简述:较为底层的爬虫实现,用于了解爬虫底层实现的具体流程,现在各种好用的爬虫库(如requests,httpx...等)都是基于此进行封装的。
PS:本文只作为实现请求的代码记录,基础部分不做过多阐述。
一、什么是socket
简称:套接字
大白话陈述一下:网络由类似无数终端(计算机设备)组成,每一台计算机设备上面都有很多的程序,而每个程序都有其端口号,ip+端口号形成唯一标识,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。PS:个人总结的,可能不是很准确看看就行
二、socket实现http请求
http请求方式:get和post
要使用socket首先要实现其实例化:scoket(family,type[,protocal])
其中第一个参数family表示地址族,常用的协议族有:AF_INET、AF_INET6、AF_LOCAL、AF_ROUTE等,默认值为AF_INET,通常使用这个即可。
第二个参数表示Socket类型,这里使用的值有三个:SOCK_STREAM、SOCK_DGRAM、SOCK_RAW。
SOCK_STREAM:TCP类型,保证数据顺序以及可靠性;
SOCK_DGRAM:UDP类型,不保证数据接收的顺序,非可靠连接;
SOCK_RAW:原始类型,允许对底层协议如IP、ICMP进行直接访问,基本不会用到。
默认值是第一个。
第三个参数是指定协议,这个是可选的,通常赋值为0,由系统选择。
GET /article-types/6/ HTTP/1.1
Host: www.zhangdongshengtech.com
Connection: close
第一行:请求方式+空格+请求的资源地址+空格+http协议版本
第二行:明确host
第三行:定义了Connection的值是close,如果不定义,默认是keep-alive。
PS:这里Connection设置为close是为了方便获取完响应后直接断开连接,如果是keep-alive再获取完响应数据后不会断开连接。
报文示例如下:目标url=http://www.baidu.com
GET / HTTP/1.1\r\nHost: www.baidu.com\r\nConnection: close\r\n\r\n
报文解析
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成
请求行:由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。例如,GET /index.html HTTP/1.1
请求头部:请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。例如,User-Agent:产生请求的浏览器类型
空行:最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
请求数据:请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
GET:示例
# -*- coding: utf-8 -*-
# @Time : 2023/1/8 15:12
# @Author : 红后
# @Email : not_enabled@163.com
# @blog : https://www.cnblogs.com/Red-Sun
# @File : socket_http_get.py
# @Software: PyCharm
import socket
url = 'www.baidu.com'
port = 80
# 创建TCP socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接指定服务端
sock.connect((url, port))
# 创建请求消息头发送的请求报文(详情见浏览器里面的请求头原文)
request_url = 'GET / HTTP/1.1\r\nHost: www.baidu.com\r\nConnection: close\r\n\r\n'
# 发送请求(send的参数为字节格式所以进行了编码)
sock.send(request_url.encode())
response = b''
# 接收返回的数据
rec = sock.recv(1024)
# 由于是TCP协议所以是分片传递,用while循环获取数据
while rec:
response += rec
rec = sock.recv(1024)
# 返回响应的文本是字节格式需要解码
print(response.decode())
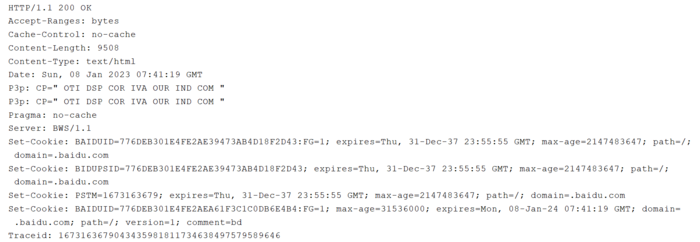

由上个演示可知响应中有Content-Length存在因此就可以知到响应数据的字节长度了。
所以上述示例代码可以修改为通过判断接受报文总字节长度达标后断开连接。
自动判断响应长度示例代码
# -*- coding: utf-8 -*-
# @Time : 2023/1/8 15:56
# @Author : 红后
# @Email : not_enabled@163.com
# @blog : https://www.cnblogs.com/Red-Sun
# @File : socket_http_get_upgrade.py
# @Software: PyCharm
import socket
url = 'www.baidu.com'
port = 80
# 创建TCP socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接指定服务端
sock.connect((url, port))
