我们使用 Scikit-learn 库实现一个简单的深度学习训练示例,训练目标为:识别手写数字。
以下是实现手写数字识别的完整示例代码:
from sklearn import datasets
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载手写数字数据集
digits = datasets.load_digits()
# 获取特征值和目标值
X = digits.data
y = digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练SVM分类器
clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(X_train, y_train)
# 预测测试集数据
y_pred = clf.predict(X_test)
# 计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
print("分类准确率:", accuracy)
# 随机显示10个测试集数据和其预测结果
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(10, 4))
for i, ax in enumerate(axes.flat):
ax.imshow(X_test[i].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title("like:{}".format(y_pred[i]))
ax.set_xticks([])
ax.set_yticks([])
plt.show()以上对手写数字进行分类的整个代码逻辑如下:
- 第一步,我们加载了手写数字数据集,其中包含8x8像素的数字图像,共计 1797 个样本。
- 然后,我们将数据集划分为训练集和测试集,训练集用来让SVM分类器进行训练;测试集是对训练的结果进行预测。然后计算出分类的准确率,并输出。
- 最后,我们会随机选取10个测试集数据,显示其图像和预测结果。
输出的预测结果:
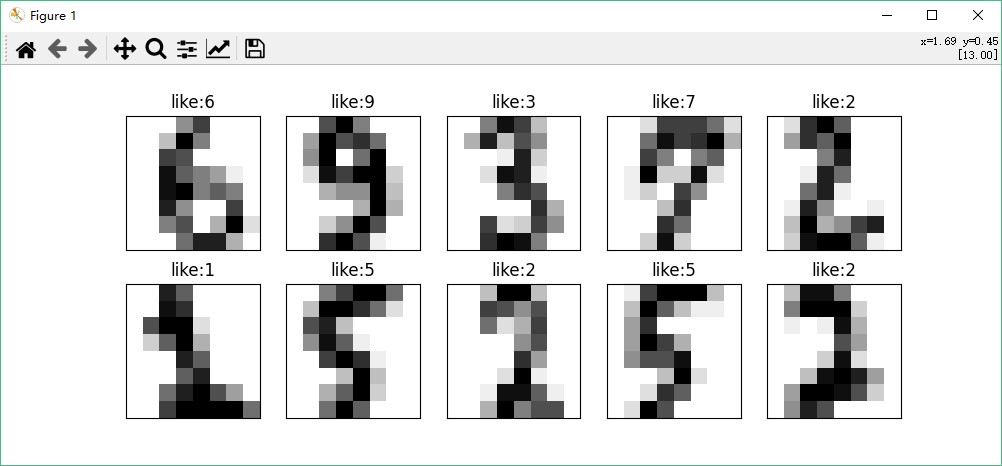
需要注意的是,手写数字识别是一个比较复杂的问题,需要对图像进行预处理、特征提取等一系列操作。上述示例中没有进行这些操作,仅仅是对原始像素数据进行分类。在实际应用中,需要根据具体情况进行调整和优化。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:(实战篇)用Python识别手写数字 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
