
CNN我们可以从两个角度来理解其中的具体过程
Neuron Version Story(解释版本1)
对于图像分类,其具体的流程如下所示:
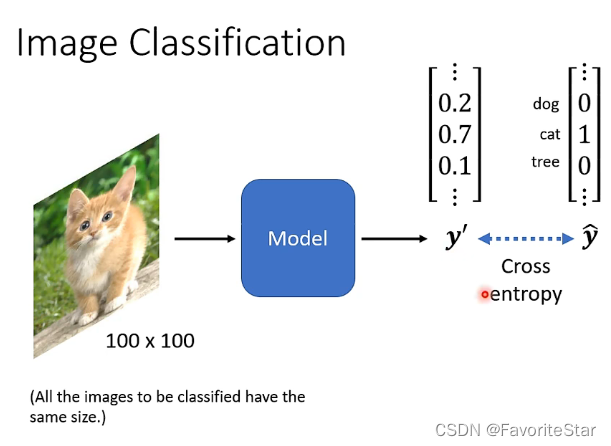

将一张图像作为模型的输入,输出经过softmax之后将与理想向量用交叉熵的形式进行比较。那么如何将图片作为模型的输入呢?
实际上每张图片都是三维的张量,两维表示长宽,一维表示通道(RGB),那么就可以将这个张量拉长成一个向量,就可以作为模型的输入了,该向量的每一个元素都是对应像素在对应通道上的取值。
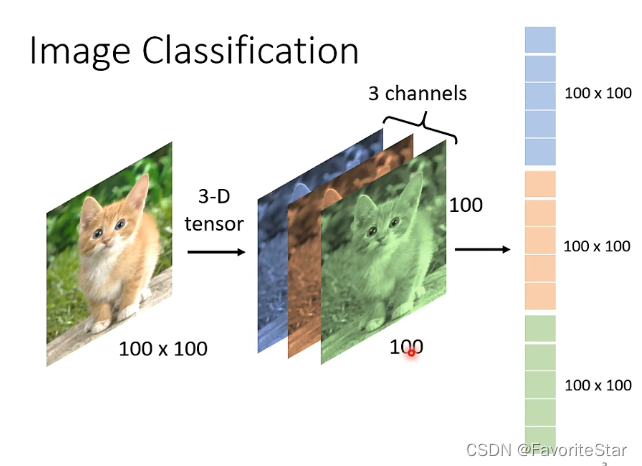
那么如果将上述的向量输入到一个全连接的网络中:
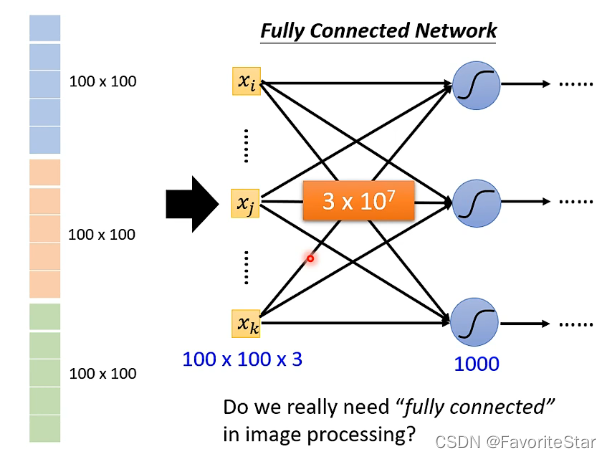
可以看到参数量非常的巨大!,因此我们应该尝试来进行简化!