# 创建请求消息头发送的请求报文(详情见浏览器里面的请求头原文)
request_url = 'GET / HTTP/1.1\r\nHost: www.baidu.com\r\n\r\n'
# 发送请求(send的参数为字节格式所以进行了编码)
sock.send(request_url.encode())
# 接收返回的数据
rec = sock.recv(1024)
# 获取消息头与消息体分割的索引位置
index = rec.find(b'\r\n\r\n')
# 换行前为响应头报文
response_head = rec[:index]
# 索引位后移4为删除换行获取响应文本主体
response_body = rec[index+4:]
# 获取Content-Length,start_index:索引开始位,end_index:索引结束位
start_index = response_head.find(b'Content-Length')
end_index = response_head.find(b'\r\n', start_index)
content_length = int(response_head[start_index:end_index].split(b' ')[1])
# 由于是TCP协议所以是分片传递,用while循环获取数据
while len(response_body) < content_length:
rec = sock.recv(1024)
response_body += rec
# 关闭套接字
sock.close()
# 返回响应的文本是字节格式需要解码
print(response_body.decode())
POST:示例
# -*- coding: utf-8 -*-
# @Time : 2023/1/9 14:33
# @Author : 红后
# @Email : not_enabled@163.com
# @blog : https://www.cnblogs.com/Red-Sun
# @File : socket_http_post.py
# @Software: PyCharm
import socket
from urllib.parse import urlparse
url = 'http://www.baidu.com/'
# 作为一个懒癌患者加上了一个主域名解析,就不需要自己提取了,直接把目标网站扔里面结束。
host_url = urlparse(url).hostname
# http请求大部分都是80端口
port = 80
# 创建TCP socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接指定服务端
sock.connect((host_url, port))
request_header = b'''POST / HTTP/1.1
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: close
Content-Length: 传递参数的长度
Content-Type: application/x-www-form-urlencoded
Host: www.baidu.cn
Origin: http://www.baidu.cn
Pragma: no-cache
Referer: http://www.baidu.cn/
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36
X-Requested-With: XMLHttpRequest
'''
data = b'传递的参数(原型格式)'
# 发送请求(send的参数为字节格式所以进行了编码)
sock.send(request_header + b'\r\n' +data)
response = b''
# 接收返回的数据
rec = sock.recv(1024)
# 由于是TCP协议所以是分片传递,用while循环获取数据
while rec:
response += rec
rec = sock.recv(1024)
# 返回响应的文本是字节格式需要解码
print(response.decode())
PS:避免实例网站被搞,这里就用百度代替,此代码只是模板链接无法直接运行。
url:目标网站地址
request_header:发起的请求头(懒人做法直接去浏览器抓包后复制请求头的值就行,直接粘贴就能用),这个模板要改几个值,Connection需要是close,浏览器默认keep-alive,如果Accept-Encoding属性中有gzip最好移除,不然打印容易报错。
三、socket实现https请求
http跟https的一些区别:
端口:http默认80,https默认443
传递:HTTP协议是位于第四层协议TCP之上完成的应用层协议, 端到端都是明文传送,别人一下就能获取到数据,不太安全。HTTPS是基于SSL加密传输的,这样别人截获你的数据包破解的概率要小一点,比HTTP安全一些。
PS:个人看法,http跟https相比就差了一个ssl加密所以用ssl.wrap_socket (sock[, **opts])包装现有套接字实现https请求。
https的GET实例
# -*- coding: utf-8 -*-
# @Time : 2023/1/9 15:34
# @Author : 红后
# @Email : not_enabled@163.com
# @blog : https://www.cnblogs.com/Red-Sun
# @File : socket_https_get.py
# @Software: PyCharm
import socket
