
Django_响应对象
响应对象
响应对象有三种形式:
HttpResponse()
render()
Redirect()
(1) HttpResponse()
django服务器接收到客户端发来的请求之后,会将提交上来的数据封装成一个HttpResponse对象传给视图函数。视图函数在处理完相关逻辑之后,也需要一个返回响应给浏览器。而这个响应方式,我们必须通过返回HttpResponseBase或者其他子类的对象。
常用属性:
content:返回内容
status:响应状态码
content_type:返回的数据的MIME类型,默认为 text/html 。浏览器会根据这个属性,来显示数据。如果是 text/html ,那么就会解析这个字符串,如果 text/plain ,那么就会显示一个纯文本
设置响应头: response['X-Access-Token'] = 'xxxx' 。
class HttpResponseBase:
"""
An HTTP response base class with dictionary-accessed headers.
This class doesn't handle content. It should not be used directly.
Use the HttpResponse and StreamingHttpResponse subclasses instead.
"""
status_code = 200
def __init__(self, content_type=None, status=None, reason=None, charset=None, headers=None):
self.headers = ResponseHeaders(headers or {})
打开HttpResponseBase类的源码可以看到构造属性中有上述的这些参数,默认status为200
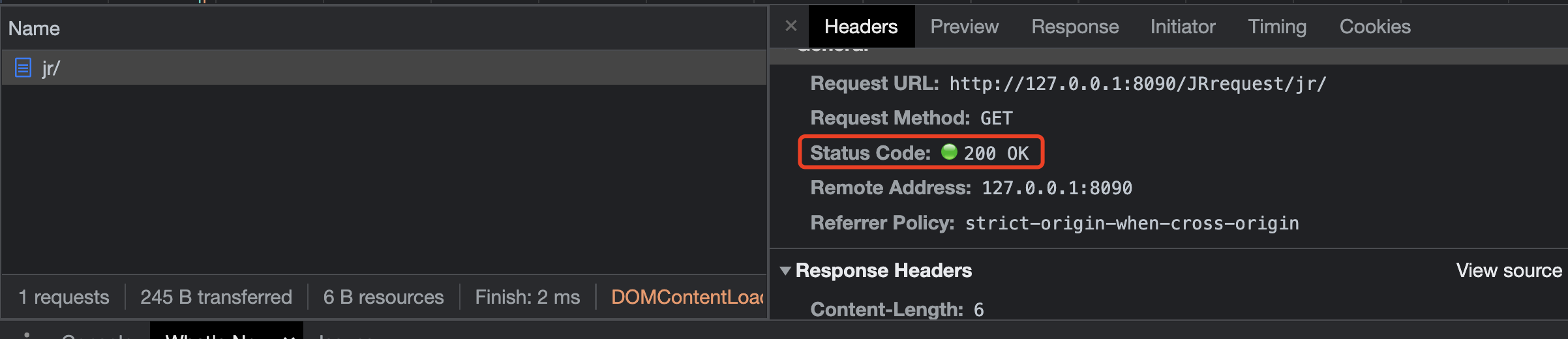

但是我们也可以自己设置不同的状态码
同时我们也可以自己设置传输类型
默认的种类是text/html类型的文本,所以再加入某些标签的时候会被认作是html文本
return HttpResponse("<h1>JiaRui<h1>",status=403)

显示出来的并不是<h1>JiaRui</h1>,而是一个一级标题,如果想要得到完整的这个文本内容,需要加一个参数配置content_type="text/plain"

同时也可以设置响应头部分,浏览器在自动接收的时候就会默认设置好一些参数

如果想自定义一些响应头就需要修改一下python代码
res = HttpResponse("<h1>JiaRui</h1>",content_type="text/plain")
res["regina"] = "my_wife"
return res