观察现象1:
假设我们a当前在分辨一张图片是不是一只鸟的时候,我们并不用将整张图片完全都进行阅读与处理,实际上我们只需要找这张图片有没有出现关于鸟的关键性特征,例如鸟嘴、鸟的爪子等等,因此可以从这个思想进行简化
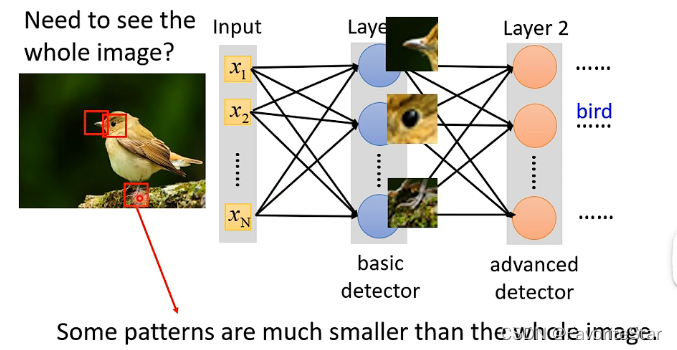
简化方法1:
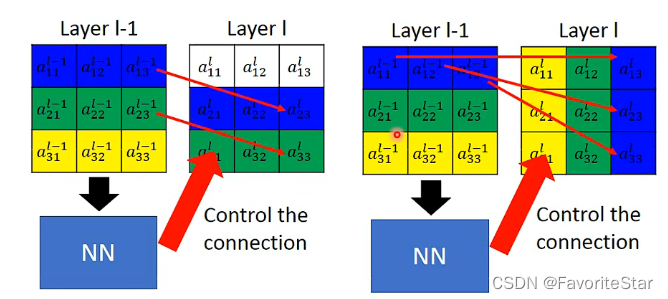
每一个神经元结点只看一部分区域的内容,例如:
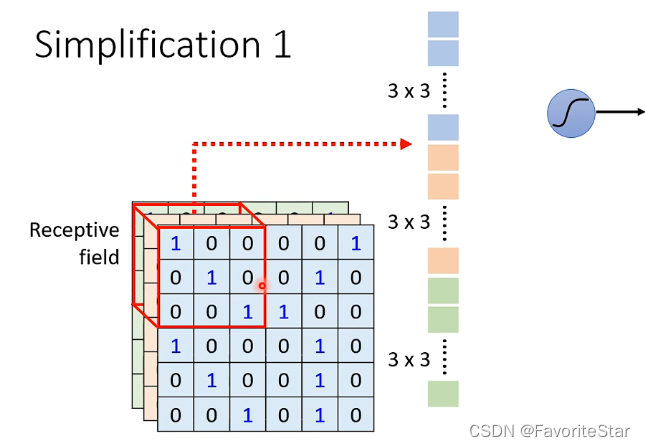
那个神经元只需要接受该(3times 3)区域的信息,因此只需要将该区域展开成向量作为该神经网络的输入即可。并且多个神经元结点他们的观测区域是可以重叠的、不同的观测区域可以不同的大小、不同的通道等等。
典型设置
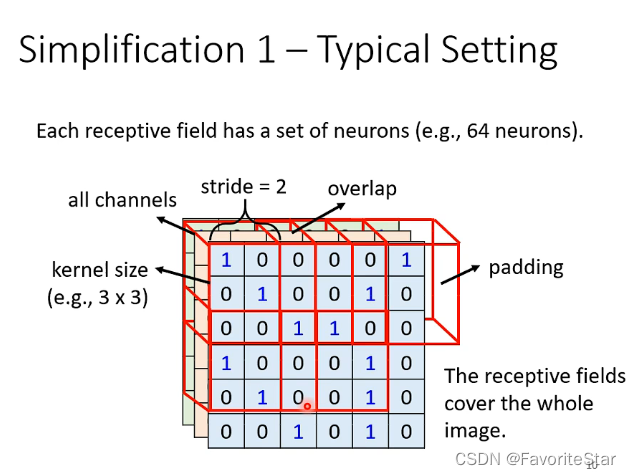
- 每一个观测区域都是观测全部通道,其大小称为kernel size,通常为((3times 3))
- 每一个观测区域通常不止有一个神经元结点在守卫,通常有多个,例如64、128
- 观测区域之间通常是有重叠的,例如上述stride就是距离,为2说明有1的交叠
- 如果在边界发现超出了范围,可以进行padding补值,那么可以补0或者均值等等
观察现象2:
同一个特征可能出现在图片中的不同位置,例如下面两张图片的鸟嘴是出现在图片的不同区域的:

那么是不是我需要在每一个区域都放一个可以侦测鸟嘴的神经元才可以呢?可是侦测鸟嘴这件事情是重复的,只不过是出现在不同的区域,那么可以进行简化。
简化方法2:
那么既然所做的事情是一样的只不过是区域不同,那么就让这不同区域的都是侦测鸟嘴的神经元共享参数:
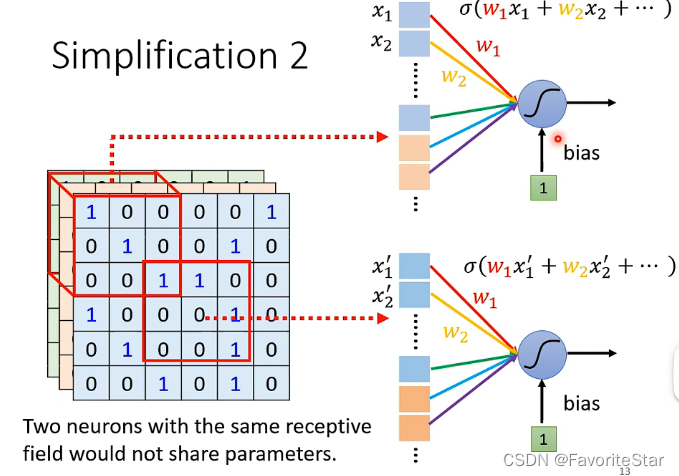
这样就可以完成在不同区域检测同一个特征,同时减少参数量的目的。
典型设置
结合我们前面所说的一个观测区域是由多个结点来守卫的,那么可以认为每个区域所拥有的神经元个数都相同,并且其中每一个神经元所侦测的特征也都相同,我们让其共享参数,也就全部区域都只有一组参数了
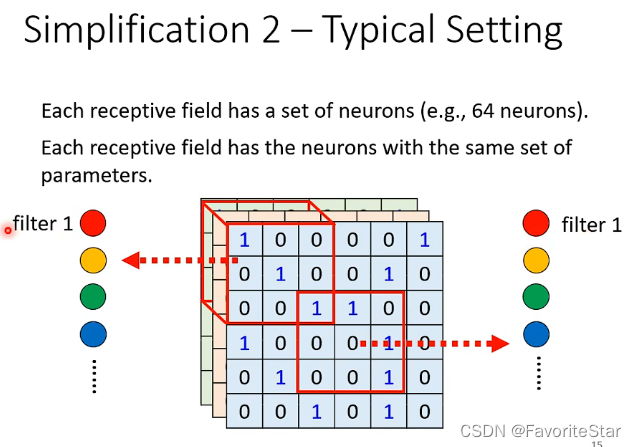
那么结合上面的各种方法,就把神经网络从全连接的范围减小到了卷积网络的范围,卷积神经网络的神经元满足上述的条件。因此可以看到因为范围小所以相对来说卷积神经网络的偏差是比较大的,但它是适用于特定的影像识别任务的。
Filter Version Story(解释版本2)
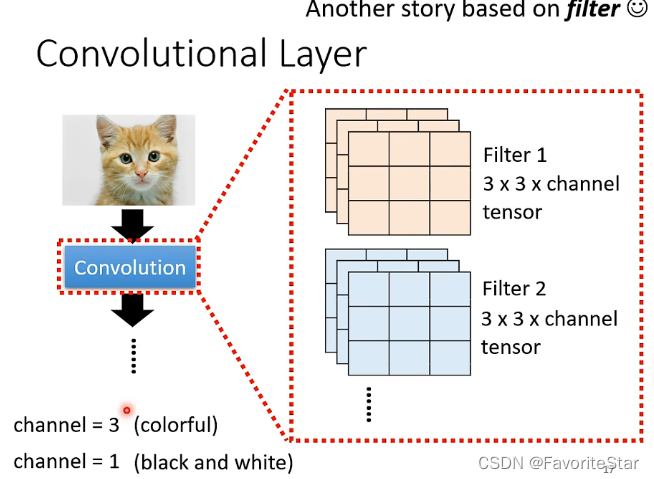
这个角度是说,对于一层卷积层,我们有很多个Filter,可以认为每一个Filter都是为了侦测某一个特征,其大小为设为((3times 3 times channel)),而其中的参数就是我们通过学习得到的。假设我们已知参数,现在来看其工作过程。