import ssl
url = 'www.baidu.com'
port = 443
# 勇1ssl.wrap_socket封装socket
sock = ssl.wrap_socket(socket.socket(socket.AF_INET, socket.SOCK_STREAM))
# 连接指定服务端
sock.connect((url, port))
# 创建请求消息头发送的请求报文(详情见浏览器里面的请求头原文)
request_url = b'GET https://www.baidu.com/ HTTP/1.1\r\nHost: www.baidu.com\r\nConnection: close\r\n\r\n'
# 发送请求(send的参数为字节格式所以进行了编码)
sock.send(request_url)
response = b''
# 接收返回的数据
rec = sock.recv(1024)
# 由于是TCP协议所以是分片传递,用while循环获取数据
while rec:
response += rec
rec = sock.recv(1024)
# 返回响应的文本是字节格式需要解码
print(response.decode())
https的POST实现:就是对上面http的post实现就行ssl封装这里就不在做过多阐述了。
懒人直接用脚本
个人封装的脚本,主要作为学习熟练编写还有很多能封装改进的地方,暂时简化如此了,要用的话看一下注意事项
注意事项:
- url要带http或https
- post传参的data数据前面记得加个r避免\斜杠的转义效果导致报错
- 复制的request_header粘贴之后要看看有没有多余的空行有时候粘贴会自动回车
- 访问失败可以尝试删减request_header中的参数,有时候无用参数会导致这类问题
PS:暂时就想到这么多等以后遇见问题在补充吧,毕竟也只是学习笔记,慢慢学吧。
# -*- coding: utf-8 -*-
# @Time : 2023/1/9 15:37
# @Author : 红后
# @Email : not_enabled@163.com
# @blog : https://www.cnblogs.com/Red-Sun
# @File : SocketSpider.py
# @Software: PyCharm
import socket
import ssl
from urllib.parse import urlparse
class SocketSpider:
'''
socket爬虫脚本(PS:模仿requests写的仅作为学习所用)
'''
def format_socket(self, url):
'''
格式化创建socket
'''
host_url = urlparse(url).hostname
port = (80, 443)['https' == url[:5]]
if port == 80:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
else:
sock = ssl.wrap_socket(socket.socket(socket.AF_INET, socket.SOCK_STREAM))
sock.connect((host_url, port))
return sock
def format_header(self, request_header):
'''
对请求头中的数据进行处理
'''
message = b''
for header_data in request_header.split(b'\n'):
if b'gzip' in header_data:
continue
message += header_data + b'\r\n'
# message += b'\r\n'
return message.replace(b'Connection: keep-alive', b'Connection: close')
def get(self, url: str, request_header: str):
'''
get请求实现
url: 必须要带http或https
request_header: 直接从浏览器抓包复制出请求头就行
'''
sock = self.format_socket(url=url)
message = self.format_header(request_header.encode())
sock.send(message)
response = b''
# 接收返回的数据
rec = sock.recv(1024)
# 由于是TCP协议所以是分片传递,用while循环获取数据
while rec:
response += rec
rec = sock.recv(1024)
# 返回响应的文本是字节格式需要解码
return response.decode()
def post(self, url:str, request_header: str, data: str):
'''
post请求实现
url: 必须要带http或https
request_header: 直接从浏览器抓包复制出请求头就行
data: 同样直接从浏览器复制出来就行(前面最好加上r避免\斜杠的转义效果)
'''
sock = self.format_socket(url=url)
message = self.format_header(request_header.encode()) + data.encode()
sock.send(message)
response = b''
# 接收返回的数据
rec = sock.recv(1024)