(2)JsonResponse()
用来对象 dump 成 json 字符串,然后返回将 json 字符串封装成 Response 对象返回给浏览器。并且他的 Content-Type 是 application/json
from django.http import JsonResponse
dir = {
'name':"regina",
'age': 20
}
import json
return HttpResponse(json.dumps(dir,ensure_ascii=False))
因为不接受字典,所以先要用dumo方法变成字符串,括号里的参数可以使字符串里写成中文
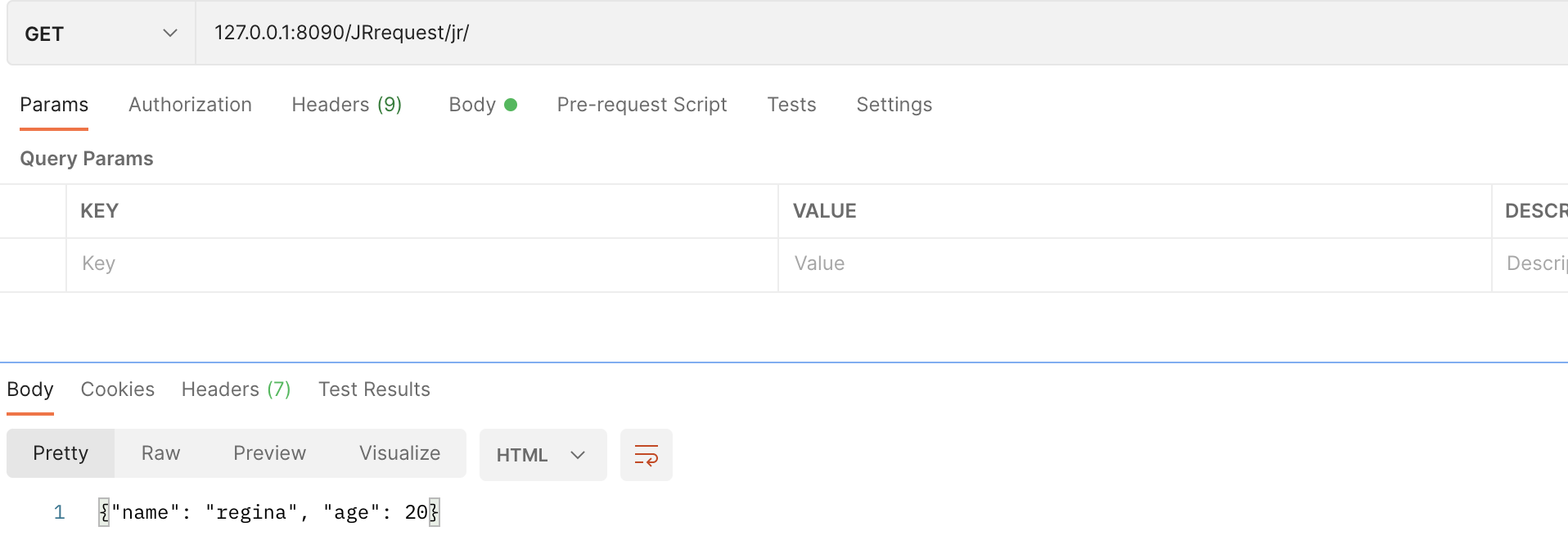
返回的确实是一个类似于字典类型的格式,但是如果我们想进一步变的更加条理,就需要把文本类型再改一下
return HttpResponse(json.dumps(dir,ensure_ascii=False),content_type="application.json")
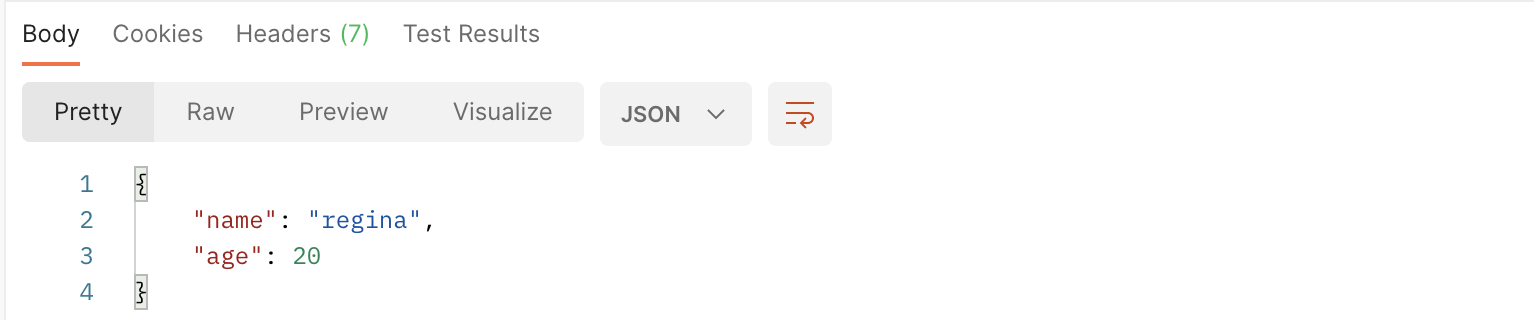
为了方便,上述的操作过程可以用JsonResponse格式统一替换掉
class JsonResponse(HttpResponse):
"""
An HTTP response class that consumes data to be serialized to JSON.
:param data: Data to be dumped into json. By default only ``dict`` objects