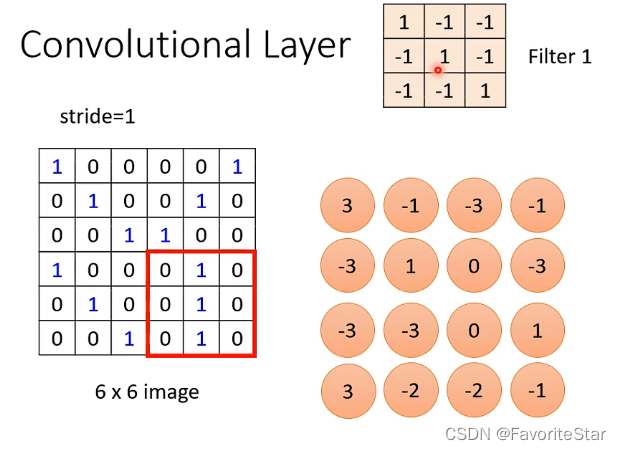
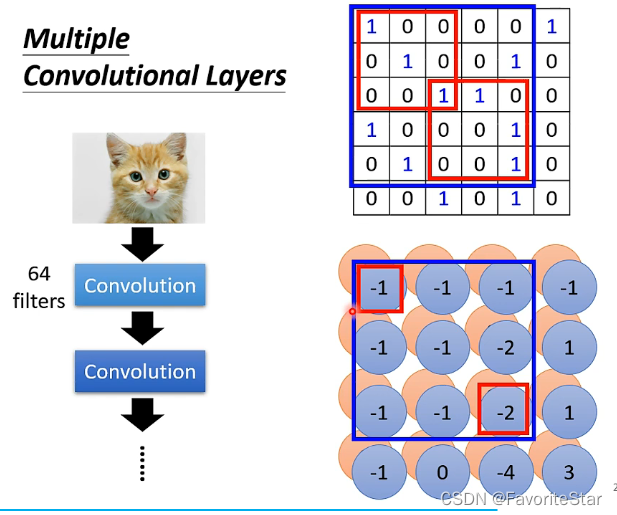
对于每一个Filter,会扫描整张图片的所有区域,然后将对应元素相乘再求和得到一个数组,扫描之后所得到的矩阵就是该层Filter对图像的处理结果:
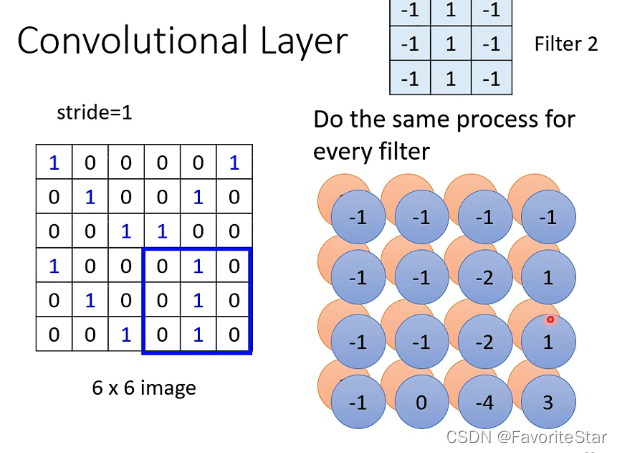
那么如果有多个Filter,就可以得到多个类似的数值矩阵
假设当前我们有64个Filter,那么得到的数值矩阵大小为((4times 4 times 64)),就可以将这个数值矩阵看成一个全新的图片,其长宽为(4times 4),其通道数为64,再将其输入到下一层的卷积之中,那么下一层的Filter的大小就需要为((3times 3 times 64))了:
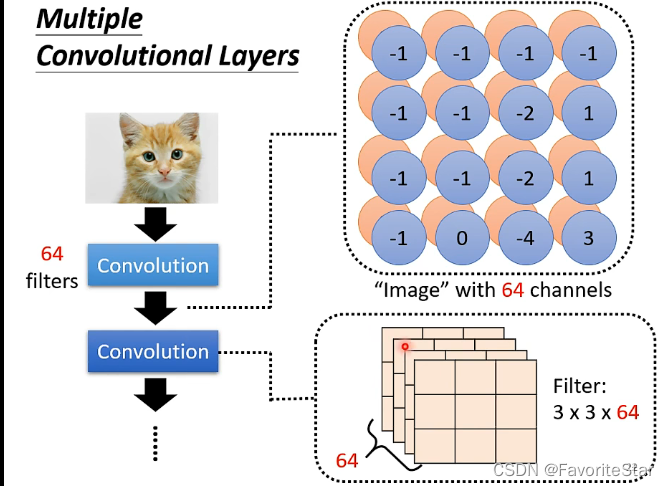
那么有一个问题是我们扫描的大小一直是(3times 3),有没有可能出现扫描的区域太小导致没看到某个特征的全部的现象?可以看下图
第二层仍然是(3times 3),但是其扫描的是第一层的输出结果,其扫描的区域相对于原始图像矩阵来说就是(5times 5),因此只要你层数足够,后面是可以一次性扫描整张图片的。
以上就是其工作流程。
这两种介绍方式的区别在于:
- 第一种说Filter是共同参数,而第二种则是一个Filter扫描过每一个区域
观察现象3:
如果对一张图,将其奇数行和奇数列拿掉,图片缩小为原来的四分之一,其特征是不会改变的,我们仍然可以很明显地看出是什么内容,这样缩小图片的大小称为pooling,可以有效地减小运算量。接下来介绍pooling具体怎么运行。
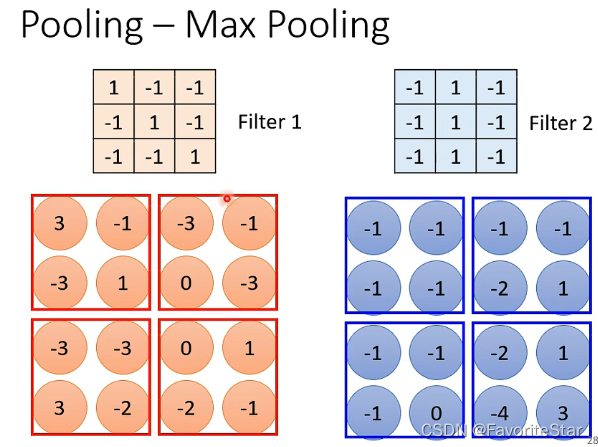
pooling——max pooling
对于前述从Filter得到的数值矩阵中,如果采用max pooling,那么就是将矩阵按照固定大小进行分组,然后每一组选出其中最大的数值来作为代表,这样就缩小了矩阵的大小,如下图:
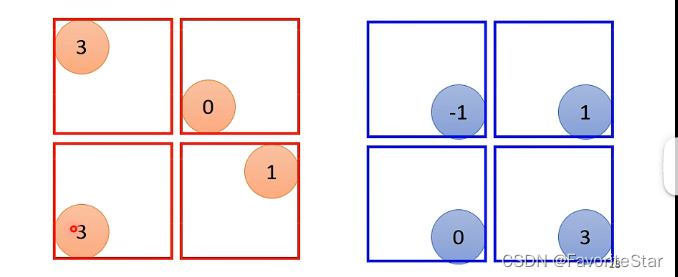
那么通常呢是在卷积之后就加上pooling,可以有效地减小计算量:
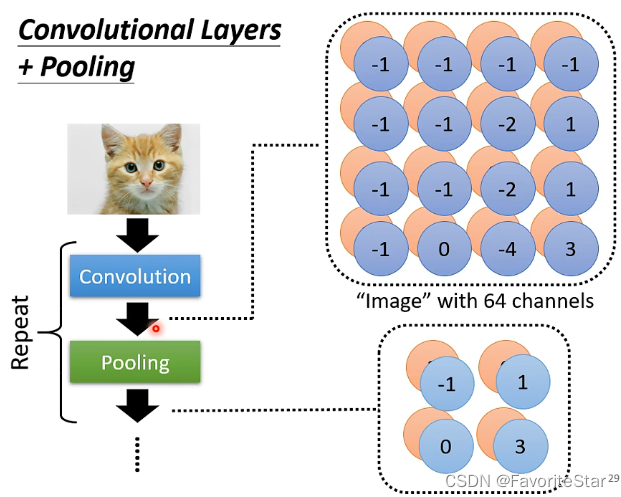
但这样也会损失一定的精度,因此可以几层卷积之后再进行一次pooling。
CNN的完整过程
经过前述的卷积+pooling,我们得到的是一个数值矩阵,那么如何从数值矩阵得到我们最终想要的判断类别的向量呢?请看下图:
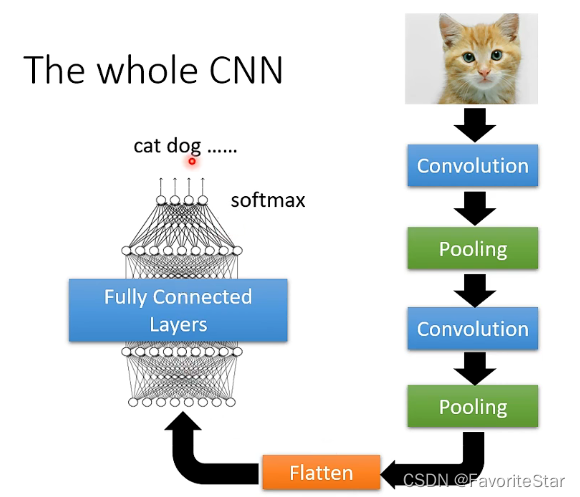
因此完整过程为:
- 将图像输入后经过反复的卷积和pooling后得到一个数值矩阵
