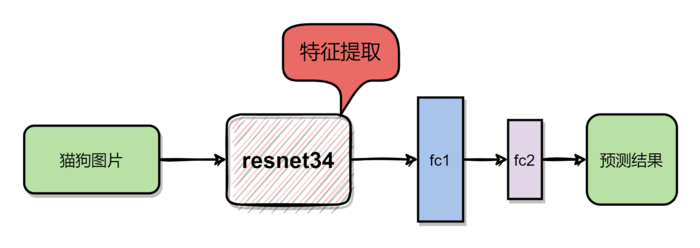
模型二:使用resnet34做特征提取
模型二的网络结构的简化图如下所示,resnet34使用的是torchvision中自带的模型,去除最后一层的全连接层,将前面的卷积层用于特征提取。然后将特征提取的结果进行Flatten,输入到全连接层,最终输出预测结果。
参考代码:
# 使用Resnet特征
resnet = models.resnet34(pretrained=True)
modules = list(resnet.children())[:-2] # delete the last fc layer.
res_feature = nn.Sequential(*modules).eval() # 训练时,不改变resnet参数
# 定义网络
class MyNet(nn.Module):
def __init__(self,resnet_feature):
super(MyNet,self).__init__()
self.resnet_feature=resnet_feature
self.fc = nn.Sequential(
nn.Linear(512*2*2,256),
nn.Dropout(0.25),
nn.Linear(256,2)
)
def forward(self,x):
x = self.resnet_feature(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return F.log_softmax(x,dim=1)
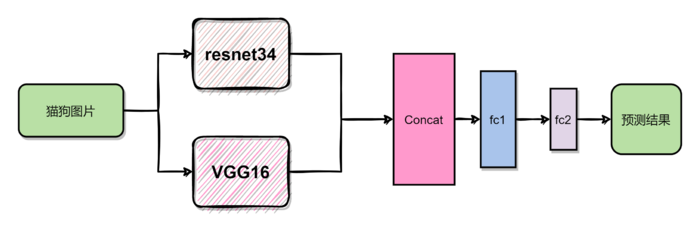
模型三:resnet34&vgg16做特征提取
模型三相比较于模型二,使用了两个网络进行特征提取,然后将输出的特征在channel维进行concat,再将concat后的结果输入到全连接层,最终得到预测结果。
参考代码:
# 使用VGG特征
model = models.vgg16(pretrained=True)
vgg_feature = model.features # 训练的时候忘记设置vgg模式为eval(),也就是说vgg的参数在训练的时候会发生改变
# 使用Resnet特征
resnet = models.resnet34(pretrained=True)
modules = list(resnet.children())[:-2] # delete the last fc layer.
res_feature = nn.Sequential(*modules).eval()
import torch.nn.functional as F
class MyNet(nn.Module):
def __init__(self,resnet_feature,vgg_feature):
super(MyNet,self).__init__()
self.resnet_feature=resnet_feature
self.vgg_feature = vgg_feature
self.fc = nn.Sequential(
nn.Linear(1024*2*2,256),
nn.Dropout(0.25),
nn.Linear(256,2)
)
def forward(self,x):
x1 = self.resnet_feature(x)
x2 = self.vgg_feature(x)
# 将特征融合在一起
x = torch.cat((x1,x2),1)
x = x.view(x.size(0),-1)
x = self.fc(x)
return F.log_softmax(x,dim=1)
trick
-
在训练时,可以动态的改变学习率,使用pytorch的lr_scheduler在训练的过程中动态修改学习率。
-
对图像进行数据增强。
-
找一台好电脑进行训练,别用小水管。
参考
- kaggle猫狗数据集:Dogs vs. Cats | Kaggle
- netron app:Netron
- pytorch optim:torch.optim — PyTorch 1.11.0 documentation
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习(二)之猫狗分类 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 