are allowed to be passed due to a security flaw before EcmaScript 5. See
the ``safe`` parameter for more information.
:param encoder: Should be a json encoder class. Defaults to
``django.core.serializers.json.DjangoJSONEncoder``.
:param safe: Controls if only ``dict`` objects may be serialized. Defaults
to ``True``.
:param json_dumps_params: A dictionary of kwargs passed to json.dumps().
"""
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
data = json.dumps(data, cls=encoder, **json_dumps_params)
super().__init__(content=data, **kwargs)
dir = {
'name':"regina",
'age': 20
}
return JsonResponse(dir)
得到的也是同样的效果,但是如果我们想传输一个字典列表的话,这种方法就不适用了
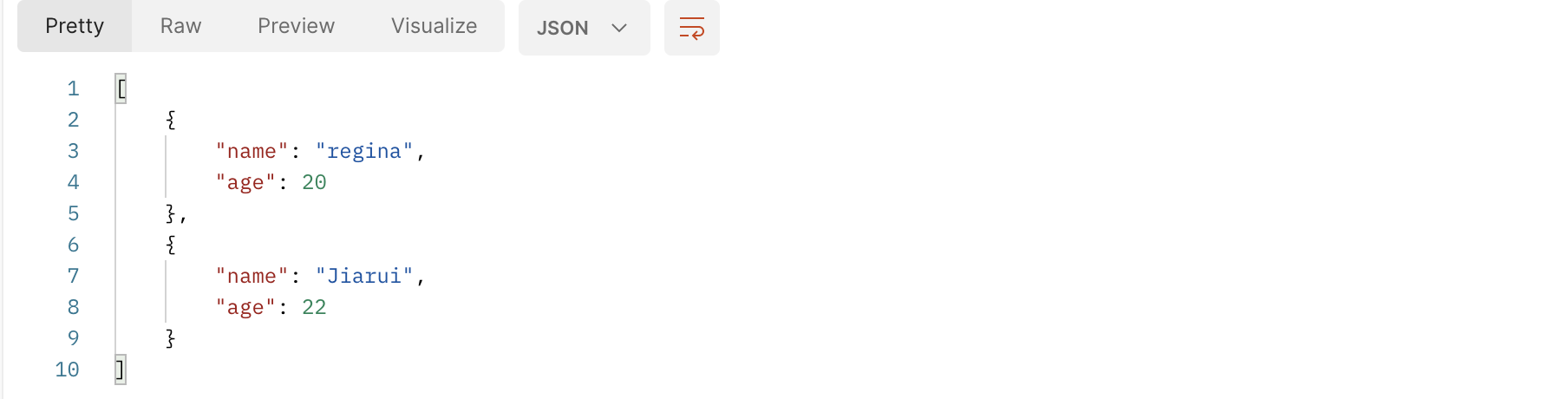
return JsonResponse([ {'name':"regina",'age': 20},{'name':"Jiarui",'age': 22}])