- 将该数值矩阵Flatten,降成一个向量,作为一个全连接网络的输入
- 经过全连接网络的处理后的输出再经过一个softmax函数,得到最终的输出向量
Spatial Transformer Layer
由于CNN对于一些图像的特定操作不能够及时的反映出来,例如将训练时的物体进行放大、缩小、旋转等,CNN都很难能够及时地辨认出来,因此可在CNN之间加上一个特殊的转换层,这一层的目的在于能够将一些图片进行处理,处理成CNN能够辨识的样子,如下:
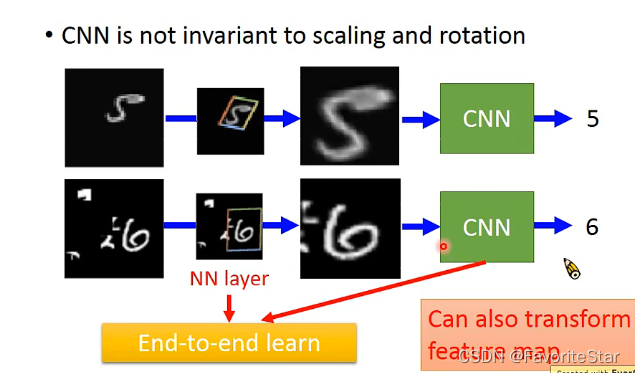
而将该层的参数和CNN的参数一起训练就称为End-to-end learn。
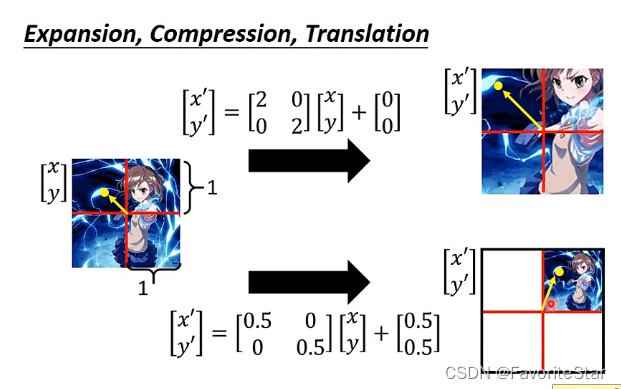
如何进行图像处理
具体的方式是将原始图像矩阵乘以一定的权重矩阵,得到目标图像矩阵,如下图:
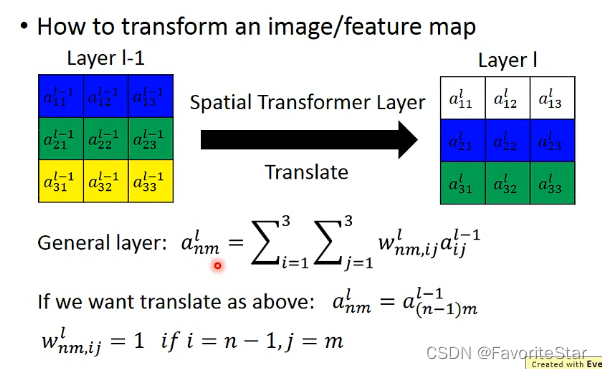
通过合理地设置(w^l_{nm,ij})就可以使得原来矩阵的值往下移动。而其他的旋转等操作也是类似的,实际上可以看成是经过一层神经元来带来的操作
常见转换
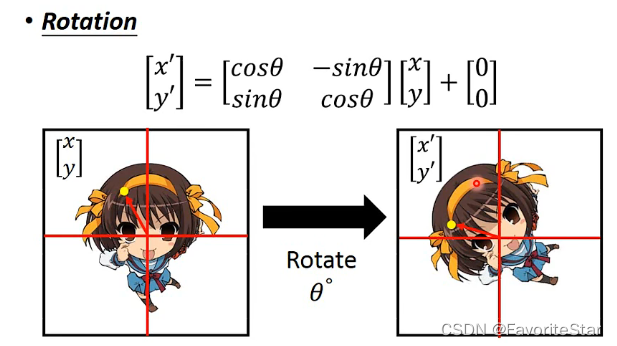
从上面可知,对于旋转、平移、缩放这些affine transformation,只需要六个参数来构成一个矩阵和一个向量,再将原始位置向量进行运算即可得出最终结果,因此可以认为将原始图像矩阵方法该层神经网络中将会输出六个参数构成矩阵和向量,然后再将原始矩阵和该参数进行计算即可得到目标图像:
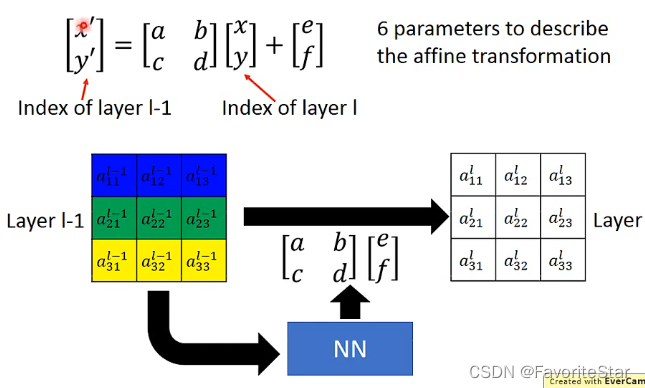
这里的([x,y])和([x`,y`])代表的是索引!!,例如

代入([x,y]=[2,2]),那么得到([x`,y`]=[1,1])也就是说
]
但如果是下面这种情况:
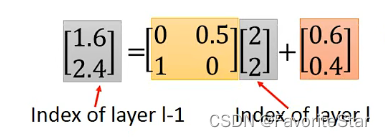
那么得到的索引不是整数,那么只能进行四舍五入。但这也就带来了问题
这样的转换是否可以进行梯度下降求解参数?
不可以!。梯度下降的含义是参数有微小的变化时输出会有什么变化,假设现在参数变化了而输出变成了1.61和2.41,但这经过四舍五入之后也就还是那个索引,没有变化无法带来梯度。
改进
舍弃四舍五入的做法!,采用如下的办法:
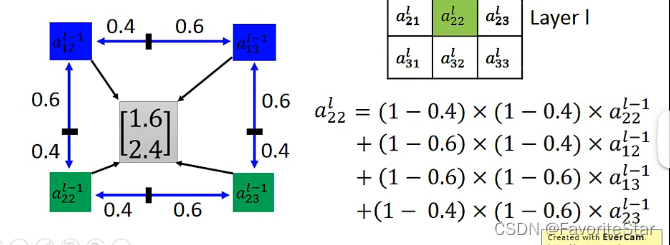
根据输出与周围坐标的差距来进行加权和,这样在输出有微小变化的时候最终结果也有微小变化,这样就可以进行梯度下降了。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【机器学习】李宏毅——卷积神经网络CNN - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 