# 由于是TCP协议所以是分片传递,用while循环获取数据
while rec:
response += rec
rec = sock.recv(1024)
# 返回响应的文本是字节格式需要解码
return response.decode()
if __name__ == '__main__':
url = 'https://www.baidu.com/'
request_header = '''GET / HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: keep-alive
Cookie: PSTM=1664529301; BIDUPSID=5D9256DF2D0A67E0B97C22A9AC33CB09; BAIDUID=B54EAE77A79A6008061229C7A4AB5387:FG=1; MCITY=-224%3A; BD_UPN=12314753; BAIDUID_BFESS=B54EAE77A79A6008061229C7A4AB5387:FG=1; __bid_n=1845a26a63492b76484207; FEID=v10-1cec01417c6a9c7b08b333c03eb5425b40157d14; __xaf_fpstarttimer__=1672974585279; __xaf_thstime__=1672974585296; FPTOKEN=1oofVJhUqwLSMyqmyHnXJSxhD+K991pfK+BFWKI9hSqaoAEyXVZYBO320OdxlRccUo1KnxIfZK0C7Fpcc5ED9MHoxVt7PAEblzQAudnC7Di7Ic5it9yUwuAcV2iTjxygfDUcIQI5H0vbTllVkUpaX+xEyctdNFuFm0Py4wQ6EFX7bAjD0I5muVjmnRdsC/6qHg8fINmN3dEID5+n6zpiNVs+bLYePtIeO9SI/HvE7mnQxcd/HbOwf0to5q/5tcNyzO8riRarry1ryI7wocSoAnYc6HTyEaVY2xSdDYeXPNLCbMOwZvfAejftHAfvTCNRWO/K3GV0PYU/+yhEXkejECxAMOnFsbfPyhHd13AyEY0IwyNNYthFeO5qSazdfMZIVFEqenGxifjUCLsejVbcHg==|4j1jFPC8s2KJ3Bd5vfyJK+BhAEWpSgq+RbmgPQ512ro=|10|b66cd1b11d1528a08711913e6ce61baf; __xaf_fptokentimer__=1672974585330; BA_HECTOR=24ag80a4ah2la5ak05242lqk1hrnc8s1k; ZFY=gDQKa:Bq4ufkSfg5tno3jSIyvxsB0KQkWtgWw1CAvnO4:C; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; COOKIE_SESSION=4_0_9_9_20_16_1_1_9_8_1_2_1125999_0_3_0_1673244971_0_1673244968%7C9%231882534_14_1670467865%7C4; BDRCVFR[t1epCe_UAtt]=OjjlczwSj8nXy4Grjf8mvqV; BD_HOME=1; delPer=0; BD_CK_SAM=1; PSINO=5; ab_sr=1.0.1_MjQ0YjU1ODM4ODAzOTE5ODQxM2U5ZTRhYjFlMDIwMzkwZGIzYjc0MjVmZmExMTZmMTA1ZmEzMmUzNGMyMGQ3ZThmNzliNmJhZGFjMDM3NDE4YzQ4NGMxMWI0YzIxY2VkMWFhNTcyMTQ1NWVlNDMyY2VkZmY5MTMwZjJmNDVhOTkwNzY1YTQwOTI4M2I2Yzg1ZTYwODBmYzhiZTgzMzA1MA==; BDRCVFR[sOxo1TgcNNt]=OjjlczwSj8nXy4Grjf8mvqV; BDRCVFR[bIKc3BPCk_C]=OjjlczwSj8nXy4Grjf8mvqV; H_PS_645EC=4e43o0N5BrE9ePh0PWMUS4TfxCmDRlE97BtwBPR4eHZmdOKlWsRxZaGgaEJYE2x9oTHCsGqhpL13; H_PS_PSSID=36555_37647_37625_36920_38035_37989_37931_26350_38009_37881
Host: www.baidu.com
Pragma: no-cache
Referer: https://cn.bing.com/
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: cross-site
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36
sec-ch-ua: "Not?A_Brand";v="8", "Chromium";v="108", "Google Chrome";v="108"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
'''
a = SocketSpider()
a.get(url=url, request_header=request_header)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Socket爬虫:Python版 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 