如果想要得到这种形式的内容,就需要在把默认的safe参数改为false就可以了
(3)render
render(request, template_name,[context])结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数
request:用于生成响应的请求对象
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典,
默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
结合运用请求信息里面的知识点,首先在请求头里添加一个自定义的名字

name = request.META.get("HTTP_NAME")
return render(request,"regina.html",{'now':name})

可以看到请求部分name改为了HTTP_NAME这个名字,然后获取它,渲染到我们的模板文件里就好

(4)redirect重定向
当您使用Django框架构建Python Web应用程序时,您在某些时候必须将用户从一个URL重定向到另一个URL,
通过redirect方法实现重定向。
参数可以是:
- 一个绝对的或相对的URL, 将原封不动的作为重定向的位置.
- 一个url的别名: 可以使用reverse来反向解析url
首先我们创建一个登录验证的逻辑,通过路由分发转到一个登录页面
def login(request):
return render(request,"login.html")
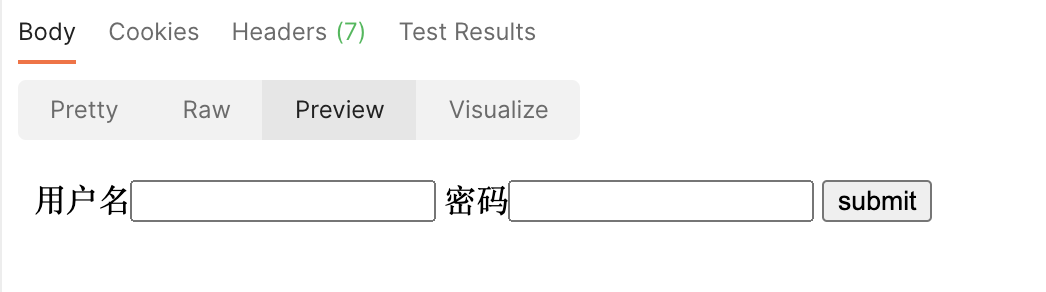
然后通过这个提交转到一个叫做auth的视图函数进行验证,通过post方式进行提交
<form action="http://127.0.0.1:8090/JRrequest/auth" method="post">
用户名<input type="text" name="user">
密码<input type="password" name="pwd">
<input type="submit" value="submit">
</form>

可以看到用户名和密码都打印出来了,这时就可以进行判断以及重定向
def auth(request):
print(request.POST)
name = request.POST.get("user")
pwd = request.POST.get("pwd")
if name == "zhangjiarui" and pwd == "regina":
return redirect("/JRrequest/jr")
else:
return redirect("/ZJR/login")
auth函数重定向的时候是没有响应内容的,但是有响应头
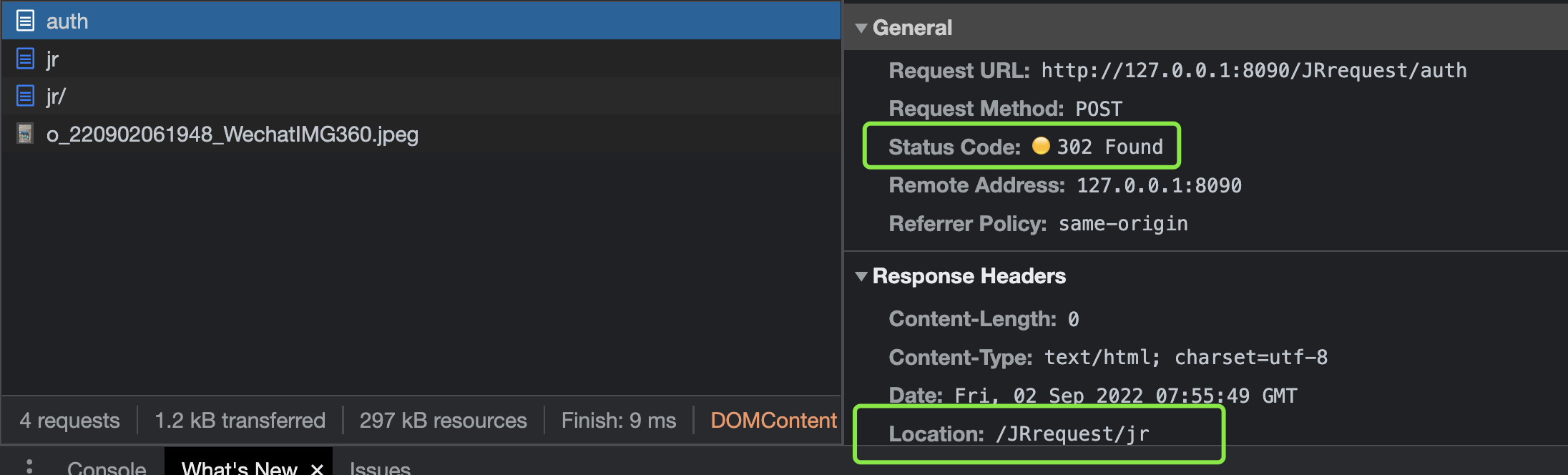
当状态码是302时,就说明要发起一个重定向了,并且此时的location代表重定向的路径。

如果输入错误,想要获取的效果是提示并返回登录页面,添加一个渲染即可

注意
在我们写路由的时候,往往会有/的区别
path("login",views.login)
在这里是没有斜杠的,那么在浏览器访问的时候,多一个/一定会报错
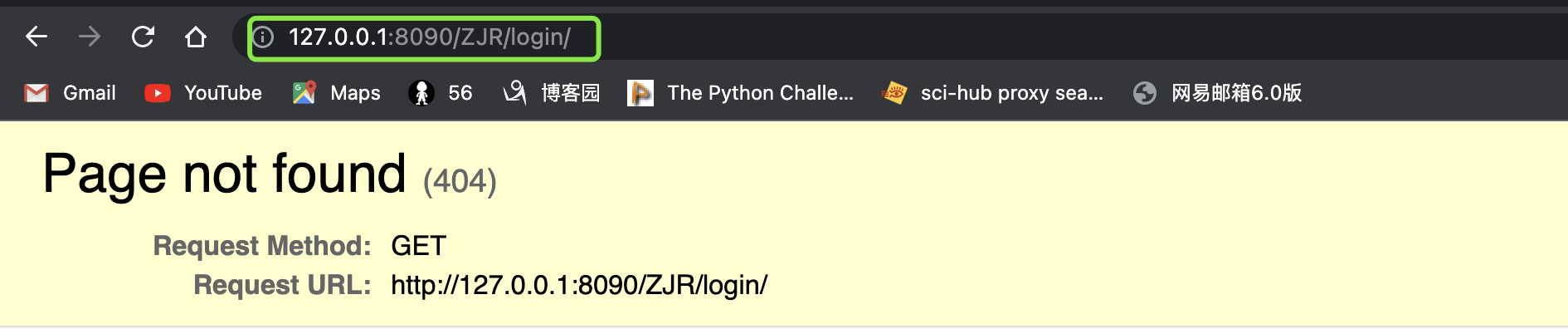
但假如说我们的路由里是带/的,那么无论我们访问浏览器是怎么写的,都不会有问题
path("login/",views.login)
具体区别就是
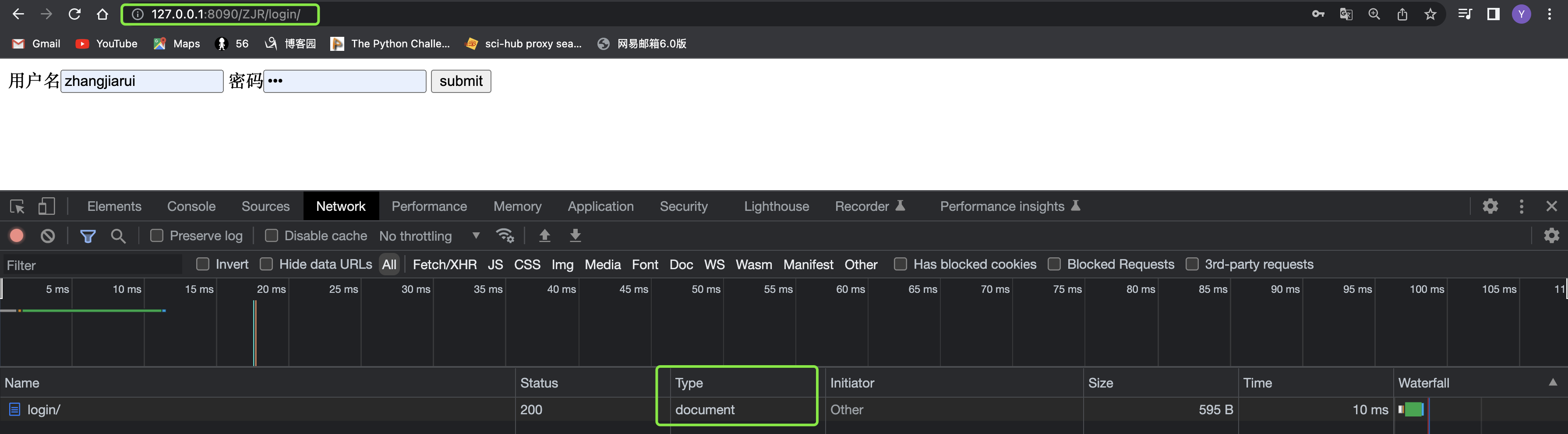
如果本身就是带着/访问,那么就是一次访问,状态码是200,但如果访问的时候没有带/,那么将会有两次响应,服务器会帮客户端做一次重定向,补齐url里面的东西然后再进行提交
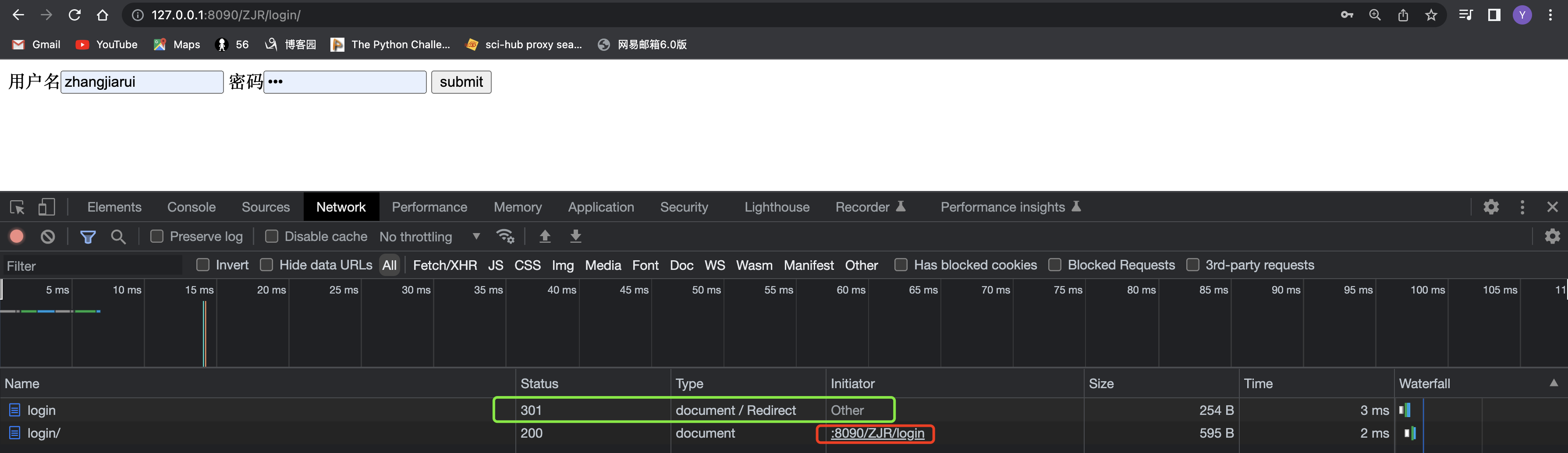
首先下方的红框表示我们第一次访问的路径,没有带/,所以进行了第二次的重定向,但最终得到的效果是一样的。
如果想取消这个自动补全功能,在setting.py里加一句
APPEND_SLASH = False
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:django_响应对象 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 